
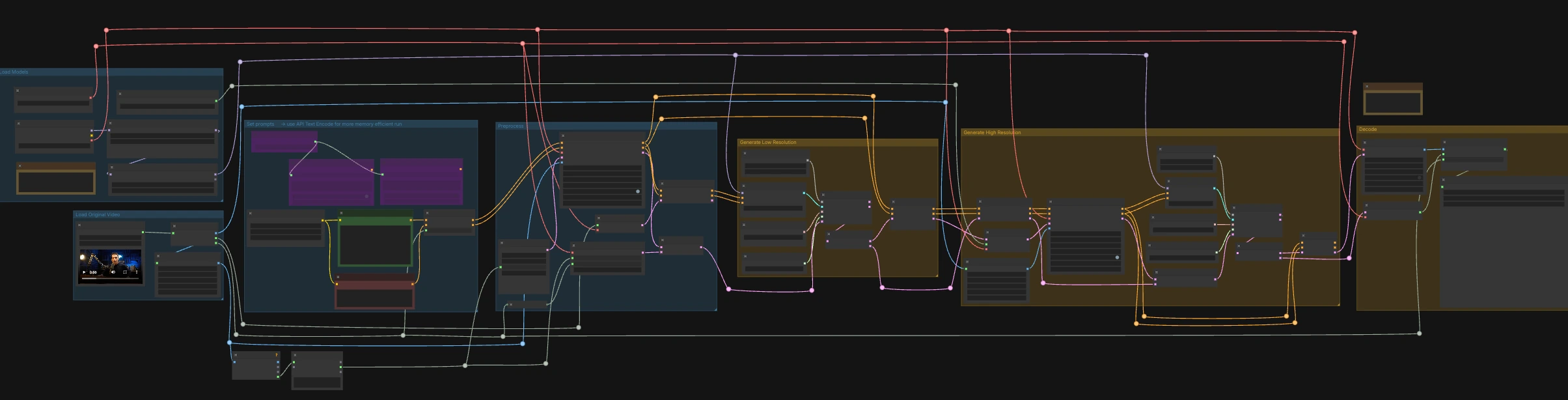
LTX-2.3 ICLoRA LipDub para ComfyUI#
LTX-2.3 ICLoRA LipDub es un flujo de trabajo de ComfyUI controlado por video y audio en dos etapas que dobla a una persona hablando manteniendo la identidad y el movimiento consistentes. Combina el condicionamiento de texto y video LTX-2.3 de Lightricks con el LipDub IC-LoRA para alinear el movimiento de la boca precisamente con el discurso proporcionado, luego refina el resultado a una resolución más alta para obtener detalles nítidos. El gráfico está preparado para RunComfy con nombres de entrada/salida estandarizados para que puedas intercambiar medios y repetir ejecuciones de manera confiable.
Este flujo de trabajo de ComfyUI LTX-2.3 ICLoRA LipDub es ideal para creadores que necesitan doblaje multilingüe, reformulación o correcciones tipo ADR mientras preservan la actuación original. Proporciona un video fuente que ya incluye el discurso objetivo, describe la escena y lo que la persona debe decir, y el flujo de trabajo sintetizará visuales y audio sincronizados en un clip terminado.
Modelos clave en el flujo de trabajo de ComfyUI LTX-2.3 ICLoRA LipDub#
- Modelo de video base LTX-2.3 22B. El modelo de difusión fundamental que genera el video y gobierna cómo los prompts dirigen la apariencia, el movimiento y el estilo.
- LTX-2.3 IC-LoRA LipDub. Un LoRA especializado para doblaje labial que condiciona el modelo para seguir el discurso proporcionado y alinear las formas de la boca con los fonemas mientras preserva la identidad y el movimiento de la cabeza. Model card
- LTX-2.3 Audio VAE. Codifica el discurso de entrada en un latente de audio que puede ser inyectado en el condicionamiento de texto y luego decodificado de nuevo a forma de onda, asegurando que el tiempo permanezca sincronizado con los fotogramas.
- LTX-2.3 Aumentador Espacial x2. Aumenta los latentes de video a una resolución espacial más alta antes del paso de refinamiento de alta resolución, mejorando la textura sin cambiar el movimiento.
- LTX-2.3 LoRA Destilado (384). Un LoRA de refuerzo utilizado junto con el punto de control base para mejorar el detalle y la estabilidad temporal sin sobreajustarse al fotograma de referencia.
Cómo usar el flujo de trabajo de ComfyUI LTX-2.3 ICLoRA LipDub#
Este flujo de trabajo se ejecuta en dos etapas coordinadas: una pasada de baja resolución para bloquear el tiempo y las formas labiales al audio, seguida de una pasada de alta resolución que aumenta y refina el detalle mientras preserva la sincronización. Comienza cargando un video fuente que ya contiene el discurso que deseas, luego escribe la línea de texto que deseas que la persona diga.
