
LatentSync es un marco de sincronización de labios de última generación de extremo a extremo que aprovecha el poder de los modelos de difusión latente condicionados por audio para la generación realista de sincronización de labios. Lo que distingue a LatentSync es su capacidad para modelar directamente las correlaciones intrincadas entre los componentes de audio y visuales sin depender de ninguna representación de movimiento intermedia, revolucionando el enfoque de la síntesis de sincronización de labios.
En el núcleo del flujo de trabajo de LatentSync está la integración de Stable Diffusion, un modelo generativo poderoso reconocido por su capacidad excepcional para capturar y generar imágenes de alta calidad. Al aprovechar las capacidades de Stable Diffusion, LatentSync puede aprender y reproducir eficazmente las dinámicas complejas entre el audio del habla y los movimientos de labios correspondientes, resultando en animaciones de sincronización de labios altamente precisas y convincentes.
Uno de los principales desafíos en los métodos de sincronización de labios basados en difusión es mantener la consistencia temporal a través de los fotogramas generados, lo cual es crucial para obtener resultados realistas. LatentSync aborda este problema de frente con su innovador módulo de Alineación de REPresentación Temporal (TREPA), diseñado específicamente para mejorar la coherencia temporal de las animaciones de sincronización de labios. TREPA emplea técnicas avanzadas para extraer representaciones temporales de los fotogramas generados utilizando modelos de video auto-supervisados de gran escala. Al alinear estas representaciones con los fotogramas de verdad de suelo, el marco de LatentSync asegura un alto grado de coherencia temporal, resultando en animaciones de sincronización de labios notablemente fluidas y convincentes que coinciden estrechamente con la entrada de audio.
1.1 ¿Cómo Usar el Flujo de Trabajo de LatentSync?#
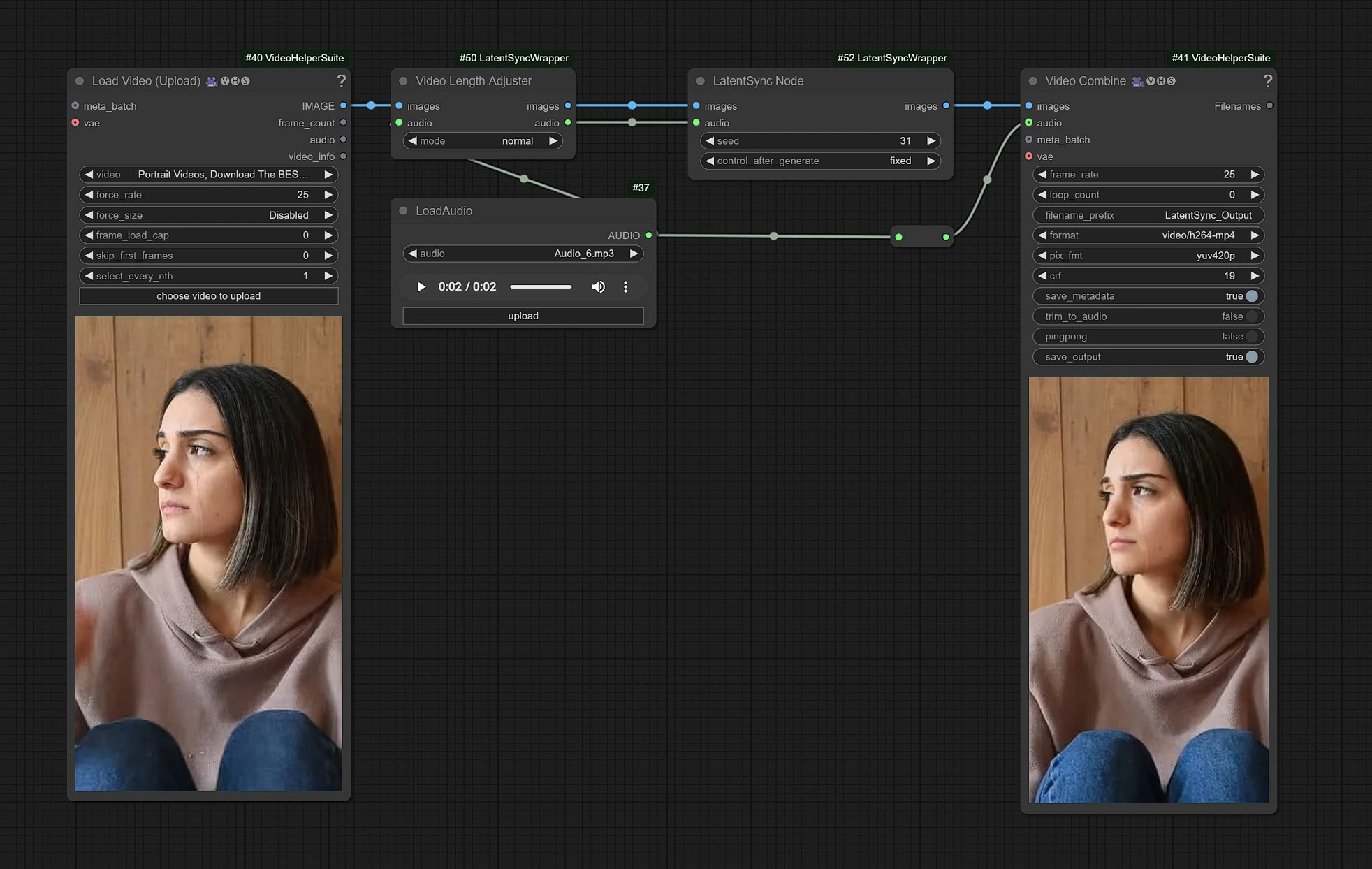
