
ComfyUI F5 TTS: texto a voz y clonación de voz en un solo flujo de trabajo#
Este flujo de trabajo de ComfyUI F5 TTS te permite generar discurso natural a partir de texto y clonar voces directamente dentro de ComfyUI. Está impulsado por los nodos personalizados ComfyUI-F5-TTS e incluye un camino completo para clonación basada en referencia: proporciona un WAV corto más una transcripción correspondiente para condicionar el modelo, luego sintetiza nuevas líneas que siguen el timbre y estilo del hablante de referencia. El gráfico también incluye pruebas listas para ejecutar de múltiples variantes de modelos, idiomas y vocoders, para que puedas comparar salidas rápidamente y decidir qué es lo mejor para narraciones, locuciones, diálogo de personajes o demostraciones de productos.
Todo está organizado en grupos claros para que puedas usar ComfyUI F5 TTS de dos maneras: TTS rápido con un solo clic en inglés, francés, alemán y japonés, o clonación de voz a través de un grabador incorporado o archivos emparejados. Se incluye un camino de transcripción compacto Whisper para ayudarte a obtener una transcripción de muestra precisa cuando ya tienes una grabación limpia.
Modelos clave en el flujo de trabajo ComfyUI F5 TTS#
- Fish Audio F5-TTS. TTS de cero disparos que aprende las características de un hablante a partir de una referencia corta y produce discurso de alta calidad en múltiples idiomas. Consulta el proyecto para detalles del modelo y antecedentes de entrenamiento. GitHub
- OpenAI Whisper. Reconocimiento de voz utilizado aquí para transcribir automáticamente tu clip de referencia para que el texto de muestra coincida exactamente, lo que mejora la calidad de la clonación. GitHub
- BigVGAN. Un vocoder neural de alta fidelidad disponible como opción de decodificación para una salida más nítida y clara. GitHub
- Vocos. Una alternativa de vocoder neural rápida y liviana enfocada en velocidad y baja latencia. GitHub
- Nodos personalizados ComfyUI-F5-TTS. La integración de ComfyUI que conecta F5-TTS y backends compatibles en nodos utilizados a lo largo de este gráfico. GitHub
Cómo usar el flujo de trabajo ComfyUI F5 TTS#
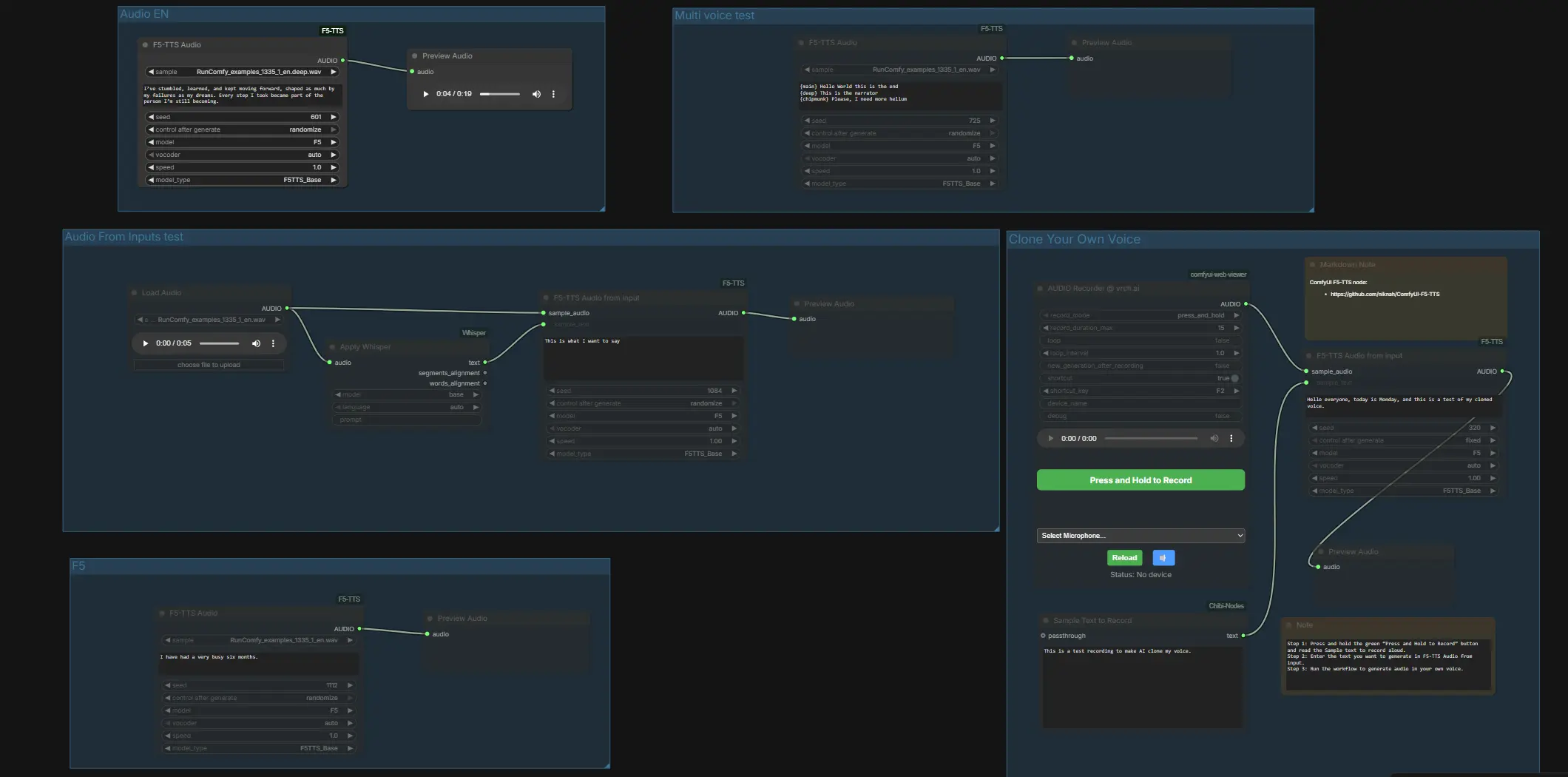
A un alto nivel, el flujo de trabajo ofrece grupos independientes para comparaciones rápidas de modelos y un carril de clonación dedicado. Comienza audicionando los grupos preconfigurados para confirmar la voz y el vocoder que prefieres, luego pasa a la clonación con tu propia muestra. Cada subsección a continuación explica qué hace el grupo y los pocos insumos que importan.
Prueba de Audio Desde Entradas#
