
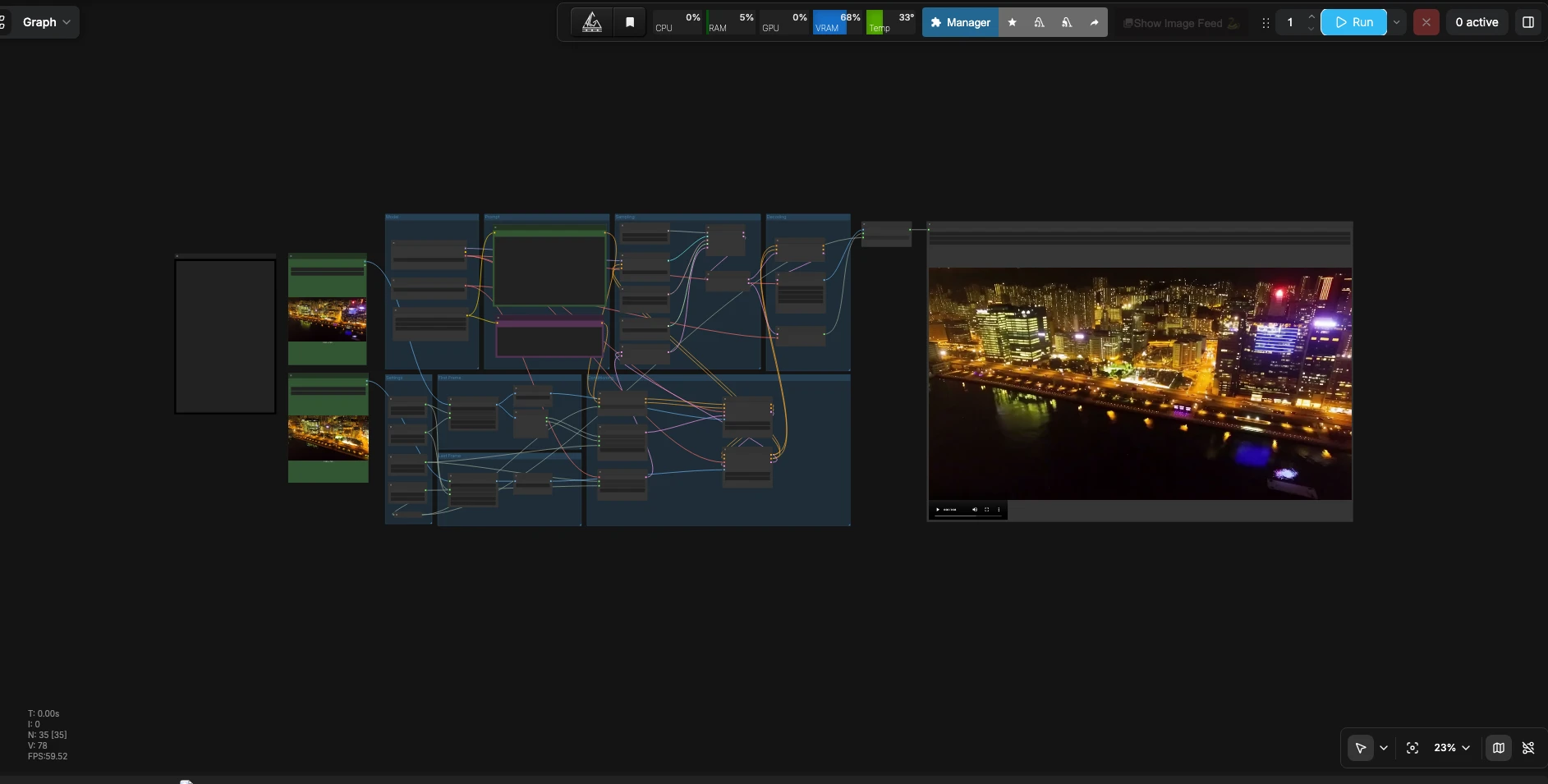
LTX 2.3 First Last Frame a Video#
LTX 2.3 First Last Frame a Video es un flujo de trabajo de ComfyUI que convierte dos imágenes fijas en un video suave y continuo con audio sincronizado. Proporcionas un primer fotograma, un último fotograma y un mensaje en lenguaje natural que describe el movimiento, los detalles de la escena y el sonido. Impulsado por el LTX-2.3 22B distilled FP8 checkpoint, la canalización interpola entre las imágenes manteniendo una apariencia y sincronización consistentes. Es ideal para editores, diseñadores de movimiento y artistas de storyboard que necesitan una transición sin costuras o un clip corto en bucle creado directamente dentro de ComfyUI.
