
Wan2.2 S2V: Sonido a Video desde una Sola Imagen en ComfyUI#
Wan2.2 S2V es un flujo de trabajo de sonido a video que convierte una imagen de referencia más un clip de audio en un video sincronizado. Está construido alrededor de la familia de modelos Wan 2.2 y diseñado para creadores que desean movimiento expresivo, sincronización de labios y dinámicas de escena que sigan el sonido o el habla. Usa Wan2.2 S2V para avatares parlantes, bucles impulsados por música y secuencias rápidas sin animación manual.
Este gráfico de ComfyUI acopla características de audio con indicaciones de texto y una imagen fija para generar un clip corto, luego mezcla los fotogramas con el audio original. El resultado es una canalización compacta y confiable que mantiene el aspecto de tu imagen de referencia mientras permite que el audio impulse el tiempo y la expresión.
Modelos clave en el flujo de trabajo Wan2.2 S2V de ComfyUI#
- Wan 2.2 S2V UNet (14B, bf16). El generador principal que fusiona características de audio, condicionamiento de texto y una imagen de referencia para producir latentes de video.
- Wan VAE (wan_2.1_vae). Codifica/decodifica entre el espacio latente y de píxeles para preservar el detalle y la fidelidad del color en los renders de Wan2.2 S2V.
- UMT5-XXL codificador de texto. Proporciona condicionamiento de indicaciones para estilo y contenido; ve la tarjeta del modelo base para referencia: google/umt5-xxl.
- Codificador de audio Wav2Vec2 Large. Extrae características robustas de habla y ritmo para generación condicionada por sonido; ve una tarjeta arquetípica como facebook/wav2vec2-large-960h.
Cómo usar el flujo de trabajo Wan2.2 S2V de ComfyUI#
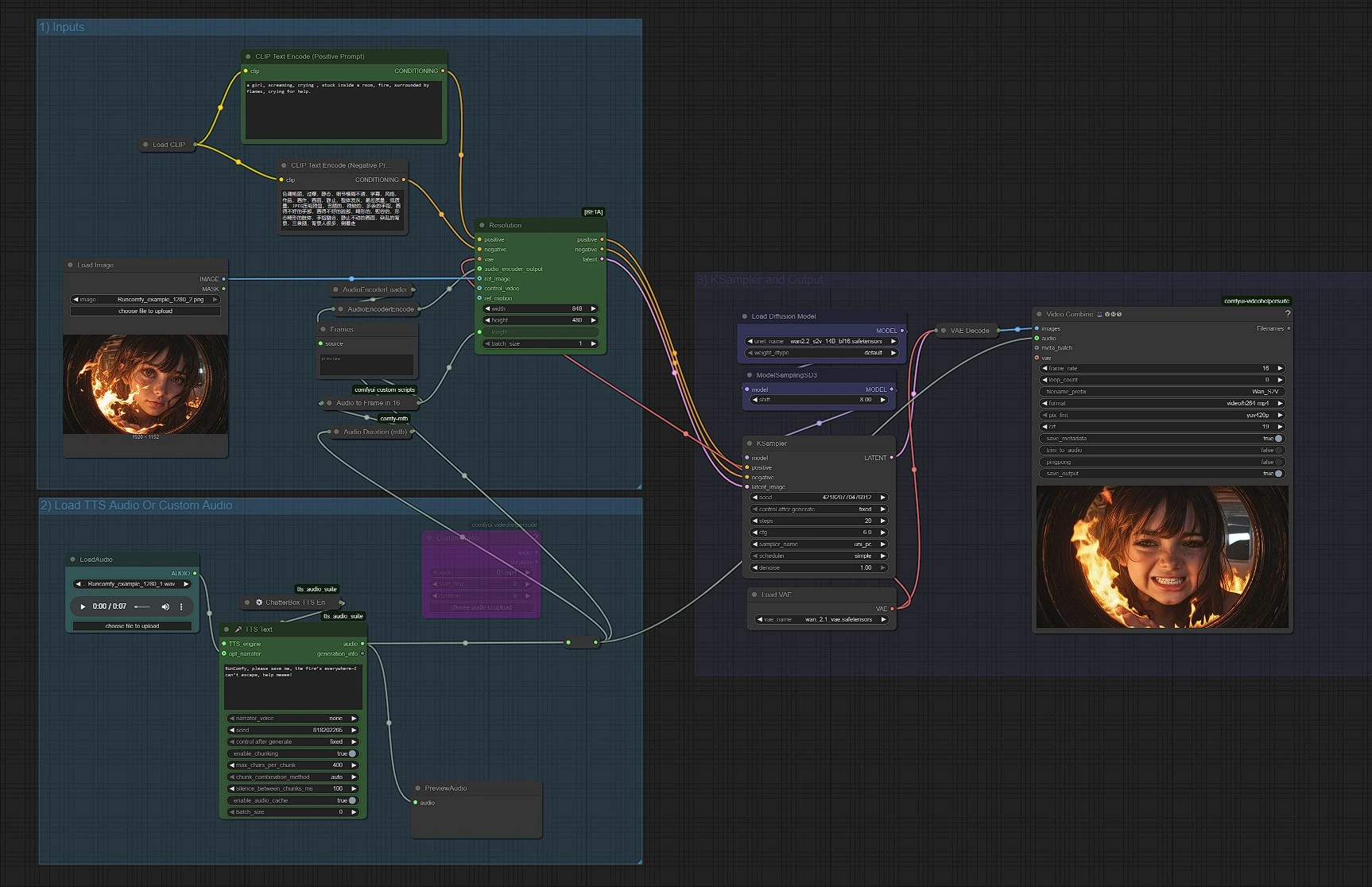
El flujo de trabajo está organizado en tres grupos. Puedes ejecutarlos de principio a fin o ajustar cada etapa según sea necesario.
1) Entradas#
