

Was ist PhotoMakerV2#
PhotoMakerV2, ein Upgrade von PhotoMaker, bietet eine effiziente Methode zur personalisierten Text-zu-Bild-Generierung. Es synthetisiert realistische Fotos von Personen mit nur wenigen Eingabe-Identitätsbildern und einer Texteingabe.
Einige Hauptmerkmale von PhotoMakerV2 umfassen:#
- Hohe Effizienz: Generiert schnell personalisierte Fotos.
- Hervorragende Identitätsbewahrung: Bewahrt die Ähnlichkeit der Eingabe-Identitäten.
- Flexible Textkontrolle: Ermöglicht das Spezifizieren von Kontext, Stil, Attributen usw. in der Eingabe.
- Verbesserte Identitätstreue: Verbessert im Vergleich zu PhotoMaker V1.
PhotoMakerV2 generiert fotorealistische Bilder einer Person in verschiedenen Kontexten, stilisiert Erscheinungsbilder, ändert Attribute wie Alter und Geschlecht, verschmilzt Identitäten und modernisiert Personen aus alten Fotos oder Kunstwerken. Es eröffnet zahlreiche kreative Möglichkeiten.
Wie PhotoMakerV2 funktioniert#
PhotoMakerV2 kodiert ein oder mehrere Eingabe-Identitätsbilder in ein "stacked ID embedding", das als einheitliche Repräsentation dient, die Identitätsinformationen kapselt.
Dieses Embedding, kombiniert mit einer Texteingabe, wird in ein Text-zu-Bild-Diffusionsmodell eingespeist. Das Modell erzeugt dann ein Bild, das die eingebettete Identität im durch die Eingabe beschriebenen Kontext darstellt.
Einige wichtige Aspekte, wie es funktioniert:
- Verwendet einen Identitätsencoder, um Identitätsinformationen aus Eingabegesichtsbildern zu extrahieren
- Verbessert die Identitätsbewahrung durch Nutzung eines externen Gesichtserkennungsmodells (InsightFace)
- Kodiert mehrere Identitätsbilder in ein gestapeltes Embedding, um die Identität umfassend zu erfassen
- Speist das gestapelte ID-Embedding in die Cross-Attention-Schichten des Diffusionsmodells ein
- Führt die Generierung mit der Texteingabe, während es die Identitätsinformationen adaptiv verschmilzt
- Trainiert mit einem identitätsorientierten Datensatz, um die Identifikationsfähigkeiten zu verbessern
Wie man ComfyUI PhotoMakerV2 verwendet#
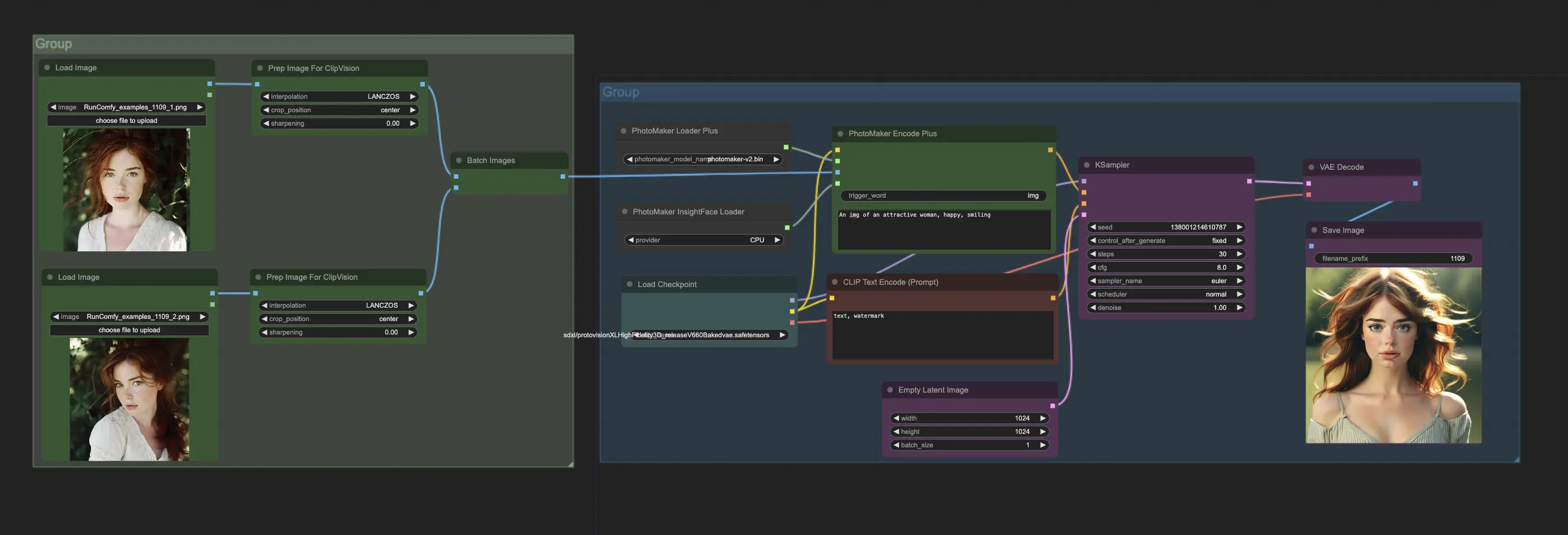
Um PhotoMakerV2 in ComfyUI zu verwenden, interagieren Sie hauptsächlich mit dem PhotoMakerEncodePlus-Knoten. Ein typischer Workflow umfasst:
- Laden Sie das PhotoMakerV2-Modell mit dem "PhotoMaker Loader Plus"-Knoten.
- Laden Sie ein oder mehrere Identitätsbilder mit dem "Prepare Images For CLIP Vision"-Knoten.
- Laden Sie das InsightFace-Modell, das von PhotoMakerV2 benötigt wird, mit dem "PhotoMaker InsightFace Loader"-Knoten.
- Verbinden Sie die Ausgaben dieser Knoten mit den entsprechenden Eingängen des "PhotoMaker Encode Plus"-Knotens.
- Geben Sie im "PhotoMaker Encode Plus"-Knoten die Eingabe ein, die das gewünschte Bild beschreibt. Verwenden Sie das spezielle Trigger-Wort in der Eingabe, wo die Identität erscheinen soll.
- Verbinden Sie die Ausgangsbedingungen vom "PhotoMaker Encode Plus" mit einem "KSampler"-Knoten, um das Bild zu erzeugen.
Für weitere Informationen besuchen Sie bitte PhotoMaker Hugging Face und ComfyUI-PhotoMaker-Plus. Alle Anerkennung geht an ihre Beiträge.