Cargar Video Original#
El nodo LoadVideo (#5002) importa tu clip fuente con audio incrustado. GetVideoComponents (#5010) extrae fotogramas, audio y tasa de fotogramas; la tasa de fotogramas se comparte a lo largo del gráfico para que el video y el audio permanezcan alineados. Dos ajustadores de tamaño, Resize Image/Mask (s1 size) (#5009) y Resize Image/Mask (s2 size) (#5003), preparan flujos de imagen de trabajo para las pasadas de baja y alta resolución. La cantidad de fotogramas se mide y redondea para longitudes amigables con el muestreador para que la decodificación permanezca estable.
Cargar Modelos#
CheckpointLoaderSimple (#5017) carga el modelo base LTX-2.3 22B y VAE usado en todo el gráfico. Dos cargadores, LoraLoaderModelOnly (#5018) y LTXICLoRALoaderModelOnly (#5012), añaden el LoRA destilado y el IC-LoRA LipDub sobre la base para que el generador siga el discurso mientras preserva la identidad. LTXVAudioVAELoader (#4010) proporciona el VAE de audio para codificar/decodificar la banda sonora. La salida latent_downscale_factor del cargador IC-LoRA se deja intencionadamente sin usar aquí porque el entrenamiento de LipDub asume fotogramas de referencia de resolución completa, coincidiendo con la nota incluida.
Establecer prompts#
Escribe la descripción de tu escena y la línea hablada exacta en CLIP Text Encode (Positive Prompt) (#2483). Usa CLIP Text Encode (Negative Prompt) (#2612) para minimizar rasgos o artefactos no deseados. Estos alimentan LTXVConditioning (#1241), que adapta el condicionamiento al dominio del video y lleva el contexto de tasa de fotogramas hacia adelante. Para ejecuciones de bajo VRAM, el gráfico también incluye codificadores basados en API (🅛🅣🅧 Gemma API Text Encode - POSITIVE (#4980) y ... - NEGATIVE (#4981)) controlados por la cadena LTX API KEY (#4979); el cableado predeterminado usa codificadores locales.
Preprocesar#
LTXVAudioVAEEncode (#5005) convierte el discurso fuente en un latente de audio, y LTXVSetAudioRefTokens (#5006) inyecta ese latente en el condicionamiento de texto para que el generador “escuche” el tiempo y los fonemas. EmptyLTXVLatentVideo (#3059) prepara un latente de video de marcador de posición con el tamaño espacial correcto y una cantidad de fotogramas alineada con la entrada. LTXAddVideoICLoRAGuide (#5004) adjunta la guía de referencia IC-LoRA usando los fotogramas s1, estableciendo la identidad y la atención en la región de la boca antes de muestrear.
Generar Baja Resolución#
Se forma un bucle de difusión estándar por CFGGuider (#4828), KSamplerSelect (#4831), ManualSigmas (#4984) y SamplerCustomAdvanced (#4829). El muestreador opera sobre un latente de audio+video compuesto por LTXVConcatAVLatent (#4528), asegurando que el condicionamiento de audio participe en cada paso. Después de muestrear, LTXVSeparateAVLatent (#4845) divide el latente para que LTXVSetAudioRefTokens (#5013) pueda congelar la misma representación de discurso para la pasada de alta resolución. Esta etapa bloquea las formas labiales al discurso y establece la línea base del movimiento en tamaño s1.
Generar Alta Resolución#
LTXVLatentUpsampler (#4975) eleva el latente de video usando el Aumentador Espacial x2, preservando el movimiento mientras agrega capacidad para el detalle espacial. LTXAddVideoICLoRAGuide (#5014) reaplica IC-LoRA en tamaño s2 usando los fotogramas de alta resolución para que la pasada refinada preserve la misma identidad del hablante y formas labiales precisas. Un segundo bucle de difusión (CFGGuider (#4964), KSamplerSelect (#4976), ManualSigmas (#4985), SamplerCustomAdvanced (#4971)) refina el latente aumentado mientras LTXVConcatAVLatent (#4969) mantiene el latente de discurso congelado en sintonía. LTXVCropGuides (#5011, #5015) maneja cultivos seguros y guías de región para que la cara permanezca correctamente encuadrada en ambas pasadas.
Decodificar#
LTXVTiledVAEDecode (#4995) convierte el latente de video final en imágenes usando mosaicos para eficiencia de VRAM, y LTXVAudioVAEDecode (#4848) devuelve el audio sincronizado. CreateVideo (#4849) ensambla los fotogramas y el audio a la tasa de fotogramas original, y SaveVideo (#4852) escribe el archivo con el nombre prellenado de RunComfy; cambia este valor para marcar tus salidas. El resultado es un clip LTX-2.3 ICLoRA LipDub completamente sincronizado listo para revisión o entrega.
