
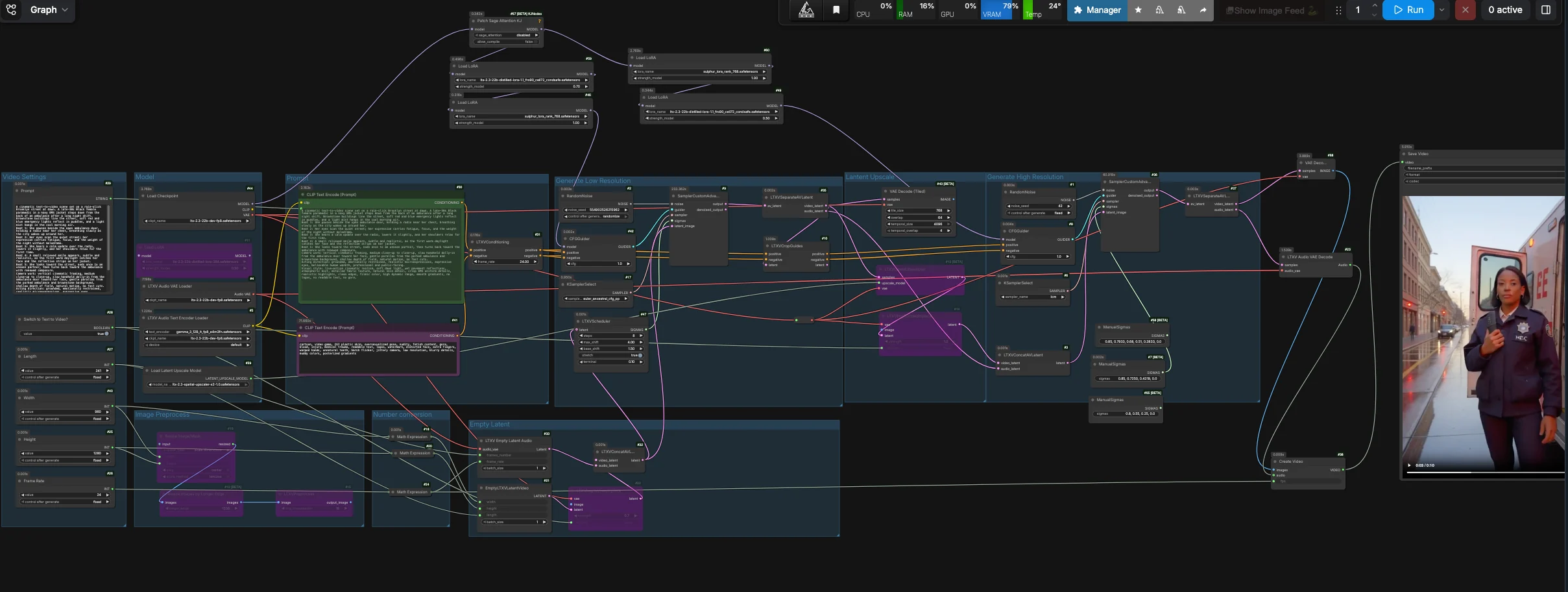
LTX 2.3 Sulphur T2V-Workflow: Prompt-zu-Kino mit Mikroexpressionen, Stimmung und geführter Kamera#
Der LTX 2.3 Sulphur T2V-Workflow verwandelt gut geschriebene Prompts in filmische Clips, die glaubwürdige Mikroexpressionen, atmosphärische Szenendetails und geschichtengetriebene Bewegungen betonen. Er kombiniert einen destillierten LTX 2.3-Generierungspass mit Sulphur-Stilführung, optionaler Kamera-Leitführung und einem stabilen Kachel-Dekodierungspfad für zuverlässige Text-zu-Video-Ergebnisse.
Entwickelt für Kreative, die fundierte Schauspielschläge und kontrollierbare Kamerabewegungen wünschen, balanciert dieses ComfyUI-Setup narrative Treue mit zeitlicher Stabilität. Sie können einen reinen Text-zu-Video-Durchlauf starten oder von einem Standbild aus beginnen und dann den stabilen Erstpass-Latenten in eine saubere, editorfreundliche Sequenz mit einem Platzhalter-Audiotrack für einfaches Bearbeiten dekodieren.