Este grupo carga los componentes de texto, imagen y VAE de Wan, y prepara tus indicaciones. Usa CLIPLoader (#38) con CLIPTextEncode (#6) para la indicación positiva y CLIPTextEncode (#7) para la indicación negativa para guiar el estilo y la calidad. Carga tu imagen de referencia con LoadImage (#52); esto ancla la identidad, el encuadre y la paleta para Wan2.2 S2V. Mantén las indicaciones positivas descriptivas pero breves para que el audio retenga el control sobre el movimiento. El VAE (VAELoader (#39)) y el cargador de modelos (UNETLoader (#37)) están preconfigurados y generalmente se dejan tal cual.
2) Cargar Audio TTS o Audio Personalizado#
Elige cómo proporcionar audio. Para pruebas rápidas, genera habla con UnifiedTTSTextNode (#71) y previsualiza con PreviewAudio (#65). Para usar tu propia música o diálogo, usa LoadAudio (#78) para archivos locales o VHS_LoadAudioUpload (#87) para cargas; ambos alimentan un Reroute (#88) para que los nodos posteriores vean una única fuente de audio. La duración se mide con Audio Duration (mtb) (#68), luego se convierte a un conteo de fotogramas con MathExpression|pysssss (#67) etiquetado “Audio a Fotograma en 16 FPS”. Las características de audio son producidas por AudioEncoderLoader (#57) y AudioEncoderEncode (#56), que juntos suministran el nodo Wan2.2 S2V con un AUDIO_ENCODER_OUTPUT.
3) KSampler y Salida#
WanSoundImageToVideo (#55) es el corazón de Wan2.2 S2V. Consume tus indicaciones, VAE, características de audio, imagen de referencia y un entero length (fotogramas) para emitir una secuencia latente condicionada. Esa latente va a KSampler (#3), cuyas configuraciones del muestreador gobiernan la coherencia general y el detalle mientras respetan el tiempo impulsado por el audio. La latente muestreada es decodificada por VAEDecode (#8) en fotogramas, luego VHS_VideoCombine (#66) ensambla el video y mezcla tu audio original para producir un MP4. ModelSamplingSD3 (#54) se usa para establecer la familia correcta del muestreador para la base de Wan.