Este flujo de trabajo LTX 2.3 First Last Frame enfatiza la inferencia eficiente y la alta fidelidad del mensaje. Los pesos FP8 mantienen el uso de VRAM bajo control, mientras que un codificador de texto Gemma 3 12B mejora la comprensión semántica de las instrucciones visuales y de audio. El resultado es un pasaje visual coherente del primer al último fotograma que honra tu mensaje y se mantiene sincronizado con el audio generado.
Modelos clave en el flujo de trabajo Comfyui LTX 2.3 First Last Frame#
- LTX-2.3 22B Distilled FP8 checkpoint por Lightricks. Modelo central de generación de video destilado para inferencia eficiente, utilizado aquí para sintetizar fotogramas temporalmente consistentes mientras se condiciona a las dos guías de imagen y el mensaje de texto. Model card
- Gemma 3 12B IT text encoder. Proporciona un entendimiento robusto del lenguaje para ambos aspectos visuales y de audio del mensaje, permitiendo un movimiento preciso, atributos de escena y pistas de banda sonora. Model card
- LTX-2.3 latent VAEs para video y audio. Estos componentes mapean imágenes y audio de forma de onda a latentes compactos y de regreso durante la decodificación, preservando la calidad mientras se mantiene un muestreo eficiente. Incluido con la versión LTX-2.3 FP8. Model card
Cómo usar el flujo de trabajo Comfyui LTX 2.3 First Last Frame#
Este flujo de trabajo toma dos imágenes de referencia y un mensaje, construye el condicionamiento con guías de primer y último fotograma, muestrea un video latente con audio sincronizado y decodifica todo en un archivo reproducible.
Configuración
- Establece tu resolución objetivo, cantidad de fotogramas y tasa de fotogramas en el grupo de Configuración. El ancho y la altura definen el lienzo de trabajo; los fotogramas de entrada se redimensionan para coincidir para que el modelo pueda interpolar limpiamente. La cantidad de fotogramas controla cuánto dura la transición, y la tasa de fotogramas establece la velocidad de reproducción. Elige una relación de aspecto que coincida con tus fuentes para evitar recortes no deseados. Los nodos
WIDTH(#113),HEIGHT(#98),Length(#102) yFrame Rate(int)(#114) anclan estas elecciones.
Primer Fotograma
- Carga tu imagen inicial en
Load First Frame(#31). Se redimensiona medianteResizeImageMaskNode(#124) a las dimensiones objetivo y se normaliza medianteLTXVPreprocess(#104). Esto prepara el primer fotograma para actuar como una guía fuerte de estructura y color al comienzo del clip. Usa una imagen nítida y bien iluminada para obtener los mejores resultados.
Último Fotograma
- Carga tu imagen final en
Load Last Frame(#39). La imagen se adapta al mismo tamaño conResizeImageMaskNode(#125) y se normaliza medianteLTXVPreprocess(#99). Esto asegura el aspecto final y el diseño que deseas al final de la transición. Para bucles, haz que el último fotograma sea visualmente compatible con el primero.
Mensaje
- El
LTXAVTextEncoderLoader(#103) proporciona el codificador de texto, y dos nodosCLIPTextEncodecapturan tus mensajes positivos y negativos. En el mensaje positivo (CLIPTextEncode(#128)), describe el movimiento de la cámara, los sujetos, la iluminación e incluye también pistas de audio como “Music: ambient pads with soft percussion” o “Dialogue: brief whisper.” El mensaje negativo (CLIPTextEncode(#112)) puede enumerar artefactos o rasgos que deseas suprimir.
Condicionamiento
LTXVConditioning(#109) fusiona el condicionamiento de texto con la información de tiempo para que el movimiento y el audio se alineen con tu tasa de fotogramas elegida.EmptyLTXVLatentVideo(#108) crea un video latente en tu resolución y duración. Dos pasadas deLTXVAddGuideprimero adjuntan el primer fotograma (LTXVAddGuide(#115)) y luego el último fotograma (LTXVAddGuide(#111)) para que el modelo sepa dónde comenzar y dónde terminar.LTXVEmptyLatentAudio(#101) inicializa un audio latente de duración coincidente, yLTXVConcatAVLatent(#119) agrupa los latentes de audio y video para el muestreo.
Modelo
CheckpointLoaderSimple(#127) carga los pesos LTX-2.3 22B distilled FP8 y el video VAE, mientras queLTXVAudioVAELoader(#126) proporciona el audio VAE. Estos están preconfigurados para que puedas centrarte en entradas creativas en lugar de detalles de configuración.
Muestreo
CFGGuider(#116) equilibra la adherencia a tu texto y guías de fotograma contra la libertad creativa.RandomNoise(#100) establece una semilla para la reproducibilidad. El muestreador utilizaSamplerEulerAncestral(#117) con un cronograma personalizado deManualSigmas(#118), orquestado porSamplerCustomAdvanced(#120), para refinar progresivamente el latente en una secuencia coherente que sigue tus instrucciones de movimiento y audio.
