
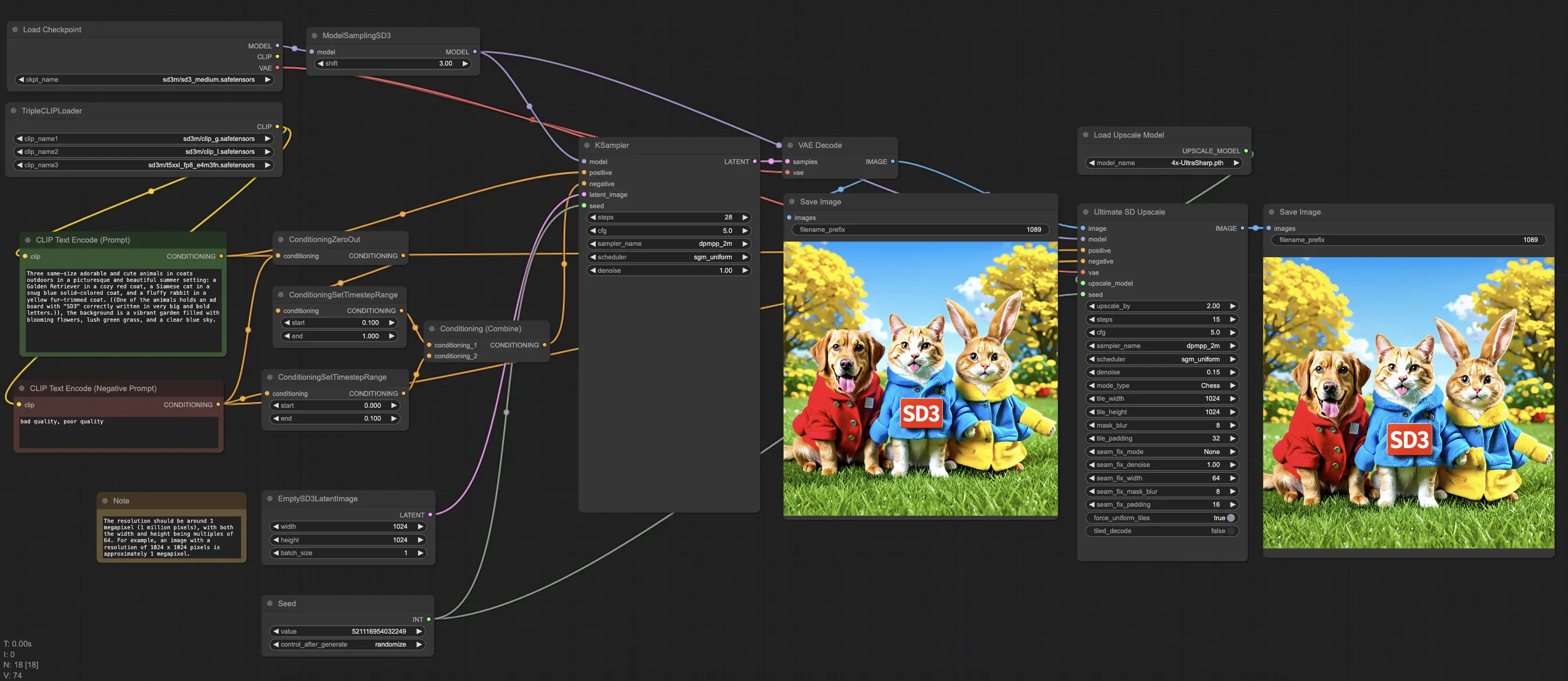



1. Impulsando Tu Proceso Creativo con ComfyUI Stable Diffusion 3#
🌟🌟🌟¡El modelo Stable Diffusion 3 Medium y sus nodos relacionados ahora están precargados en la Versión Beta de ComfyUI de RunComfy (Versión 24.06.13.0)!!!🌟🌟🌟 Puedes usar el Stable Diffusion 3 Medium directamente dentro de este flujo de trabajo de ComfyUI o integrarlo sin problemas en tus flujos de trabajo existentes de ComfyUI.
El flujo de trabajo ComfyUI Stable Diffusion 3 viene con todos los modelos necesarios de Stable Diffusion 3 Medium. ¡Simplemente experimenta con diferentes prompts o parámetros para probarlo!