Este carril demuestra transcripción de referencia más condicionamiento. LoadAudio (#4) trae un WAV, Apply Whisper (#13) lo transcribe, y F5TTSAudioInputs (#26) utiliza tanto el audio de muestra como el texto de Whisper para condicionar la voz antes de la vista previa. Proporciona una muestra hablada limpia y deja que Whisper llene el puerto de transcripción para que el par coincida exactamente. Si deseas suministrar archivos directamente, coloca un .wav y .txt emparejados con el mismo nombre de archivo en ComfyUI/input, luego reinicia ComfyUI para que el gráfico pueda verlos.
Prueba de múltiples voces#
Este grupo muestra el cambio de estilo dentro de una línea usando un solo nodo de síntesis. F5TTSAudio (#17) lee un guion con segmentos etiquetados, para que puedas audicionar múltiples estilos de personajes o cambios de énfasis en una sola pasada. Es una forma rápida de escuchar cómo maneja ComfyUI F5 TTS los timbres contrastantes o el ritmo de narrador versus personaje.
Audio EN#
Usa F5TTSAudio (#15) para TTS en inglés sencillo. Ingresa tu guion y haz una vista previa para evaluar la pronunciación y el ritmo básicos con el preset F5 predeterminado. Este carril es ideal para iteración rápida antes de comprometerte con la clonación o mezcla de múltiples voces.
F5v1#
Este camino ejecuta el nodo F5TTSAudio (#33) contra la variante F5 v1 para que puedas comparar el tono y la prosodia con el preset F5 principal. Usa el mismo texto que el carril EN para facilitar juzgar las diferencias. Es útil al elegir un modelo predeterminado para un proyecto más largo.
Audio FR#
Este carril apunta a la síntesis en francés con F5TTSAudio (#27) configurado para un preset francés. Proporciona un guion en francés y haz una vista previa de la salida para verificar el manejo de las vocales nasales y la liaison. Cambia de ida y vuelta con el carril EN para comparar claridad y velocidad.
Audio DE bigvgan#
Aquí F5TTSAudio (#30) usa un preset alemán y el vocoder BigVGAN para una decodificación más brillante y nítida. Usa este carril cuando quieras más presencia o un brillo de estudio. Si prefieres una representación más suave, compara contra un carril Vocos.
Audio JP#
Este camino usa F5TTSAudio (#25) con un preset japonés. Pega un guion en japonés para evaluar el acento de tono y el tiempo de mora. Es un buen punto de partida para lecturas estilo anime o líneas de productos destinadas a audiencias japonesas.
Prueba E2#
Este grupo ejercita F5TTSAudio (#29) con un preset compatible con E2 y el vocoder Vocos para audicionar un backend alternativo. Úsalo para comparar latencia y características de timbre con tus ejecuciones F5.
