
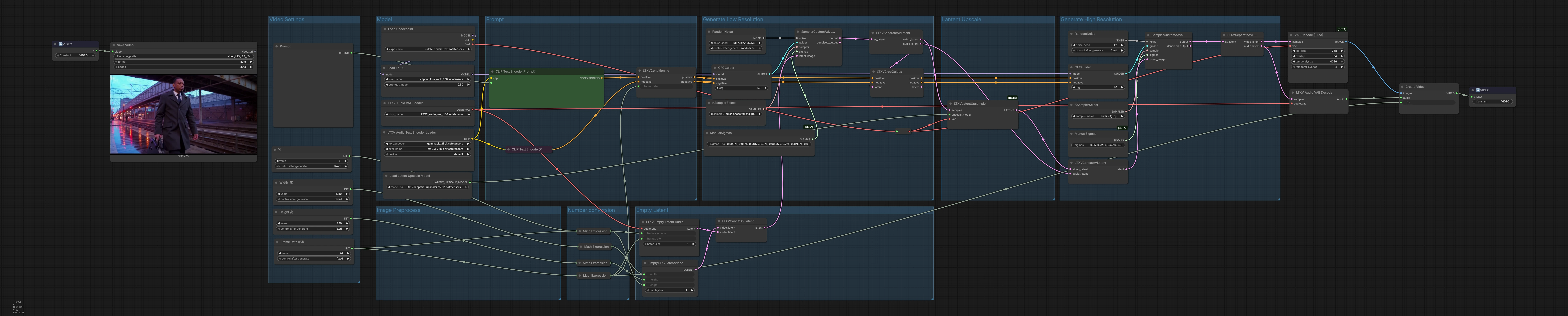
LTX 2.3 Sulphur 2 flujo de trabajo de texto a video para animación de personajes cinematográficos#
Esta tubería de ComfyUI convierte indicaciones de lenguaje natural en videos cortos, cinematográficos y centrados en personajes con audio opcional, construido alrededor de los componentes Lightricks LTX-2.3 y Sulphur 2. Genera en baja resolución para la planificación del movimiento, escala la secuencia latente, luego refina en alta resolución antes de decodificar a fotogramas y mezclar una pista de audio sincronizada.
El flujo de trabajo de texto a video LTX 2.3 Sulphur 2 es ideal para pruebas rápidas de animación de personajes, conceptos de movimiento estilo D-Human y experimentos de texto a video pulidos. No depende de entradas de imagen a video o relés de indicaciones; todo comienza desde el texto, con el condicionamiento LTXV guiando tanto los latentes de video como de audio de principio a fin.
Modelos clave en el flujo de trabajo de texto a video LTX 2.3 Sulphur 2 de Comfyui#
- Lightricks LTX-2.3. Generador de texto a video central utilizado para síntesis espaciotemporal y latentes AV multimodales. Consulta el repositorio oficial del modelo para obtener pesos y notas sobre capacidades y limitaciones. Hugging Face: Lightricks/LTX-2.3
- Punto de control Lightricks LTX-2.3 FP8. Variante eficiente en memoria de LTX-2.3 que acelera la inferencia y permite clips más largos o resoluciones más altas en GPUs con limitaciones. Hugging Face: Lightricks/LTX-2.3-fp8
- Modelo base Sulphur 2. Proporciona priors de estilo y detalle de personajes a través de LoRA en este flujo de trabajo, ayudando a lograr rostros nítidos y tonalidad cinematográfica. Hugging Face: SulphurAI/Sulphur-2-base
- LTX-2.3 Aumentador Espacial x2 1.1. Aumentador de espacio latente que incrementa el detalle espacial antes del paso de refinamiento de alta resolución. Hugging Face: Lightricks/LTX-2.3 file ltx-2.3-spatial-upscaler-x2-1.1.safetensors
- Codificador de texto LTX (Gemma 3 12B IT empaquetado para LTX). Suministra el espacio de incrustación de texto emparejado con el condicionamiento LTX-2.3 para un seguimiento fiel de las indicaciones. Hugging Face: Comfy-Org/ltx-2
- LTX Audio VAE. Decodifica el latente de audio generado junto con el video para que el render final pueda incluir una banda sonora sincronizada. Hugging Face: Lightricks/LTX-2.3
Cómo usar el flujo de trabajo de texto a video LTX 2.3 Sulphur 2 de Comfyui#
Lógica general La tubería se ejecuta en tres actos: generación de baja resolución para establecer movimiento y composición, aumento de latentes para incrementar el detalle espacial, y un paso de refinamiento de alta resolución que también produce el audio final. Los latentes se decodifican en fotogramas y forma de onda, luego se mezclan en un contenedor MP4 listo para entrega.