1.1. Modelos de Stable Diffusion 3 Medium Precargados en ComfyUI#
sd3_medium.safetensors: Incluye los pesos MMDiT y VAE pero no incluye ningún codificador de texto.sd3_medium_incl_clips_t5xxlfp16.safetensors: Contiene todos los pesos necesarios, incluyendo la versión fp16 del codificador de texto T5XXL.sd3_medium_incl_clips_t5xxlfp8.safetensors: Contiene todos los pesos necesarios, incluyendo la versión fp8 del codificador de texto T5XXL, ofreciendo un equilibrio entre calidad y requisitos de recursos.sd3_medium_incl_clips.safetensors: Incluye todos los pesos necesarios excepto el codificador de texto T5XXL. Esta versión requiere recursos mínimos, pero el rendimiento del modelo será diferente sin el codificador de texto T5XXL.- La carpeta
text_encoderscontiene tres codificadores de texto y sus enlaces originales de la tarjeta del modelo para la conveniencia del usuario. Todos los componentes dentro de esta carpeta (y sus equivalentes incrustados en otros paquetes) están sujetos a sus respectivas licencias originales.
1.2 Calidad General y Fotorealismo de Stable Diffusion 3 Medium#
Stable Diffusion 3 Medium establece un nuevo estándar de calidad de imagen en la comunidad de arte AI. Este modelo entrega imágenes con un detalle excepcional, precisión de color y iluminación realista. Esto es lo que puedes esperar:
- Detalle y Resolución: Capacidad mejorada para renderizar detalles intrincados, haciéndolo perfecto para primeros planos y composiciones complejas.
- Color e Iluminación: Algoritmos mejorados aseguran que los colores sean vibrantes y realistas, con efectos de iluminación dinámicos que añaden profundidad y realismo a tus imágenes.
- Realismo en Rostros y Manos: Problemas comunes como manos y rostros distorsionados se reducen significativamente, gracias a innovaciones como el Autoencoder Variacional de 16 canales (VAE).
1.3 Comprensión de Prompts de Stable Diffusion 3 Medium#
Una de las características destacadas de SD3 Medium es su sofisticada comprensión de prompts. Este modelo puede interpretar prompts largos y complejos que involucran razonamiento espacial, elementos compositivos, acciones y estilos. Aquí hay algunos puntos destacados:
- Codificadores de Texto: Utiliza tres codificadores de texto para equilibrar rendimiento y eficiencia. Esto permite una comprensión matizada y ejecución de prompts detallados.
- Conciencia Compositiva: Capaz de mantener relaciones espaciales y representar escenas con precisión según lo descrito, lo que lo hace ideal para contar historias a través de visuales.
1.4 Tipografía de Stable Diffusion 3 Medium#
La tipografía siempre ha sido un desafío en la generación de texto a imagen. SD3 Medium aborda esto con notable éxito:
- Calidad de Texto: Logra una precisión sin precedentes en ortografía, kerning, formación de letras y espaciado.
- Arquitectura de Transformador de Difusión: Esta avanzada arquitectura permite una renderización más precisa del texto dentro de las imágenes, reduciendo errores y mejorando la coherencia visual.
1.5 Eficiencia de Recursos de Stable Diffusion 3 Medium#
A pesar de sus capacidades avanzadas, SD3 Medium está diseñado para ser eficiente en recursos:
- Bajo Uso de VRAM: Puede ejecutarse en GPUs de consumo estándar sin degradación del rendimiento, haciendo que el arte AI de alta calidad sea accesible a una audiencia más amplia.
- Optimizado para la Eficiencia: Equilibra las demandas computacionales con la calidad de salida, asegurando una operación fluida incluso en hardware menos potente.
1.6 Ajuste Fino de Stable Diffusion 3 Medium#
La personalización es un aspecto crítico para los artistas AI, y SD3 Medium sobresale en esta área:
- Absorbiendo Detalles Matizados: Capaz de ajuste fino con conjuntos de datos pequeños, permitiendo a los artistas imprimir su estilo único o cumplir con requisitos específicos del proyecto.
- Versatilidad: Ya sea que trabajes en temas específicos, estilos o detalles intrincados, SD3 Medium proporciona la flexibilidad necesaria para obras de arte personalizadas.
2. ¿Qué es Stable Diffusion 3?#
Stable Diffusion 3 es un modelo AI de vanguardia específicamente diseñado para generar imágenes a partir de prompts. Representa la tercera iteración en la serie Stable Diffusion y tiene como objetivo ofrecer una mayor precisión, mejor adherencia a los matices de los prompts y una estética visual superior en comparación con versiones anteriores y otros modelos como DALL·E 3, Midjourney v6 e Ideogram v1.
