
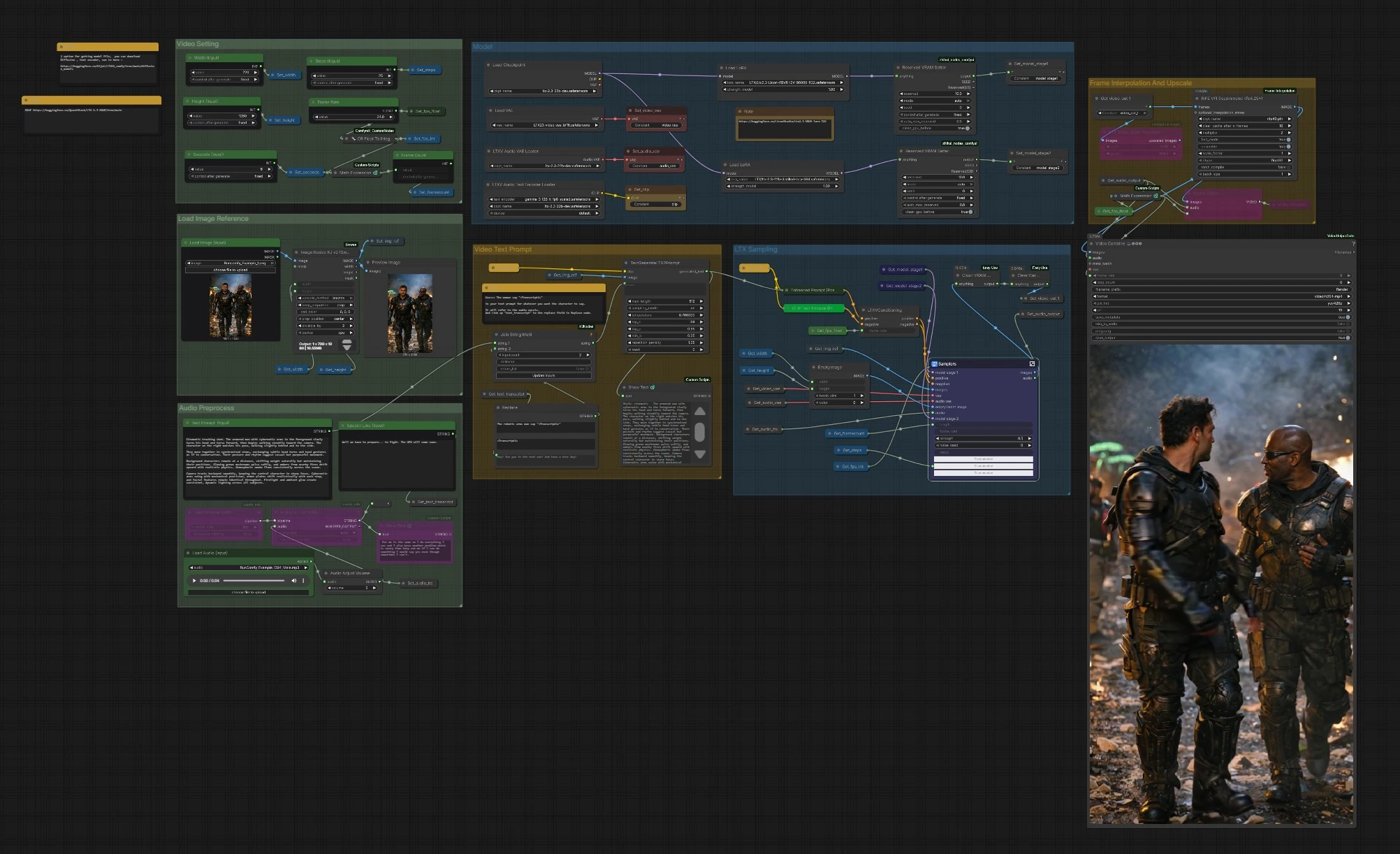
LTX 2.3 VBVR ComfyUI Workflow: Reasoning-bewusstes Bild-zu-Video mit Dialog#
Dieser Workflow verwandelt ein einzelnes Referenzbild in eine kohärente Videosequenz, die von Text und optionaler Sprache geleitet wird, angetrieben von LTX‑2.3 und der LTX 2.3 VBVR LoRA. VBVR steht für video-basiertes visuelles Reasoning: Es hilft dem Modell, Identitäten, räumliche Beziehungen und Ursache-Wirkung über die Frames hinweg konsistent zu halten, sodass Ihre Szenen beabsichtigt und nicht zufällig wirken. Der Graph umfasst sprachbewusste Aufforderungen, zweistufiges LTX-Sampling, Bewegungsweichung und abschließendes Upscaling/Export nach MP4.
