
ComfyUI MOSS TTS: texto a voz, clonación de voz, SFX y diálogo en un solo flujo de trabajo#
Este flujo de trabajo ComfyUI MOSS TTS convierte texto en discurso vívido de 24 kHz usando la familia OpenMOSS MOSS-TTS. Cubre síntesis rápida de un solo hablante, clonación de voz de cero disparos a partir de un clip de referencia corto, diseño de voz descriptivo, efectos de sonido procedimentales y diálogo de múltiples hablantes con referencias opcionales por hablante.
Construido sobre la pila de nodos oficial de MOSS-TTS y la familia de modelos, equilibra velocidad y calidad. La ruta Local 1.7B es el carril rápido práctico en una sola GPU, mientras que los modelos más grandes Delay 8B intercambian velocidad por mayor capacidad y expresividad. Si necesitas mensajes reutilizables, voces clonadas o diálogo dentro de ComfyUI, este flujo de trabajo ComfyUI MOSS TTS está diseñado para ti.
Modelos clave en el flujo de trabajo ComfyUI MOSS TTS#
- OpenMOSS MOSS-TTS Local 1.7B. Transformador de texto a voz amigable con una sola GPU que ofrece discurso rápido y natural de 24 kHz para trabajos de producción diaria. Tarjeta del modelo: MOSS-TTS-Local-Transformer.
- OpenMOSS MOSS-TTS Delay 8B. Una línea de modelos más grande que enfatiza la calidad, la similitud de hablantes, y la prosodia a costa de la velocidad y la memoria. Tarjeta del modelo: MOSS-TTS.
- MOSS Audio Tokenizer. El codec aprendido que conecta formas de onda y tokens discretos para los modelos MOSS-TTS, permitiendo decodificación de alta fidelidad. Tarjeta del modelo: MOSS-Audio-Tokenizer.
Para detalles de implementación y actualizaciones, consulta los repositorios oficiales: OpenMOSS/MOSS-TTS y la pila de nodos que potencia este flujo de trabajo richservo/comfyui-moss-tts.
Cómo usar el flujo de trabajo ComfyUI MOSS TTS#
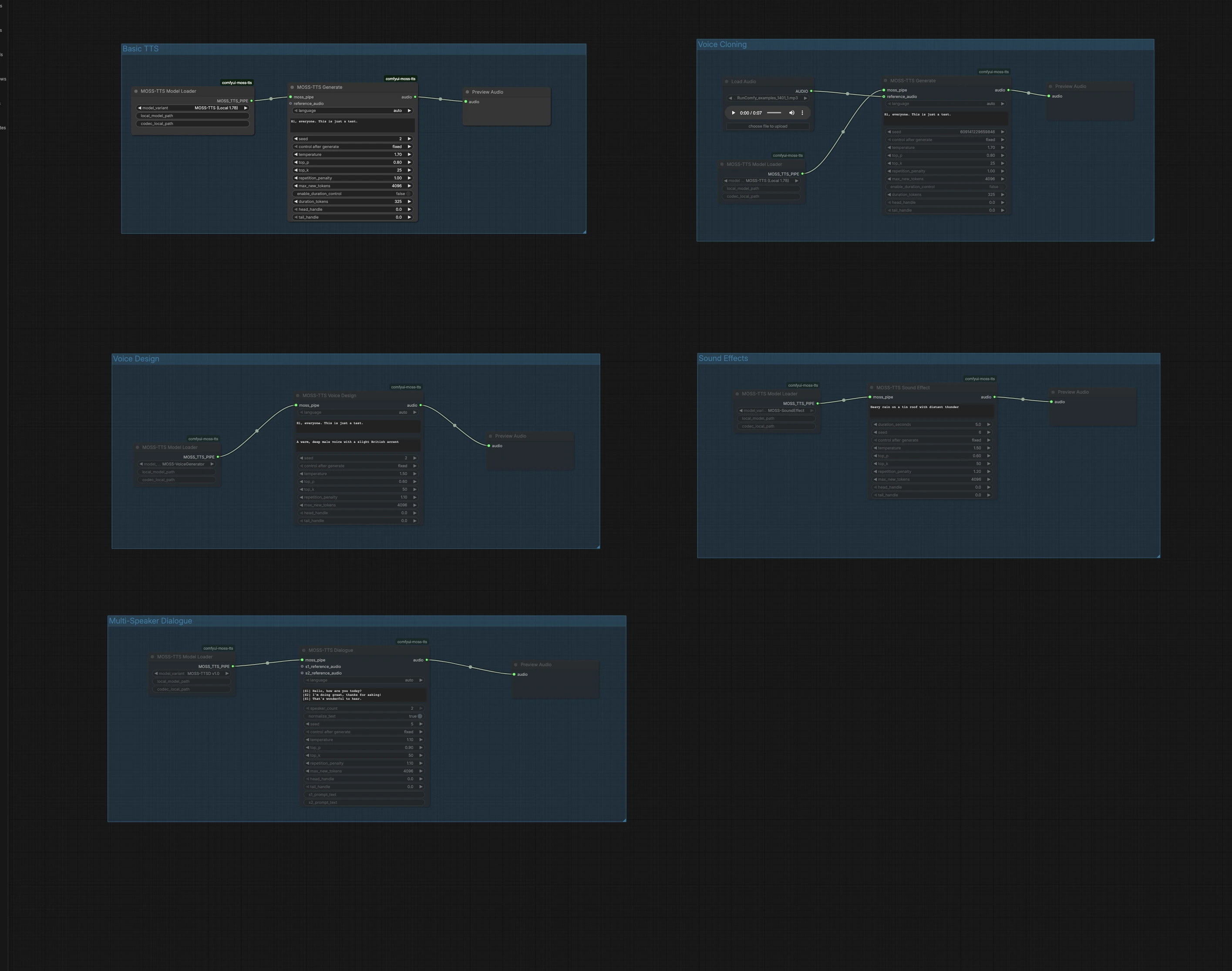
Este gráfico está organizado en cinco grupos independientes. Elige el grupo que coincida con tu objetivo, ejecútalo, luego previsualiza el audio directamente en el lienzo. Puedes ejecutar múltiples grupos en paralelo para probar diferentes enfoques.
TTS Básico#
El grupo TTS Básico convierte texto simple en discurso con la ruta rápida Local 1.7B. Carga el modelo en MossTTSModelLoader (#1), alimenta tu texto a MossTTSGenerate (#2), luego escucha en PreviewAudio (#3). El generador se condiciona con tu mensaje para dar forma a la pronunciación y prosodia, así que escribe naturalmente con puntuación para el ritmo. Mantén la semilla fija cuando quieras tomas repetibles, o aleatorízala al explorar variantes de entrega.