Nodos clave en el flujo de trabajo de ComfyUI LTX-2.3 ICLoRA LipDub#
LTXICLoRALoaderModelOnly (#5012)#
Carga el LipDub IC-LoRA y lo adjunta al modelo base para que el movimiento labial siga el discurso de entrada sin anular la identidad. Si necesitas un control labial más fuerte o más sutil, ajusta el peso de LoRA aquí; mantenlo coordinado con cualquier LoRA adicional que apliques en la pila para evitar un condicionamiento excesivo.
LTXAddVideoICLoRAGuide (#5004)#
Aplica la guía IC-LoRA en la etapa de baja resolución usando los fotogramas de referencia reducidos. Aquí es donde el flujo de trabajo primero bloquea la identidad y la atención en la región de la boca; úsalo para pruebas A/B activando/desactivando la guía para ver el efecto de la guía de referencia en el tiempo y la articulación.
LTXAddVideoICLoRAGuide (#5014)#
Reaplica la guía IC-LoRA en alta resolución con los fotogramas s2 para que la pasada refinada preserve la misma identidad del hablante y formas labiales precisas. Si cambias el tamaño del fotograma de alta resolución, revisa este nodo para mantener la guía de referencia consistente con tu salida objetivo.
LTXVSetAudioRefTokens (#5006)#
Vincula el discurso codificado a tu condicionamiento de texto para que el muestreador alinee visemas con fonemas. Usa el mismo latente de audio en ambas pasadas para obtener resultados estables; este gráfico lo maneja automáticamente, pero si cambias de audio a mitad de ejecución, debes actualizar tanto el condicionamiento como el latente concatenado.
LTXVLatentUpsampler (#4975)#
Aumenta el latente de video con el Aumentador Espacial x2 de LTX-2.3 para hacer espacio para detalles finos antes del muestreador de alta resolución. Si el VRAM es limitado, combina esto con dimensiones s2 más pequeñas o un mosaico más ligero en el decodificador para equilibrar calidad y rendimiento.
LTXVTiledVAEDecode (#4995)#
Decodifica el latente final a fotogramas usando mosaicos para ajustar grandes salidas en GPUs limitadas. Ajusta el conteo de mosaicos y la superposición aquí para intercambiar velocidad por huella de memoria; menos mosaicos son más rápidos pero requieren más VRAM, mientras que más mosaicos reducen el VRAM a costa de tiempo.
Extras opcionales#
- Prompts para doblaje: incluye las palabras exactas que deseas que se hablen; el modelo no traduce automáticamente. Usa el guion nativo del idioma objetivo, mantén un solo hablante y apunta a una longitud similar a la línea original para que el ritmo sea natural.
- Consejos de rendimiento: si alcanzas los límites de VRAM, reduce el tamaño de s2 en
Resize Image/Mask (s2 size)(#5003) y aumenta el mosaico enLTXVTiledVAEDecode(#4995). Para repetibilidad, mantén las semillas deRandomNoisefijas en ambas pasadas. - Valores predeterminados del flujo de trabajo: el nombre del archivo de entrada de ejemplo está prellenado en
LoadVideo(#5002), y el guardador establece un nombre de salida consistente. Reemplaza ambos para ejecutar múltiples LTX-2.3 ICLoRA LipDub sin sobrescribir resultados. - Encuadre: si la cara se desplaza cerca de los bordes, ajusta
LTXVCropGuides(#5011, #5015) para que la región de la boca permanezca en un cultivo estable en ambas pasadas.
Agradecimientos#
Este flujo de trabajo implementa y se basa en los siguientes trabajos y recursos. Agradecemos a Lightricks por el modelo LTX-2.3-22b-IC-LoRA-LipDub y a RunComfy por el flujo de trabajo compartido de ComfyUI (fuente Cloud Save) por sus contribuciones y mantenimiento. Para detalles autorizados, consulta la documentación original y los repositorios enlazados a continuación.
Recursos#
- Lightricks/LTX-2.3-22b-IC-LoRA-LipDub
- GitHub: Lightricks/LTX-2
- Hugging Face: Lightricks/LTX-2.3-22b-IC-LoRA-LipDub
- arXiv: arXiv:2601.22143
- RunComfy/Cloud Save source
- Docs / Release Notes: RunComfy shared workflow
Nota: El uso de los modelos, conjuntos de datos y código referenciados está sujeto a las respectivas licencias y términos proporcionados por sus autores y mantenedores.