Schlüsselmodelle im Comfyui LTX 2.3 Sulphur T2V-Workflow#
- Lightricks LTX-2.3 22B FP8 Checkpoint. Das Basismodell für Text-zu-Video, das Generierung und Dekodierung antreibt. Model repository
- LTX-2.3 destilliertes LoRA. Ein destillierter Adapter, der Qualität bewahrt und gleichzeitig schnelleres, niedrigstufiges Sampling und stabile Bewegung ermöglicht. Model family
- LTX-2.3 räumlicher Upscaler x2. In das Diagramm für Experimente aufgenommen, während der Standard-Exportpfad die stabile Erstpass-Dekodierung für sauberere Ergebnisse bei diesem Setup verwendet. Upscaler
- LTX-2 19B LoRA Camera Control Dolly Left. Optionale Anleitung für gleichmäßige Dolly-in-Bewegung und sanften Parallax, wenn Ihre Szene es erfordert. LoRA
- LTX-Text-Encoder (Gemma 3 12B-Varianten). Das Tokenizer- und Einbettungsmodell, das Ihre Prompts und Schlageinträge interpretiert. Text encoders
- LTX Audio VAE. Packt einen stillen Audiostream, sodass das resultierende Video sauber in NLEs geladen wird. Model repository
- Sulphur LoRA (gebündelt). Ein Stil- und Schauspielschlag-Adapter, der für ausdrucksstarke, aber zurückhaltende Mikroexpressionen und filmische Farbharmonie kuratiert wurde.
Verwendung des Comfyui LTX 2.3 Sulphur T2V-Workflows#
Dieser Workflow standardmäßig auf einem stabilen Erstpass-Text-zu-Video-Pfad. Er erzeugt einen kohärenten Video-Latenten, trennt die Video- und Audiobahnen, dekodiert den Erstpass-Video-Latenten mit gekachelter VAE-Dekodierung und verpackt dann die Frames und die stille Audio in eine bearbeitungsfertige Videodatei. Die latente Upscale- und Verfeinerungs-Knoten bleiben im Diagramm für fortgeschrittene Experimente, aber der Standardausgang umgeht diesen Zweig für Zuverlässigkeit.
Modell#
Die Modellgruppe lädt den LTX-2.3 FP8-Checkpoint, den LTX-Text-Encoder, das Audio VAE und die währenddessen verwendeten Adapter. Destillierte und Sulphur LoRAs werden auf das Basismodell angewendet, sodass die Szene Ihren Schlägen und Gesichtsausdrücken eng folgt. Wenn Sie Dolly-Bewegung möchten, aktivieren Sie die Kamera-Leitungs-LoRA in den bereitgestellten LoraLoader-Knoten. Der Standardpfad leitet den primären Sampler durch CFGGuider (#42), während der Verfeinerungszweig für manuelle Experimente verfügbar bleibt.
Prompt#
Schreiben Sie Ihre Szene im Prompt-Feld (#29) als kurze Schlagzeilen plus kurze Kameranotizen. Der positive Text wird von CLIPTextEncode (#30) kodiert, während eine kuratierte Negativliste in CLIPTextEncode (#41) CGI-Glanz, Artefakte, Zittern und starkes Flackern unterdrückt. Halten Sie die Schauspielanweisungen prägnant und spezifisch für Augen, Schultern und Atmung, um die Mikroexpressionen freizuschalten, für die dieser Workflow abgestimmt ist. Kamerasprache wie „langsames Handdolly-in“ und „sanfter Parallax“ passt gut zum Scheduler und der optionalen Kamera-LoRA.
Videoeinstellungen#
Wählen Sie Ausgabe Width, Height, Frame Rate und Length in der Videoeinstellungen-Gruppe (#40, #25, #26, #27). Intern leitet der Workflow einen latenten in halber Auflösung für den Generierungspass ab, um die zeitliche Kohärenz zu verbessern, und dekodiert dann diesen stabilen Latenten direkt. Verwenden Sie Switch to Text to Video? (#28), um reines T2V auszuführen, oder schalten Sie es aus und führen Sie ein Startbild über den Bildvorbereitungsweg für kontrolliertes I2V. Die Abmessungen sollten auf gemeinsame Vielfache bleiben, um eine schnelle, kachelfreundliche Dekodierung zu ermöglichen.