3. Modelos de Stable Diffusion 3#
Stable Diffusion 3 ofrece tres modelos distintos, cada uno diseñado para satisfacer diferentes necesidades y capacidades computacionales:
3.1. Stable Diffusion 3 Medium#
🌟🌟🌟 Integrado directamente en este flujo de trabajo 🌟🌟🌟
- Parámetros: 2 mil millones
- Características Clave:
- Imágenes de alta calidad y fotorealistas
- Comprensión avanzada de prompts complejos
- Capacidades superiores de tipografía
- Eficiente en recursos, adecuado para GPUs de consumo
- Excelente para ajuste fino con conjuntos de datos pequeños
3.2. Stable Diffusion 3 Large#
Disponible a través de Stability AI Developer Platform API
- Parámetros: 8 mil millones
- Características Clave:
- Mayor calidad y detalle de imagen
- Mayor capacidad para manejar prompts y estilos complejos
- Ideal para proyectos de grado profesional que requieren alta resolución y fidelidad
3.3. Stable Diffusion 3 Large Turbo#
Disponible a través de Stability AI Developer Platform API
- Parámetros: 8 mil millones (con tiempo de inferencia optimizado)
- Características Clave:
- El mismo alto rendimiento que SD3 Large
- Inferencia más rápida, haciéndolo adecuado para aplicaciones en tiempo real y prototipos rápidos
4. Arquitectura Técnica de Stable Diffusion 3#
En el núcleo de Stable Diffusion 3 se encuentra la arquitectura Multimodal Diffusion Transformer (MMDiT). Este marco innovador mejora cómo el modelo procesa e integra información textual y visual. A diferencia de sus predecesores que utilizaban un solo conjunto de pesos de red neuronal para el procesamiento de imágenes y textos, Stable Diffusion 3 emplea conjuntos de pesos separados para cada modalidad. Esta separación permite un manejo más especializado de los datos de texto e imagen, llevando a una mejor comprensión del texto y precisión en la ortografía en las imágenes generadas.
4.1 Componentes de la Arquitectura MMDiT#
- Embebedores de Texto: Stable Diffusion 3 utiliza una combinación de tres modelos de embebido de texto, incluyendo dos modelos CLIP y T5, para convertir el texto en un formato que la AI pueda entender y procesar.
- Codificador de Imagen: Un modelo de auto-codificación mejorado se utiliza para convertir imágenes en una forma adecuada para que la AI manipule y genere nuevo contenido visual.
- Enfoque Dual de Transformadores: La arquitectura cuenta con dos transformadores distintos para texto e imágenes, que operan independientemente pero están interconectados para operaciones de atención. Esta configuración permite que ambas modalidades se influyan directamente entre sí, mejorando la coherencia entre la entrada de texto y la salida de imagen.
5. ¿Qué Hay de Nuevo y Mejorado en Stable Diffusion 3?#
- Adherencia a los Prompts: SD3 sobresale en seguir de cerca las especificaciones de los prompts de los usuarios, particularmente aquellos que involucran escenas complejas o múltiples sujetos. Esta precisión en la comprensión y representación de prompts detallados le permite superar a otros modelos líderes como DALL·E 3, Midjourney v6 e Ideogram v1, haciéndolo altamente confiable para proyectos que requieren una estricta adherencia a las instrucciones dadas.
- Texto en Imágenes: Con su avanzada arquitectura Multimodal Diffusion Transformer (MMDiT), SD3 mejora significativamente la claridad y legibilidad del texto dentro de las imágenes. Al emplear conjuntos de pesos separados para procesar datos de imagen y lenguaje, el modelo logra una mejor comprensión del texto y precisión en la ortografía. Esta es una mejora sustancial sobre las versiones anteriores de Stable Diffusion, abordando uno de los desafíos comunes en las aplicaciones de AI de texto a imagen.
- Calidad Visual: SD3 no solo iguala sino que en muchos casos supera la calidad visual de las imágenes generadas por sus competidores. Las imágenes producidas no solo son estéticamente agradables sino que también mantienen una alta fidelidad a los prompts, gracias a la capacidad refinada del modelo para interpretar y visualizar descripciones textuales. Esto hace de SD3 una elección superior para los usuarios que buscan una estética visual excepcional en sus imágenes generadas.

Para obtener información detallada sobre el modelo, visita el artículo de investigación de Stable Diffusion 3, Github