Kreative, die narrative Kontinuität, glaubwürdige Bewegungen oder Dialogtiming benötigen, finden den LTX 2.3 VBVR-Workflow besonders nützlich. Stellen Sie einen starken Referenzrahmen zur Verfügung, beschreiben Sie die Aktion und Interaktionen und fügen Sie optional eine gesprochene Zeile ein, die automatisch transkribiert und in die Aufforderung eingeflochten wird, um eine bessere Lippen- und Timing-Ausrichtung zu erzielen.
Schlüsselmodelle im ComfyUI LTX 2.3 VBVR-Workflow#
- LTX‑2.3 22B Video-Generierungsmodell von Lightricks, das Haupt-Diffusions-Backbone für Bild-zu-Video- und audio-konditioniertes Decoding. Hugging Face: Lightricks/LTX-2.3
- LTX‑2.3 Video VAE für das Encoding/Decoding von Video-Latents, gepaart mit dem Basis-Checkpoint für effizientes gekacheltes Decoding. Hugging Face: Lightricks/LTX-2.3
- LTX‑2.3 Spatial Upscaler x2 Latent-Modell zur Verbesserung der räumlichen Details nach dem ersten Durchgang. Hugging Face: Lightricks/LTX-2.3
- Gemma 3 12B Text-Encoder, verpackt für LTX‑2, hier verwendet, um komplexe Anweisungen und Dialog-Tokens zu parsen. Hugging Face: Comfy-Org/ltx-2
- LTX 2.3 VBVR LoRA für reasoning-zentrierte Szenenstruktur, Objektinteraktion und Kontinuität über die Zeit. Hugging Face: LiconStudio/Ltx2.3-VBVR-lora-I2V
- RIFE Frame-Interpolation-Modell zur Glättung von Bewegungen zwischen generierten Frames. GitHub: hzwer/Practical-RIFE
- Whisper Spracherkennungsmodell für optionale Audio-zu-Text-Prompt-Infusion. GitHub: openai/whisper
So verwenden Sie den ComfyUI LTX 2.3 VBVR-Workflow#
Der Graph ist in klare Gruppen organisiert. Sie konfigurieren Eingaben, den Modell-Stack und Videoeinstellungen, dann generieren die LTX-Sampler Frames, die optional interpoliert und hochskaliert werden, bevor sie exportiert werden.
Bildreferenz laden#
Verwenden Sie Load Image (Input) (#5525), um einen starken, stilvollen Referenzrahmen auszuwählen. Das Bild wird von ImageResizeKJv2 (#5280) auf die gewählte Breite und Höhe skaliert, wobei die Komposition erhalten bleibt. Ein Vorschau-Knoten bestätigt, was das Modell tatsächlich sehen wird. Gute Referenzbilder mit klaren Motiven und Beleuchtung bieten dem LTX 2.3 VBVR-Stack einen zuverlässigen Anker für Identität und Stil.
Videoeinstellungen#
Setzen Sie Width (Input) (#5284), Height (Input) (#5286), Seconds (Input) (#5573) und die Basis-Frame Rate (#5289). Der Graph berechnet die Frame-Anzahl automatisch, sodass das Timing konsistent bleibt, wenn Sie die Dauer oder fps ändern. Wenn Sie planen, später Interpolation zu aktivieren, können Sie eine bescheidene Basis-fps wählen, um Zeit zu sparen, und RIFE glättet die Bewegung. Diese Einstellungen informieren auch den Konditionierungsknoten, sodass Bewegung und Takt kohärent bleiben.
Modell#
CheckpointLoaderSimple (#5493) lädt LTX‑2.3. Der Graph verbindet die LTX 2.3 VBVR LoRA über LoraLoaderModelOnly (#5616) und kann optional eine destillierte LoRA und eine Detailer LoRA für zusätzliche Treue anwenden. LTXAVTextEncoderLoader (#5494) bringt den auf Gemma basierenden Text-Encoder ein, während VAELoader (#5629) und LTXVAudioVAELoader (#5492) die Video- und Audio-VAEs bereitstellen. Zwei ReservedVRAMSetter-Knoten balancieren die Speichernutzung, sodass lange Läufe stabil bleiben.