Configuración de Video Usa el grupo “Configuración de Video” para definir ancho, altura, tasa de fotogramas y duración. El recuento de fotogramas se calcula automáticamente a partir de tu duración y fps para que el tiempo y el ritmo se mantengan consistentes. Estos valores impulsan la asignación y decodificación de latentes, así que configúralos primero para que coincidan con tu relación de aspecto y tiempo de ejecución objetivo. Ajustar fps aquí también informa al condicionamiento para que la suavidad del movimiento y la alineación del audio usen el mismo reloj.
Indicaciones En “Indicaciones,” carga el codificador de texto LTX con LTXAVTextEncoderLoader (#316), luego escribe tu descripción positiva en CLIPTextEncode (#303) y cualquier rasgo no deseado en CLIPTextEncode (#312). El nodo LTXVConditioning (#304) fusiona el condicionamiento positivo y negativo y agrega la tasa de fotogramas elegida para que la guía temporal coincida con tu fps. Trata la indicación positiva como un breve de toma: sujeto, cámara, iluminación, estado de ánimo y estilo. Mantén la lista negativa enfocada en artefactos que veas regularmente y quieras eliminar.
Modelo El grupo “Modelo” carga el punto de control principal a través de CheckpointLoaderSimple (#315) y aplica un LoRA Sulphur 2 con LoraLoaderModelOnly (#285) para infundir textura cinematográfica y fidelidad de personajes. Aquí es donde puedes cambiar puntos de control o LoRAs para cambiar el aspecto general y los priors de movimiento. La salida del modelo se enruta tanto a los guías iniciales como de refinamiento para que el estilo y la identidad sean consistentes en todos los pasos. Emparejar LTX-2.3 con Sulphur 2 produce un contraste contundente y rostros detallados que se leen bien en movimiento.
Conversión de números Las expresiones utilitarias convierten tu fps y segundos en el recuento de fotogramas enteros utilizado aguas abajo. Esto mantiene las líneas de tiempo de audio y video alineadas sin matemáticas manuales. Si revisas fps o duración más tarde, el gráfico actualiza automáticamente los nodos dependientes.
Latente Vacío “Latente Vacío” crea contenedores alineados para la generación: EmptyLTXVLatentVideo (#295) define el tamaño espacial y la longitud del latente de video, LTXVEmptyLatentAudio (#305) asigna el latente de audio a la misma tasa de fotogramas, y LTXVConcatAVLatent (#321) los fusiona en un solo latente AV. Comenzar desde latentes vacíos asegura que el paso de difusión refleje completamente tu indicación y condicionamiento en lugar de cualquier contenido preexistente.
Generar Baja Resolución La primera etapa de muestreo establece movimiento y composición a menor costo. CFGGuider (#313), KSamplerSelect (#291), y ManualSigmas (#306) gobiernan qué tan fuertemente la indicación dirige la generación y el programa de ruido general. SamplerCustomAdvanced (#283) luego desruida el latente AV a un clip coherente. El resultado se divide por LTXVSeparateAVLatent (#307), y LTXVCropGuides (#284) refina la atención espacial para que el encuadre del sujeto que deseas se preserve durante la ampliación posterior.
Ampliación Latente LTXVLatentUpsampler (#287) usa el aumentador x2 LTX-2.3 para elevar el detalle espacial mientras permanece en el espacio latente para velocidad y estabilidad. Alimentar el latente de video ampliado hacia adelante mejora la textura y la legibilidad antes del refinamiento de alta resolución. Esto preserva el movimiento que te gustó del primer paso mientras abre espacio para bordes más nítidos y materiales más ricos.
Generar Alta Resolución El latente de video ampliado se reúne con el latente de audio en LTXVConcatAVLatent (#278) y se guía nuevamente para calidad final. CFGGuider (#282), KSamplerSelect (#280), y ManualSigmas (#281) dan la última palabra sobre la fuerza de la indicación, el detalle y la coherencia temporal, con SamplerCustomAdvanced (#308) produciendo el latente AV refinado. LTXVSeparateAVLatent (#309) entrega el video a VAEDecodeTiled (#314) para decodificación de fotogramas compatible con la memoria y el audio a LTXVAudioVAEDecode (#297) para reconstrucción de forma de onda. CreateVideo (#310) mezcla fotogramas y audio a tu fps objetivo, y SaveVideo (#75) escribe un archivo MP4/H.264.
Preprocesamiento de Imagen Esta área enruta los modelos base VAE y aumentador para que el mosaico y la ampliación latente funcionen dentro de tu presupuesto de VRAM. Si experimentas presión de memoria, favorece los pesos FP8 LTX-2.3 y mantén habilitada la decodificación en mosaico para mantener el rendimiento y la calidad.