Este es el flujo de trabajo de LatentSync, los nodos del lado izquierdo son entradas para cargar video, el medio es el procesamiento de nodos de LatentSync, y a la derecha está el nodo de salidas.
- Carga tu Video en los nodos de entrada.
- Carga tu entrada de Audio de diálogos.
- ¡Haz clic en Renderizar!
1.2 Entrada de Video#
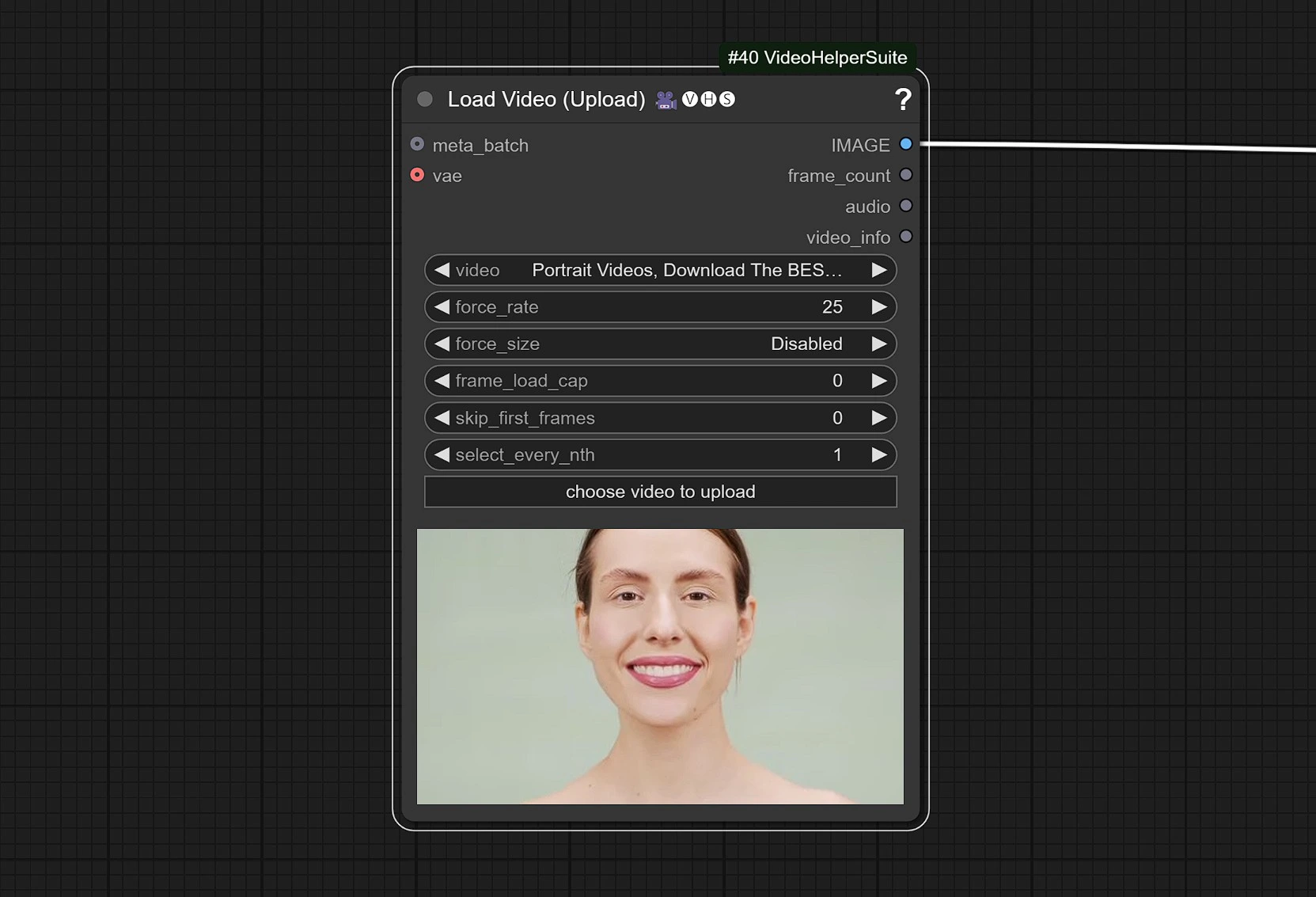
- Haz clic y carga tu Video de Referencia que tenga un rostro en él.
El video se ajusta a 25 FPS para sincronizarse correctamente con el modelo de Audio
1.3 Entrada de Audio#
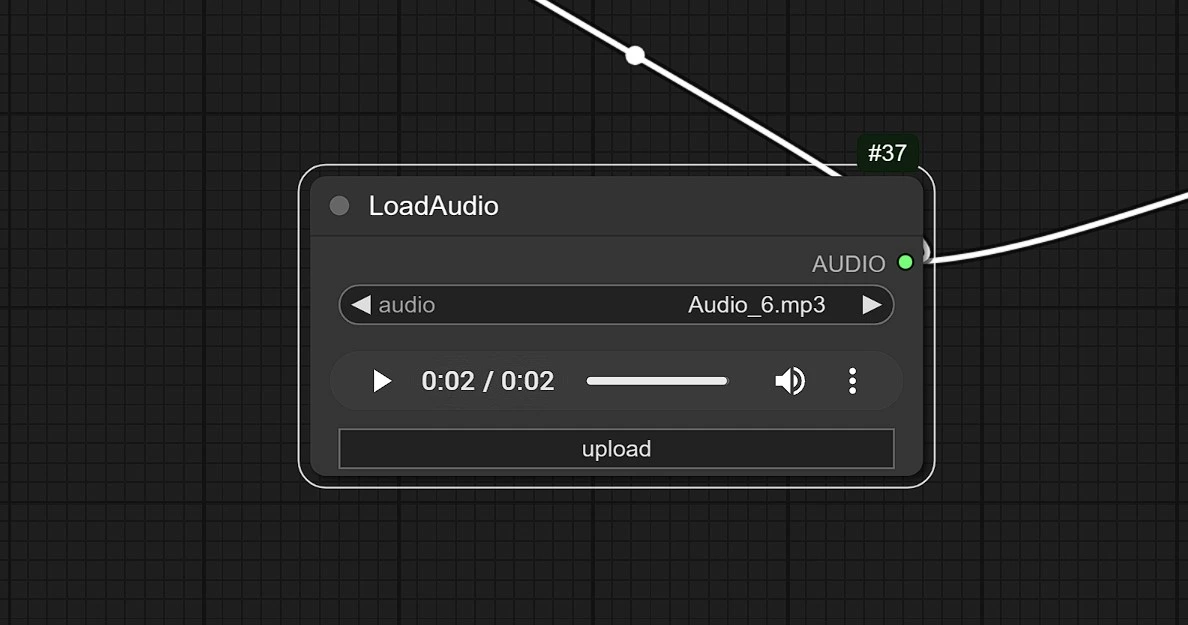
- Haz clic y carga tu audio aquí.
LatentSync establece un nuevo estándar para la sincronización de labios con su enfoque innovador para la generación audio-visual. Combinando precisión, consistencia temporal y el poder de Stable Diffusion, LatentSync transforma la forma en que creamos contenido sincronizado. Redefine lo que es posible en la sincronización de labios con LatentSync.
