
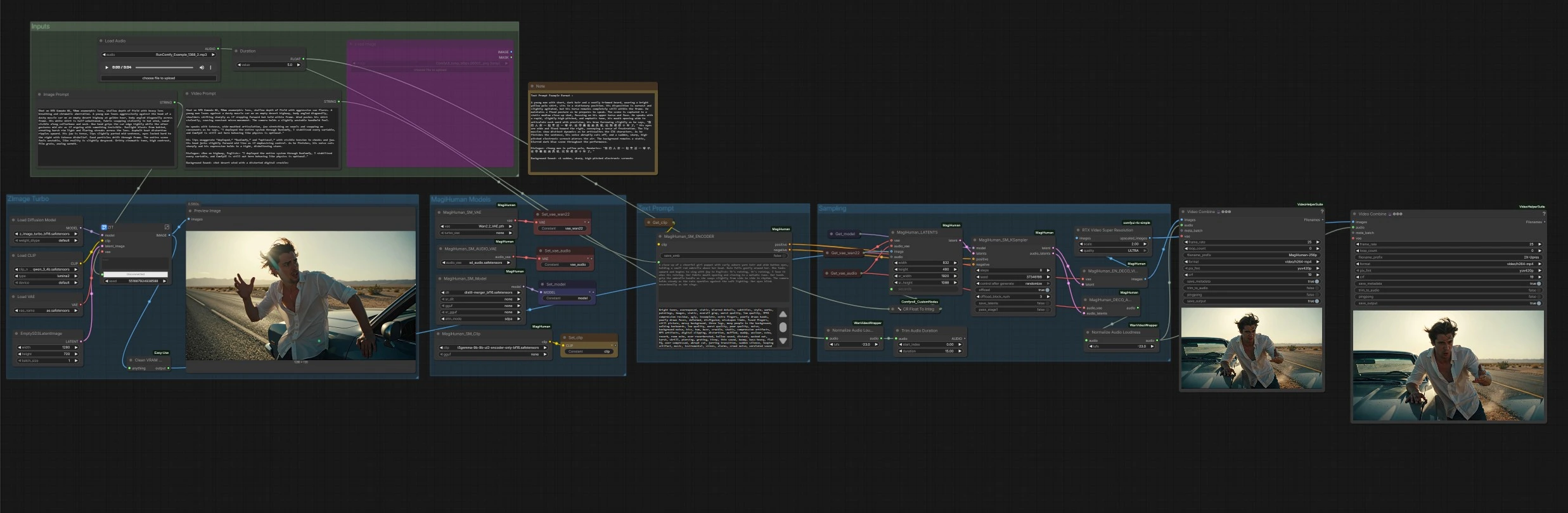
Flujo de trabajo de humano digital parlante de daVinci-MagiHuman para ComfyUI#
Este flujo de trabajo de ComfyUI construye una canalización completa de texto a video alrededor de daVinci-MagiHuman para generar humanos digitales parlantes realistas con habla sincronizada, movimiento labial, expresión y micro-movimiento corporal. Está diseñado para creadores que desean un camino rápido de un solo clic desde una indicación descriptiva a un MP4 con audio limpio. El gráfico puede animar un retrato recién generado o cualquier imagen de referencia suministrada, luego renderiza video y habla juntos, finalizando con una mejora opcional y normalización automática de la sonoridad del audio.
El núcleo de daVinci-MagiHuman utiliza un Transformer de flujo único para co-generar video y audio desde una sola indicación, lo que ayuda a preservar la sincronización y la fidelidad labial incluso en clips cortos. Esta implementación de ComfyUI mantiene los controles simples: escribe una Indicación de Imagen para definir el aspecto, una Indicación de Video para definir el rendimiento y el diálogo, establece la Duración del clip y ejecuta.
Modelos clave en el flujo de trabajo de ComfyUI daVinci-MagiHuman#
- daVinci-MagiHuman (generador de audio-video de flujo único de 15B). Rol: produce conjuntamente fotogramas de video y habla desde texto mientras mantiene la consistencia temporal y la sincronización labial. Referencias: GitHub, arXiv, Hugging Face.