Leerer Latenter#
EmptyLTXVLatentVideo (#21) erstellt einen leeren Video-Latenten gemäß Ihren Einstellungen, und LTXVEmptyLatentAudio (#33) erstellt einen passenden Audio-Latenten, sodass der Container-Mux editorfreundlich ist. Wenn Sie von einem Bild aus beginnen möchten, kann LTXVImgToVideoInplace (#22) es in die latente Zeitleiste an einer kontrollierbaren strength einfügen. Wenn bypass aktiviert ist, ergibt der Knoten einen reinen textgesteuerten Start.
Niedrige Auflösung generieren#
Audio- und Video-Latente werden von LTXVConcatAVLatent (#32) zusammengeführt und von LTXVScheduler (#47) getaktet, der einen video-bewussten Sigma-Zeitplan für reibungslose Bewegung und Kamerareise setzt. CFGGuider (#42) kombiniert Ihre positive und negative Konditionierung mit dem Modellstapel, und SamplerCustomAdvanced (#9) führt den primären Generierungspass aus. LTXVSeparateAVLatent (#35) teilt dann den Clip zurück in Video- und Audio-Latente; der Standardausgang verwendet diesen stabilen Video-Latenten für gekachelte Dekodierung.
Optionale Latente Upscale#
LTXVLatentUpsampler (#13) wendet den LTX x2 räumlichen Upscaler von LatentUpscaleModelLoader (#39) an und hält dabei die zeitliche Struktur intakt. LTXVImgToVideoInplace (#14) verpackt den hochskalierten Video-Latenten zusammen mit der bestehenden Audiobahn neu. Dieser Zweig bleibt verfügbar, wenn Sie mit höherer Auflösungsverfeinerung experimentieren möchten, ist jedoch nicht mit dem standardmäßigen endgültigen Ausgang verbunden.
Optionale Verfeinerung#
Der Verfeinerungszweig verwendet CFGGuider (#8) und SamplerCustomAdvanced (#36) mit einem kurzen, manuellen Sigma-Zeitplan. Er ist nützlich für fortgeschrittene Benutzer, die den hochauflösenden Pfad testen möchten, aber der Standard-Workflow-Ausgang umgeht diesen Zweig, da die stabile Erstpass-Kachel-Dekodierung sauberere Ergebnisse auf dem bereitgestellten RunComfy-Setup liefert.
Ausgang#
VAEDecodeTiled (#43) dekodiert den stabilen Video-Latenten von LTXVSeparateAVLatent (#35), und LTXVAudioVAEDecode (#23) erzeugt eine stille Spur, die die Editoren zufriedenstellt. CreateVideo (#38) assembliert die Sequenz mit Ihrer gewählten fps, und SaveVideo (#45) schreibt sie auf die Festplatte. Sie erhalten ein teilbares Video mit stabiler Bewegung, sauberen Farbverläufen und kontrolliertem Kamerafluss.
Schlüssel-Knoten im Comfyui LTX 2.3 Sulphur T2V-Workflow#
LTXVScheduler (#47)#
Orchestriert die video-bewusste Sigma-Sequenz für den ersten Durchgang. Seine Verschiebungssteuerungen beeinflussen, wie stark sich Bewegung zwischen den Frames akkumuliert; höhere Verschiebungen betonen Kamerareisen und schnellere Motivbewegungen, während niedrigere Werte eine stabilere Rahmung begünstigen. Wenn Sie eine Kamera-Leitungs-LoRA aktivieren, passen moderate Verschiebungen am besten, um übertriebene Driften zu vermeiden.
LTXVCropGuides (#10)#
Erzeugt zuschnittsbewusste Konditionierungskanäle aus Ihrem Text, sodass wichtige Regionen, insbesondere Gesichter, mit höherer Treue aufgelöst werden. Verwenden Sie es, um Mikroexpressionen und Augendetails ohne übermäßige Belastung des globalen Samplers zu steuern. Wenn Nahaufnahmen weich aussehen, straffen Sie Ihre Schauspielschläge und lassen Sie Crop Guides die Feinsteuerung übernehmen.