Nodos clave en el flujo de trabajo de texto a video LTX 2.3 Sulphur 2 de Comfyui#
LTXVConditioning (#304) Fusiona el condicionamiento de texto positivo y negativo y adjunta la tasa de fotogramas de trabajo para que la guía temporal coincida con tu render. Un lenguaje de escena fuerte y específico mejora la estructura de la toma; negativos concisos reducen los artefactos. Consulta la tarjeta del modelo LTX-2.3 para notas de condicionamiento. Hugging Face: Lightricks/LTX-2.3
LTXVCropGuides (#284) Dirige suavemente la composición para mantener al sujeto principal encuadrado como se pretende. Úsalo para proteger el tamaño del rostro, la colocación del horizonte o un sujeto centrado antes de la ampliación y el refinamiento. Es especialmente útil para tomas estilo diálogo y primeros planos medios.
CFGGuider (#313, #282) Controla qué tan agresivamente la indicación influye en la trayectoria de difusión en ambos pasos. Usa el primer guía para bloquear el movimiento y la puesta en escena, luego el segundo para agregar nitidez sin alejarse de la toma establecida.
ManualSigmas (#306, #281) Define el programa de ruido. Cargar más ruido al principio fomenta una mayor exploración de movimiento; un programa más suave enfatiza la consistencia temporal. Mantén los programas de baja y alta resolución complementarios en lugar de idénticos.
LTXVLatentUpsampler (#287) Realiza una ampliación latente x2 usando el aumentador oficial LTX para que ganes detalle antes del muestreador de refinamiento. Cambiar a otra variante de aumentador LTX-2.3 puede cambiar ligeramente la nitidez y el grano. Hugging Face: Lightricks/LTX-2.3
VAEDecodeTiled (#314) Decodifica clips largos o grandes en mosaicos manejables para evitar picos de VRAM. Si cambias el tamaño espacial o la longitud del clip, ajusta el mosaico para equilibrar el margen de memoria y la velocidad de decodificación.
LoraLoaderModelOnly (#285) Aplica el LoRA Sulphur 2 a la ruta del modelo base para que la fidelidad de los personajes y las pistas de estilo se transfieran a ambas etapas de muestreo. Usa esto para cambiar rápidamente de aspecto manteniendo la misma base LTX-2.3. Hugging Face: SulphurAI/Sulphur-2-base
Extras opcionales#
- Control de semillas: establece valores fijos en ambos nodos
RandomNoisepara que las tomas sean reproducibles; cambia una semilla para explorar alternativas. - Indicaciones: escribe indicaciones como direcciones de toma (sujeto, cámara, iluminación, estado de ánimo). Mantén la lista negativa enfocada y corta.
- Rendimiento: si el VRAM es limitado, prefiere los pesos FP8 LTX-2.3 y mantén habilitada la decodificación en mosaico.
- Salida: el gráfico escribe MP4/H.264; cambia el contenedor o códec en
SaveVideosi necesitas flujos de trabajo de proxy ProRes.
Este flujo de trabajo de texto a video LTX 2.3 Sulphur 2 ofrece un camino limpio y de extremo a extremo desde la indicación hasta el video pulido con audio sincronizado, construido para iteración rápida en animación de personajes cinematográficos.
Agradecimientos#
Este flujo de trabajo implementa y se basa en los siguientes trabajos y recursos. Agradecemos a RunningHub por el Flujo de Trabajo Básico Sulphur2 para Producción de Video, SulphurAI por el modelo Sulphur-2-base, Lightricks por los modelos LTX-2.3 y LTX-2.3-fp8, y Comfy-Org por el codificador de texto LTX-2 por sus contribuciones y mantenimiento. Para detalles autorizados, consulta la documentación original y los repositorios enlazados a continuación.
Recursos#
- RunningHub/Sulphur2 Basic Workflow for Video Production
- Documentos / Notas de Lanzamiento: Sulphur2 Basic Workflow for Video Production
- SulphurAI/Sulphur-2-base
- Hugging Face: SulphurAI/Sulphur-2-base
- Lightricks/LTX-2.3
- GitHub: Lightricks/LTX-2
- Hugging Face: Lightricks/LTX-2.3
- arXiv: LTX-2: Efficient Joint Audio-Visual Foundation Model (2601.03233)
- Lightricks/LTX-2.3-fp8
- GitHub: Lightricks/LTX-2
- Hugging Face: Lightricks/LTX-2.3-fp8
- arXiv: LTX-2: Efficient Joint Audio-Visual Foundation Model (2601.03233)
- Comfy-Org/ltx-2
- Hugging Face: Comfy-Org/ltx-2
Nota: El uso de los modelos, conjuntos de datos y código referenciados está sujeto a las respectivas licencias y términos proporcionados por sus autores y mantenedores.