- T5Gemma 9B codificador (adaptado a UL2). Rol: codifica la Indicación de Video en un acondicionamiento rico que dirige el movimiento, la entrega y el estilo para daVinci-MagiHuman. Referencia: Hugging Face.
- Modelo de difusión Z-Image Turbo. Rol: genera rápidamente un retrato fijo de alta calidad desde la Indicación de Imagen para usar como identidad/referencia para la animación. Referencias: Hugging Face (z_image_turbo), Hugging Face (z_image).
- Codificador de texto Qwen 3 4B para Z-Image Turbo. Rol: analiza la Indicación de Imagen para guiar la generación del retrato. Referencia: Archivo de Hugging Face.
- Wan 2.2 VAE. Rol: decodifica latentes de video de MagiHuman a fotogramas RGB con fuerte consistencia temporal. Referencias: GitHub, Modelo de ejemplo de Hugging Face.
- Audio VAE (sd_audio). Rol: decodifica latentes de audio de MagiHuman a una forma de onda de habla para emparejar con el video final. Referencia: paquete de nodos personalizado para MagiHuman GitHub.
- RTX Video Super Resolution (opcional). Rol: mejora post-codificación de fotogramas decodificados para aumentar la nitidez percibida y reducir artefactos de compresión antes de la codificación final. Referencia: envoltorio de ComfyUI GitHub.
Cómo usar el flujo de trabajo de ComfyUI daVinci-MagiHuman#
Flujo general: el grupo Z-Image Turbo crea un retrato de identidad desde tu Indicación de Imagen. El grupo de Modelos MagiHuman carga el punto de control daVinci-MagiHuman, VAE de video y VAE de audio, y prepara el codificador de texto. El grupo de Indicación de Texto convierte tu Indicación de Video en acondicionamiento. El grupo de Muestreo fusiona la imagen de referencia y la indicación en latentes conjuntos de video y audio, luego decodifica ambos. Finalmente, la etapa de Salidas combina los fotogramas con audio en MP4, con una versión mejorada opcional.
Entradas#
Usa las cajas de texto de Indicación de Imagen e Indicación de Video para describir el aspecto y el rendimiento. El control de Duración establece la longitud del clip en segundos. Hay un cargador de audio para conveniencia si planeas experimentar con variantes impulsadas por audio, pero esta plantilla se ejecuta en modo impulsado por texto por defecto.
ZImage Turbo#
Esta etapa renderiza un retrato de referencia único desde la Indicación de Imagen usando el UNet Z-Image Turbo con el codificador de texto Qwen 3 4B y su VAE incluido. Está optimizado para generación de identidad rápida y limpia con apariencia cinematográfica. El resultado se previsualiza, luego se envía como la imagen de referencia para la animación. Si ya tienes una foto de cabeza, puedes omitir esto conectando tu imagen directamente a la etapa de animación.
Modelos MagiHuman#
Aquí el gráfico carga el punto de control base o destilado de daVinci-MagiHuman junto con el VAE de video Wan 2.2, el VAE de audio y el codificador T5Gemma. Esto mantiene la codificación de texto, los latentes de video y los latentes de audio alineados para el muestreo de flujo único. Puedes cambiar pesos si tienes alternativas disponibles en tu entorno.
Indicación de Texto#
Tu Indicación de Video se codifica en acondicionamiento positivo y negativo. El texto positivo debe describir la distancia de la cámara, la pose, el idioma, el estilo de entrega y el contenido exacto del diálogo. El texto negativo puede listar defectos visuales o de audio para evitar. El codificador alimenta ambos conjuntos de acondicionamiento en el muestreador para dar forma al movimiento, dinámica labial y timbre.
Muestreo#
El muestreador construye una secuencia latente inicial desde la imagen de referencia y la Duración solicitada, luego realiza desruido con daVinci-MagiHuman para producir latentes de video y audio sincronizados. Una utilidad convierte la Duración a segundos completos para una programación estable. Cuando el muestreo se completa, los latentes de video van al decodificador de video y los latentes de audio van al decodificador de audio.