Clona Tu Propia Voz#
Graba, empareja y clona directamente en ComfyUI. Presiona el micrófono en VrchAudioRecorderNode (#43) y lee el mensaje mostrado en la caja “Sample Text to Record” Textbox (#42). El grabador dirige tu WAV a F5TTSAudioInputs (#44) junto con el texto exacto que hablaste, lo que condiciona el modelo en tu timbre y estilo antes de la vista previa en PreviewAudio (#45). Para obtener los mejores resultados, habla en una habitación silenciosa y asegúrate de que el texto de referencia coincida con lo que dijiste literalmente; luego escribe cualquier nueva línea que quieras que la voz clonada diga y ejecuta el gráfico.
Nodos clave en el flujo de trabajo ComfyUI F5 TTS#
F5TTSAudio (#15)#
El nodo TTS de un solo paso utilizado en los grupos EN, FR, DE, JP, F5v1 y E2. Proporciona tu guion y elige el preset de modelo y vocoder que se adapten a tu idioma y entrega. Si quieres tomas reproducibles, mantén la semilla fija; si quieres variedad, aleatoriza entre ejecuciones. La implementación es proporcionada por la extensión ComfyUI-F5-TTS. GitHub GitHub - FishAudio/F5-TTS
F5TTSAudioInputs (#44)#
El punto de entrada de clonación que consume un WAV de referencia y su transcripción correspondiente para construir una representación del hablante, luego sintetiza nuevas líneas en esa voz. Usa una muestra limpia con volumen constante y asegúrate de que la transcripción sea exacta para maximizar la similitud y reducir artefactos. Cambia presets de modelo o vocoders aquí si necesitas una decodificación más brillante o más neutral. GitHub - FishAudio/F5-TTS
Apply Whisper (#13)#
Transcripción automática para tu muestra de referencia. Elige un tamaño de Whisper que equilibre velocidad y precisión para tu hardware e idioma, luego alimenta su texto de salida al nodo de clonación para que el audio y el texto estén perfectamente alineados. Esto previene errores de condicionamiento que pueden ocurrir cuando el texto de muestra difiere de lo que realmente se habló. GitHub
VrchAudioRecorderNode (#43)#
Un grabador en el gráfico que captura un mensaje hablado corto para clonación, eliminando la necesidad de herramientas externas. Mantén presionado para grabar, suelta para detener y escucha inmediatamente cómo suena ComfyUI F5 TTS en tu propia voz. Mantén el micrófono cerca y reduce el ruido de la habitación para obtener el resultado más limpio.
Extras opcionales#
- Usa de 5 a 15 segundos de discurso limpio para la referencia, sin música ni efectos.
- Asegúrate de que la transcripción de la muestra coincida exactamente con la grabación; incluso pequeñas discrepancias pueden reducir la fidelidad de la clonación.
- Compara Vocos y BigVGAN en la misma línea para decidir entre velocidad y detalle.
- Mantén una semilla fija cuando necesites retomas consistentes; aleatoriza al explorar estilo.
- Para proyectos multilingües, audiciona primero los carriles EN, FR, DE y JP, luego finaliza la clonación una vez que estés satisfecho con la pronunciación y el ritmo.
Agradecimientos#
Este flujo de trabajo implementa y se basa en los siguientes trabajos y recursos. Agradecemos sinceramente a niknah por el nodo ComfyUI-F5-TTS, a niknah por el ejemplo de flujo de trabajo F5TTS-test-all.json, y a la comunidad de r/StableDiffusion por la guía “Voice Cloning with F5-TTS in ComfyUI” por sus contribuciones y mantenimiento. Para detalles autorizados, por favor consulta la documentación original y los repositorios enlazados a continuación.
Recursos#
- niknah/ComfyUI-F5-TTS
- GitHub: niknah/ComfyUI-F5-TTS
- niknah/ComfyUI-F5-TTS (Flujo de Trabajo de Ejemplo: F5TTS-test-all.json)
- Guía de la Comunidad r/StableDiffusion (Clonación de Voz con F5-TTS en ComfyUI)
- GitHub: example_web_viewer_005_audio_web_viewer_f5_tts.json
- Documentos / Notas de Lanzamiento: ¡Clona Tu Propia Voz Sin Esfuerzo usando ComfyUI y Casi en Tiempo Real! (Tutorial Paso a Paso e Incluye Flujo de Trabajo)
Nota: El uso de los modelos, conjuntos de datos y código referenciados está sujeto a las respectivas licencias y términos proporcionados por sus autores y mantenedores.