Decodificación
- Después del muestreo,
LTXVSeparateAVLatent(#121) divide el latente combinado nuevamente en video y audio.LTXVCropGuides(#106) refina la guía espacial para reducir artefactos de borde antes de la decodificación de la imagen.VAEDecodeTiled(#105) produce la secuencia de fotogramas, yLTXVAudioVAEDecode(#107) genera la forma de onda de audio.CreateVideo(#122) mezcla fotogramas y sonido a tu fps seleccionado ySaveVideo(#68) escribe el archivo final en tu salida de ComfyUI.
Nodos clave en el flujo de trabajo Comfyui LTX 2.3 First Last Frame#
EmptyLTXVLatentVideo (#108)
- Define la resolución y duración de trabajo de tu clip. Ajusta el ancho, la altura y la longitud aquí para establecer la escala visual y el tiempo de transición. Las duraciones más largas necesitan pistas de movimiento más fuertes en el mensaje para evitar estancamiento.
LTXVAddGuide (#115)
- Inyecta el primer fotograma como un ancla estructural y de color al inicio de la secuencia. Si la apertura se desvía de tu fuente, aumenta la influencia de esta guía; si se siente demasiado restringido, redúcelo ligeramente para permitir más movimiento.
LTXVAddGuide (#111)
- Ancla el aspecto objetivo al final del clip usando el último fotograma. Si la transición se pasa o nunca llega a tu último fotograma, aumenta la influencia de la guía; si se ajusta demasiado al final, bájala.
CFGGuider (#116)
- Controla cuán fuertemente el modelo sigue el condicionamiento de texto e imagen. Una guía más alta enfatiza tu mensaje y guías, pero puede reducir la suavidad; valores más bajos se sienten más libres, pero pueden desviarse del aspecto deseado. Ajusta en pequeños pasos y reutiliza la misma semilla al comparar.
SamplerCustomAdvanced (#120) con SamplerEulerAncestral (#117) y ManualSigmas (#118)
- Impulsa la eliminación de ruido con un cronograma consistente para un movimiento estable. Cronogramas más cortos renderizan más rápido pero pueden ser bruscos; cronogramas más largos o suaves mejoran la consistencia a un costo computacional adicional. Mantén el cronograma consistente al probar otros parámetros.
CreateVideo (#122)
- Mezcla los fotogramas decodificados y el audio en un clip final a tu tasa de fotogramas elegida. Usa el mismo fps con el que condicionaste para que las formas de labios, pasos o pulsos de música permanezcan alineados.
Extras opcionales#
- Escribe mensajes con verbos y tiempos: “la cámara avanza,” “las luces se atenúan a medida que nos acercamos,” “Música: piano esparcido con reverberación suave.” Los verbos claros ayudan a que la canalización LTX 2.3 First Last Frame infiera movimiento y ritmo.
- Haz coincidir la relación de aspecto y la orientación de tus dos imágenes. Grandes desajustes pueden introducir recortes o estiramientos no deseados.
- Para bucles sin costuras, haz que el último fotograma sea una coincidencia cercana al primero y mantén el movimiento de la cámara cíclico.
- Reutiliza una semilla en
RandomNoisepara reproducir un aspecto mientras iteras sobre mensajes o fortalezas de guía; cambia la semilla para explorar variaciones frescas. - Si necesitas detalles de implementación o referencias de nodos personalizados, consulta las integraciones y utilidades de LTX de ComfyUI como ComfyUI-LTXTricks. Repository
Agradecimientos#
Este flujo de trabajo implementa y se basa en los siguientes trabajos y recursos. Agradecemos a Lightricks por LTX-2.3 22B Distilled FP8 Checkpoint, Google por Gemma 3 12B IT FP4 Text Encoder, logtd por ComfyUI-LTXTricks Custom Nodes y Comfy.org por Comfy.org Official Workflow por sus contribuciones y mantenimiento. Para detalles autorizados, consulta la documentación y repositorios originales enlazados a continuación.
Recursos#
- Lightricks/LTX-2.3 22B Distilled FP8 Checkpoint
- Hugging Face: Lightricks/LTX-2.3-fp8
- Google/Gemma 3 12B IT FP4 Text Encoder
- Hugging Face: google/gemma-3-12b-it
- logtd/ComfyUI-LTXTricks Custom Nodes
- GitHub: logtd/ComfyUI-LTXTricks
- Comfy.org/Comfy.org Official Workflow
- Docs / Release Notes: comfy.org/workflows/video_ltx2_3_flf2v
Nota: El uso de los modelos, conjuntos de datos y código referidos está sujeto a las respectivas licencias y términos proporcionados por sus autores y mantenedores.