LTXVImgToVideoInplace (#22, #14)#
Verwandelt ein Standbild in einen zeitlich konsistenten Latenten oder verpackt einen hochskalierten Latenten für optionale Verfeinerung neu. Die strength-Steuerung legt fest, wie viel des Quellbildes über die Zeitleiste erhalten bleibt; niedrigere Werte erlauben mehr generative Anpassung, höhere Werte halten Rahmung und Identität fest. Schalten Sie bypass, um sauber zwischen I2V und reinem T2V zu wechseln.
LTXVLatentUpsampler (#13)#
Wendet den LTX x2 räumlichen Upscaler in-latent an, um Textur und Kanten für optionale Verfeinerungsexperimente zu heben. Der Standardexportpfad hängt nicht von diesem Knoten ab, sodass Sie den stabilen Erstpass-Ausgang mit dem Verfeinerungszweig vergleichen können, ohne die Hauptausgabekette zu ändern.
CFGGuider (#42, #8) und KSamplerSelect (#17, #6)#
Diese Paarungen definieren, wie strikt das Modell Ihrem Text folgt und wie aggressiv es sampelt. Halten Sie die Führung konservativ für videorealismus; das Anheben kann die Prompt-Adhärenz erhöhen, aber die Bewegung versteifen oder Flackern hinzufügen. Der Standardexport verlässt sich auf den primären Sampler für stabile Bewegung, während der sekundäre Sampler für optionale Verfeinerungstests reserviert ist.
Optionale Extras#
- Schreiben Sie 3 bis 6 Schläge, die Absicht und Körpersprache anstatt Handlung beschreiben; Mikroexpressionen entstehen aus spezifischen Hinweisen wie "Augen weichen" oder "Schultern entspannen sich."
- Halten Sie die Kamerasprache kompakt: ein Bewegungsverb plus ein Subjekt, zum Beispiel "langsames Dolly-in auf ihr Gesicht" oder "sanfter Parallax von geparkten Autos."
- Wenn Sie statische Rahmung wünschen, deaktivieren Sie die Kamera-Leitungs-LoRA und reduzieren Sie die Scheduler-Verschiebungen leicht; für mehr Reise aktivieren Sie die LoRA und erhöhen die Verschiebung moderat.
- Verwenden Sie Breiten und Höhen, die saubere Vielfache von 32 sind, für vorhersehbare Kachelung und Dekodierung.
- Für Reproduzierbarkeit, sperren Sie Seeds in
RandomNoise(#2, #1); ändern Sie nur einen Seed, wenn Sie Variationen erkunden. - Der negative Prompt unterdrückt bereits CGI-Artefakte und Flackern; halten Sie ihn fokussiert und lassen Sie Ihren positiven Text Stil und Absicht tragen.
Danksagungen#
Dieser Workflow implementiert und baut auf den folgenden Arbeiten und Ressourcen auf. Wir danken RunningHub für das Workflow-Referenz, Lightricks für das LTX 2.3-Modell, destilliertes LoRA und räumlicher Upscaler, und Kamera-Leitungs-LoRA, und Comfy-Org für den LTX-Text-Encoder für ihre Beiträge und Wartung. Für autoritative Details verweisen wir auf die Originaldokumente und Repositories, die unten verlinkt sind.
Ressourcen#
- RunningHub/Workflow Reference
- Docs / Release Notes: Post
- Lightricks/LTX-2.3-fp8
- Hugging Face: Lightricks/LTX-2.3-fp8
- Lightricks/LTX-2.3
- Hugging Face: Lightricks/LTX-2.3
- Lightricks/LTX-2-19b-LoRA-Camera-Control-Dolly-Left
- Hugging Face: Lightricks/LTX-2-19b-LoRA-Camera-Control-Dolly-Left
- Comfy-Org/ltx-2
- Hugging Face: Comfy-Org/ltx-2
Hinweis: Die Nutzung der referenzierten Modelle, Datensätze und Codes unterliegt den jeweiligen Lizenzen und Bedingungen, die von ihren Autoren und Wartenden bereitgestellt werden.