Video-Text-Prompt#
Schreiben Sie Ihre Szene in Text Prompt (Input) (#5620). Um Dialoge zusammen mit Audio einzufügen, fügen Sie einen Platzhalter wie: Die Frau sagt "<Transcript1>" hinzu. Geben Sie die tatsächliche Zeile in Speech Line (Input) (#5524) ein oder lassen Sie Whisper sie aus dem Audio erzeugen; StringReplace (#5226) und JoinStringMulti (#5602) tauschen <Transcript1> mit dem Transkript aus. TextGenerateLTX2Prompt (#5488) komponiert dann eine verfeinerte Anweisung, die Enhanced Prompt (Positive) (#5174) kodiert, bevor LTXVConditioning (#5173) die endgültige Anleitung vorbereitet. Klare Verben, Subjektreferenzen und räumliche Hinweise geben der LTX 2.3 VBVR LoRA den Kontext, den sie benötigt, um über die Zeit zu argumentieren.
Audiovorverarbeitung#
Bringen Sie eine Sprachspur mit Load Audio (Input) (#5590) oder verbinden Sie TTS. AudioAdjustVolume (#5601) normalisiert die Pegel. Wenn Sie dialogbewusste Aufforderungen wünschen, verwenden Sie Whisper über Load Whisper (mtb) (#5606) und Audio To Text (mtb) (#5607), um das im Prompt verwendete Transkript zu erzeugen. Das gleiche Audio wird auch als Latent kodiert und später in das endgültige Video gemischt, sodass Lippen- und Timing-Hinweise die Generierung beeinflussen können.
LTX-Sampling#
LTXVPreprocess (#5240) und LTXVImgToVideoInplace (#5245) konvertieren Ihren Referenzrahmen in eine anfängliche latente Sequenz, die die Kernidentität bewahrt und gleichzeitig Bewegung ermöglicht. Der Samplers-Untergraph (#5278) führt einen zweistufigen Prozess mit CFG-Leitern und einem Scheduler durch, der spatio-temporale Latents erzeugt, die sowohl Ihre Aufforderung als auch die LTX 2.3 VBVR Reasoning LoRA respektieren. Audio-Latents werden mit Video-Latents verkettet, sodass die Sprachtiming die Bewegung informieren kann. LTXVSpatioTemporalTiledVAEDecode (#5237) dekodiert Frames, und LTXVAudioVAEDecode (#5103) stellt die Audiospur wieder her.
Frame-Interpolation und Upscaling#
RIFE VFI (#5554) interpoliert zwischen Frames, um eine glattere Bewegung zu erzeugen und Ihre Zielwiedergaberate zu erreichen, wenn sie mit der Basis-fps kombiniert wird. RTXVideoSuperResolution (#5631) verbessert Details und reduziert Kompressionsartefakte, was die Lesbarkeit von Gesichtern, Kanten und kleinen Requisiten verbessert. Verwenden Sie diese Stufe, um Geschwindigkeit und Qualität auszugleichen: Interpolieren Sie für Glätte, dann skalieren Sie für Schärfe hoch.
Export#
Wählen Sie zwischen CreateVideo (#5599) für ein einfaches Mux oder VHS_VideoCombine (#5618) für mehr Kontrolle über Format, Metadaten und Trimmen. Die Pipeline schreibt ein H.264 MP4 über SaveVideo (#5597). Die Bildrate wird aus Ihren Einstellungen und der Interpolationsstufe abgeleitet, sodass die Wiedergabe mit der Bewegungsabsicht übereinstimmt, die Sie zu Beginn erstellt haben.
Schlüssel-Knoten im ComfyUI LTX 2.3 VBVR-Workflow#
LoraLoaderModelOnly (#5616)#
Lädt die LTX 2.3 VBVR LoRA, die logische Kontinuität, Objektinteraktion und kamera-bewusste Bewegung verbessert. Passen Sie das LoRA-Gewicht an, um den Einfluss des Reasonings mit dem Stil des Basismodells und anderer LoRAs auszugleichen. Dieser Knoten ist zentral für das unverwechselbare Aussehen und die Kohärenz, die den LTX 2.3 VBVR-Workflow definieren. Für LTX-Knoten und LoRA-Nutzung, siehe Lightricks/ComfyUI-LTXVideo und die oben genannte VBVR LoRA-Karte.