Nodos clave en el flujo de trabajo Wan2.2 S2V de ComfyUI#
WanSoundImageToVideo (#55)#
Impulsa el movimiento sincronizado con audio desde una sola imagen. Establece ref_image en el retrato o escena que deseas animar, conecta audio_encoder_output desde el codificador y proporciona una length en fotogramas. Aumenta length para clips más largos o reduce para previsualizaciones más rápidas. Si cambias FPS en otro lugar, actualiza el valor de fotogramas en consecuencia para que el tiempo se mantenga sincronizado.
AudioEncoderLoader (#57) y AudioEncoderEncode (#56)#
Cargan y ejecutan el codificador basado en Wav2Vec2 que convierte el habla o la música en características que Wan puede seguir. Usa habla limpia para sincronización de labios, o audio percusivo/con muchos golpes para movimiento rítmico. Si tu idioma o dominio de entrada difiere, intercambia un punto de control Wav2Vec2 compatible para mejorar la alineación.
CLIPTextEncode (#6) y CLIPTextEncode (#7)#
Codificadores de indicaciones positivas y negativas para el condicionamiento UMT5/CLIP. Mantén las indicaciones positivas concisas, enfocándote en el sujeto, estilo y términos de toma; usa indicaciones negativas para evitar artefactos no deseados. Las indicaciones demasiado contundentes pueden luchar contra el audio, así que prefiere una guía ligera y deja que Wan2.2 S2V maneje el movimiento.
KSampler (#3)#
Muestra la secuencia latente producida por el nodo Wan2.2 S2V. Ajusta el tipo de muestreador y los pasos para intercambiar velocidad por fidelidad; mantén una semilla fija cuando desees un tiempo reproducible con el mismo audio. Si el movimiento se siente demasiado rígido o ruidoso, pequeños cambios aquí pueden mejorar notablemente la estabilidad temporal.
VHS_VideoCombine (#66)#
Crea el video final y adjunta el audio. Establece frame_rate para que coincida con tu FPS previsto y confirma que la longitud del clip coincida con tus fotogramas length. El contenedor, el formato de píxel y los controles de calidad están expuestos para exportaciones rápidas; usa una calidad más alta cuando planeas postprocesar en un editor.
Extras opcionales#
- Comienza con una imagen de referencia bien iluminada y de frente en tu relación de aspecto objetivo para minimizar la deriva de identidad y el recorte.
- Para sincronización de labios, mantén la boca despejada y usa narración limpia; la música con transitorios fuertes funciona bien para movimiento impulsado por el ritmo.
- La conversión de FPS predeterminada asume 16 fps; si cambias FPS, actualiza las matemáticas en “Audio a Fotograma en 16 FPS” para que los fotogramas se alineen con la duración del audio.
- Usa la previsualización de audio y la previsualización en vivo de VHS para iterar rápidamente, luego aumenta la calidad una vez que te guste el tiempo.
- Los clips más largos escalan el cómputo y la VRAM; recorta el silencio o divide guiones largos en escenas cortas al producir videos de varias tomas con Wan2.2 S2V.
Reconocimientos#
Este flujo de trabajo implementa y se basa en los siguientes trabajos y recursos. Agradecemos con gratitud a Wan-Video por Wan2.2 (incluyendo código de inferencia S2V), Wan-AI por Wan2.2-S2V-14B, y Gao et al. (2025) por Wan-S2V: Generación de Video Cinemático Impulsado por Audio por sus contribuciones y mantenimiento. Para detalles autorizados, por favor consulta la documentación original y los repositorios enlazados a continuación.
Recursos#
- Wan-Video/Wan2.2 S2V Demo
- GitHub: Wan-Video/Wan2.2
- Hugging Face: Wan-AI/Wan2.2-S2V-14B
- arXiv: Wan-S2V: Generación de Video Cinemático Impulsado por Audio
- Documentos / Notas de Lanzamiento: Wan2.2 S2V Demo
Nota: El uso de los modelos, conjuntos de datos y código referenciados está sujeto a las respectivas licencias y términos proporcionados por sus autores y mantenedores.