Clonación de Voz#
El grupo Clonación de Voz realiza clonación de voz de cero disparos a partir de un clip de audio de referencia corto. Importa una muestra de voz limpia usando LoadAudio (#4), conéctala a MossTTSGenerate (#6) impulsado por MossTTSModelLoader (#5), y proporciona el texto objetivo. El modelo extrae el timbre y estilo del hablante de la referencia y representa tu nuevo guion en esa voz. Usa contenido neutral y ruido de fondo mínimo en la referencia para mejorar la similitud, y mantén las duraciones moderadas para una respuesta más rápida.
Diseño de Voz#
El Diseño de Voz crea una nueva voz a partir de una descripción en lenguaje natural en lugar de un clip de ejemplo. MossTTSVoiceDesign (#9) utiliza una descripción de texto como "Una voz masculina cálida y profunda con un ligero acento británico," combinada con tu guion, para sintetizar discurso de 24 kHz. El nodo está potenciado por una ruta generadora de voz dedicada cargada a través de MossTTSModelLoader (#8). Esto es ideal cuando deseas una personalidad consistente y reproducible sin necesidad de grabaciones reales. Refina los descriptores con rasgos como edad, timbre, acento y energía para dirigir el sonido.
Efectos de Sonido#
Efectos de Sonido genera audio no verbal a partir de mensajes de texto, útil para pistas de fondo, transiciones o capas ambientales. Con MossTTSSoundEffect (#12) y su tubería de modelo de MossTTSModelLoader (#11), mensajes como "Lluvia fuerte sobre un techo de hojalata con truenos distantes" producen texturas ricas y repetibles. Usa sustantivos y acciones concisas para definir la escena, luego añade algunos adjetivos para precisar la intensidad o distancia. Previsualiza en PreviewAudio (#13) y itera rápidamente para ajustar a tu mezcla.
Diálogo de Múltiples Hablantes#
El grupo Diálogo de Múltiples Hablantes representa conversaciones guionizadas con clips de referencia opcionales por hablante. Escribe tu guion usando etiquetas de hablantes entre corchetes, por ejemplo, [S1] Hola. y [S2] ¡Hola!, luego pásalo a MossTTSDialogue (#15) bajo la tubería de modelo de MossTTSModelLoader (#14). Puedes adjuntar entradas de audio de referencia para S1 y S2 para clonar voces específicas para cada papel, o dejarlas vacías para que el modelo elija hablantes distintos solo a partir del contexto del texto. Este camino es adecuado para llamadas y respuestas, narración con líneas de personajes, o maquetas de interfaces de voz.