TextGenerateLTX2Prompt (#5488)#
Setzt die endgültige positive Aufforderung zusammen, indem Ihre Basisbeschreibung, die Bildreferenz und das aus <Transcript1> ersetzte Dialog-Token zusammengeführt werden. Halten Sie Anweisungen prägnant, explizit und konsistent bezüglich der Subjekte und Aktionen, damit das Modell über die Zeit argumentieren kann. Hier kodieren Sie die Absicht, die die LTX 2.3 VBVR LoRA während des Samplings verstärken wird.
LTXVConditioning (#5173)#
Verpackt positive und negative Konditionierung und leitet Timing-Informationen weiter, sodass Bewegung und Takt mit Ihrer fps-Wahl übereinstimmen. Wenn Sie die Bildrate in den Einstellungen ändern, aktualisieren Sie sie hier, um die Bewegungsdynamik konsistent zu halten. Starke Negative helfen, stehende Frames, Wasserzeichen oder unerwünschte Overlays aus der Sequenz herauszuhalten.
Samplers (#5278)#
Der zweistufige Sampler-Block koordiniert Rauschen, Führung und Planung, um die Bild- und Audio-Latents in ein kohärentes Video zu transformieren. Die wirkungsvollsten Anpassungen sind die Gesamt-steps, die image strength der anfänglichen I2V-Stufe und der noise_seed für Reproduzierbarkeit. Passen Sie diese sorgfältig an, um die Treue zum Referenzrahmen gegen die Bereitschaft, neuen Bewegungen und Aktionen zu folgen, abzuwägen.
RIFE VFI (#5554)#
Interpoliert Frames für glattere Bewegungen oder um eine höhere effektive fps zu erreichen, ohne die Sequenz neu zu generieren. Erhöhen Sie die Interpolation, wenn Ihre Basis-fps niedrig ist oder wenn sich die Bewegung stotternd anfühlt; verringern Sie sie, um den ursprünglichen generativen Rhythmus zu bewahren. Das Modell wird häufig für hochwertige VFI verwendet; siehe das RIFE-Projekt auf GitHub.
Optionale Extras#
- Dialogtrick mit LTX 2.3 VBVR: Schreiben Sie einen natürlichen Satz mit dem Platzhalter, zum Beispiel Die Frau sagt "<Transcript1>", dann geben Sie die Zeile in Speech Line ein oder lassen Sie Whisper das Audio transkribieren, sodass die Aufforderung und die Lippen übereinstimmen.
- Prompting für Reasoning: Nennen Sie, wer was, wo und warum tut. Verwenden Sie konsistente Subjektnamen und zeitliche Hinweise wie dann, während und als sich die Kamera bewegt, um die Stärken von VBVR zu nutzen.
- Schnellere Iterationen: Beginnen Sie mit einer kürzeren Dauer oder niedrigeren Basis-fps, bestätigen Sie Bewegungsschläge, dann erhöhen Sie die Interpolation oder Sekunden, um zu beenden.
- Stabilitätstipps: Wenn Sie Identitätsverschiebungen sehen, verringern Sie die Bild-zu-Video-Stärke leicht oder erhöhen Sie das VBVR LoRA-Gewicht; wenn Sie Überbeschränkung sehen, tun Sie das Gegenteil.
Danksagungen#
Dieser Workflow implementiert und baut auf den folgenden Arbeiten und Ressourcen auf. Wir bedanken uns herzlich bei @Benji’s AI Playground für die 2.3 VBVR Workflow Source für ihre Beiträge und Wartung. Für autoritative Details verweisen wir auf die originale Dokumentation und die unten verlinkten Repositories.
Ressourcen#
- LTX/2.3 VBVR Workflow Source
- Docs / Release Notes: LTX 2.3 VBVR Workflow Source @Benji’s AI Playground
Hinweis: Die Verwendung der referenzierten Modelle, Datensätze und Codes unterliegt den jeweiligen Lizenzen und Bedingungen der Autoren und Betreuer.