Decodificación, sonoridad y exportación#
Los latentes de video se decodifican con el VAE Wan 2.2 a fotogramas de imagen. Los latentes de audio se decodifican a habla, luego se normalizan a una sonoridad adecuada para que el MP4 final se reproduzca de manera consistente en todos los dispositivos. Se producen dos exportaciones: un render básico y un render mejorado opcional usando RTX Video Super Resolution. Ambos se combinan a MP4 con audio y se guardan con prefijos de nombre de archivo claros.
Nodos clave en el flujo de trabajo de ComfyUI daVinci-MagiHuman#
MagiHuman_LATENTS(#13)
Construye el lienzo latente conjunto para video y audio opcional, tomando la imagen de referencia y la longitud del clip. Ajusta seconds para establecer la duración y asegúrate de que tu imagen de referencia esté bien encuadrada para el movimiento que describes. Una resolución base más alta ayuda a la fidelidad facial pero también aumenta el VRAM y el tiempo de decodificación.
MagiHuman_SM_ENCODER(#95)
Codifica la Indicación de Video en acondicionamiento positivo y negativo para el muestreador. Pon la línea hablada exacta entre comillas y nombra el idioma para mejorar el cierre labial y la sincronización. Usa el campo negativo para suprimir artefactos como "subtítulos," "estático," o "eco de sala."
MagiHuman_SM_KSampler(#9)
Ejecuta el desruido de daVinci-MagiHuman para co-generar latentes de video y habla. La seed controla la reproducibilidad, mientras que steps y el cronograma interno intercambian velocidad por detalle y estabilidad de movimiento. Para variación sin perder identidad, cambia seed o reformula ligeramente la parte de rendimiento de tu indicación.
MagiHuman_EN_DECO_VIDEO(#5)
Decodifica latentes de video con el VAE Wan 2.2 a fotogramas RGB para exportación o mejora. Usa este camino para el renderizado más rápido de extremo a extremo; los clips largos o las resoluciones más altas aumentarán linealmente el tiempo de decodificación.
MagiHuman_DECO_AUDIO(#6)
Decodifica latentes de audio a forma de onda y los envía a través de normalización de sonoridad para una reproducción uniforme. Si luego cambias a generación impulsada por audio, dirige tu audio externo al constructor de latentes y mantén este camino de decodificación para la combinación final.
RTXVideoSuperResolution(#93)
Mejorador post-codificación opcional que afila bordes y reduce el efecto de anillo. Usa una fuerza moderada para mejorar la claridad sin introducir destellos temporales.
Extras opcionales#
- Patrón de indicación para sincronización labial confiable: incluye una etiqueta de hablante y el idioma más una línea entre comillas, por ejemplo Diálogo: <Presentador, Inglés>: "Bienvenidos al espectáculo." Agrega una breve nota sobre la entrega, el tamaño de la toma y la estabilidad de la cámara.
- Mantén el retrato de referencia como un plano medio cercano con la cabeza completamente dentro del marco. Los recortes ajustados dejan poco espacio para la dinámica de mandíbula y mejillas.
- Si necesitas una sincronización más estricta, recorta o extiende tu guion para que coincida con la Duración elegida. Las oraciones muy largas en clips muy cortos pueden forzar una articulación antinatural.
- Esta plantilla se ejecuta en modo solo indicación. Para pruebas impulsadas por audio, conecta un archivo de audio externo a la entrada de audio en
MagiHuman_LATENTS(#13) y ajusta tu Indicación de Video para describir la expresión en lugar del contenido hablado.
Agradecimientos#
Este flujo de trabajo implementa y se basa en los siguientes trabajos y recursos. Agradecemos profundamente a daVinci-MagiHuman por el Fuente del Flujo de Trabajo de daVinci-MagiHuman por sus contribuciones y mantenimiento. Para detalles autorizados, por favor refiérase a la documentación y repositorios originales enlazados a continuación.
Recursos#
- daVinci-MagiHuman/Fuente del Flujo de Trabajo
- Documentos / Notas de Lanzamiento: Fuente del Flujo de Trabajo de daVinci-MagiHuman
Nota: El uso de los modelos, conjuntos de datos y código referenciado está sujeto a las licencias y términos respectivos proporcionados por sus autores y mantenedores.