Nodos clave en el flujo de trabajo ComfyUI MOSS TTS#
MossTTSModelLoader (#1)#
Carga la familia de modelos OpenMOSS seleccionada y ensambla la tubería interna de TTS. Elige la variante Local 1.7B para iteraciones rápidas en una sola GPU, o cambia a un modelo más grande Delay 8B cuando priorices la expresividad y la similitud. Mantén un cargador por familia de tareas para que cada rama descendente se mantenga autónoma.
MossTTSGenerate (#2)#
El principal sintetizador de un solo hablante que consume tu mensaje de texto y audio de referencia opcional para producir discurso de 24 kHz. Proporciona texto limpio y bien puntuado para un ritmo más claro, y conecta un clip de voz corto cuando necesites clonación de cero disparos. Alterna la semilla entre fija y aleatoria para equilibrar la reproducibilidad y la exploración.
MossTTSVoiceDesign (#9)#
Genera una voz novedosa a partir de un mensaje descriptivo junto con el texto a hablar. Enfoca la descripción en timbre, edad, acento y energía para dirigir la identidad mientras la mantienes concisa. Esta es una opción fuerte cuando la concesión de licencias o la obtención de una voz real no es práctica.
MossTTSSoundEffect (#12)#
Sintetiza audio no verbal a partir de una breve descripción textual. Escribe mensajes compactos que anclen la fuente, la acción y el espacio, luego itera para coincidir con la escena. Ideal para ambientes y disparos únicos dentro del mismo gráfico ComfyUI MOSS TTS que usas para diálogo.
MossTTSDialogue (#15)#
Analiza etiquetas de hablante entre corchetes y representa conversaciones de múltiples turnos como una única salida de audio. Usa [S1], [S2], y así sucesivamente para marcar cada línea, y opcionalmente conecta clips de referencia por hablante para preservar la identidad a través de los turnos. Mantén las líneas concisas para los traspasos más confiables entre hablantes.
Extras opcionales#
- Comienza con el modelo Local 1.7B para borradores rápidos, luego cambia a un punto de control Delay 8B cuando necesites mayor similitud o prosodia más rica.
- Para clonación de cero disparos, usa un clip de voz limpio de 5–15 s con mínima reverberación y ruido para mejorar la transferencia de timbre.
- En diálogo, mantén las etiquetas de hablante consistentes y libres de puntuación como
[S1]para evitar errores de análisis. - Crea mensajes de diseño de voz con 3–6 rasgos como timbre, edad, acento, estilo y energía para resultados predecibles.
- Usa puntuación y saltos de línea en tu texto para controlar pausas y ritmo en las salidas de ComfyUI MOSS TTS.
- Añade un nodo
SaveAudiodespués de cualquier vista previa si deseas exportación automática de archivos para renders por lotes.
Referencias: OpenMOSS/MOSS-TTS • MOSS-TTS-Local-Transformer • MOSS-TTS • MOSS-Audio-Tokenizer • comfyui-moss-tts
Reconocimientos#
Este flujo de trabajo implementa y se basa en los siguientes trabajos y recursos. Agradecemos sinceramente a richservo por los nodos personalizados ComfyUI MOSS-TTS, a OpenMOSS por el repositorio MOSS-TTS y al equipo OpenMOSS-Team por los modelos MOSS-TTS (Delay 8B y Local 1.7B) y el MOSS Audio Tokenizer por sus contribuciones y mantenimiento. Para detalles autoritativos, por favor consulta la documentación original y los repositorios enlazados a continuación.
Recursos#
- richservo/comfyui-moss-tts
- GitHub: richservo/comfyui-moss-tts
- OpenMOSS/MOSS-TTS
- GitHub: OpenMOSS/MOSS-TTS
- Hugging Face: OpenMOSS-Team/MOSS-TTS
- arXiv: 2603.18090
- OpenMOSS-Team/MOSS-TTS (Delay 8B)
- GitHub: OpenMOSS/MOSS-TTS
- Hugging Face: OpenMOSS-Team/MOSS-TTS
- arXiv: 2603.18090
- OpenMOSS-Team/MOSS-TTS-Local-Transformer (Local 1.7B)
- GitHub: OpenMOSS/MOSS-TTS
- Hugging Face: OpenMOSS-Team/MOSS-TTS-Local-Transformer
- arXiv: 2603.18090
- OpenMOSS-Team/MOSS-Audio-Tokenizer
- Hugging Face: OpenMOSS-Team/MOSS-Audio-Tokenizer
- arXiv: 2602.10934
Nota: El uso de los modelos, conjuntos de datos y código referenciados está sujeto a las respectivas licencias y términos proporcionados por sus autores y mantenedores.
