
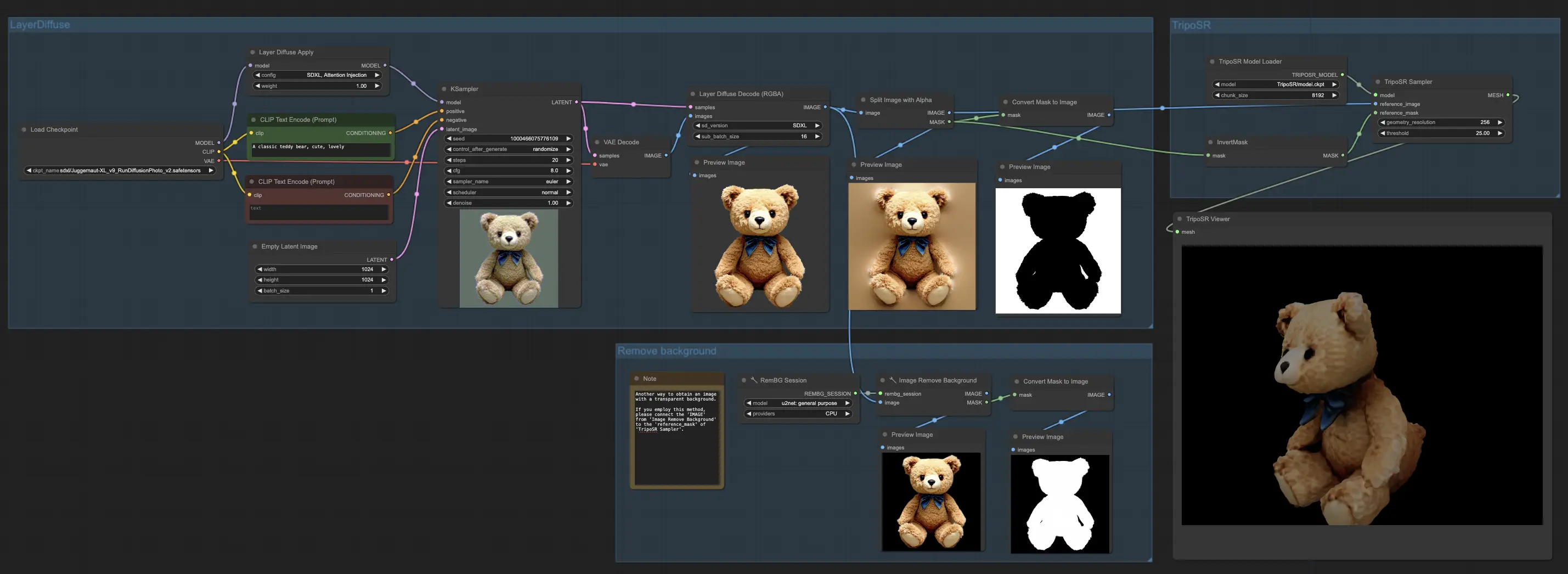
1. ComfyUI Workflow: LayerDiffuse + TripoSR | Image to 3D#
In the ComfyUI workflow, we harness the capabilities of LayerDiffuse to produce images with transparent backgrounds. Following this, both the image and its mask are passed on to TripoSR for the creation of 3D objects. The outcome is a rough yet quickly produced 3D model, showing promising potential for further refinement.
For those interested in obtaining the mesh file (.obj), you can find it in your file system's output section. This streamlined process offers a straightforward path from image to 3D model, combining the strengths of LayerDiffuse and TripoSR to enhance your 3D creation experience.
2. Overview of LayerDiffuse#
Please check out the details on How to use LayerDiffuse in ComfyUI
3. Overview of TripoSR#
3.1. Introduction to TripoSR#
TripoSR is a cutting-edge 3D reconstruction model that quickly turns single images into 3D objects with astonishing speed and precision. This innovation is a joint effort by Tripo AI and Stability AI. Utilizing a transformer architecture, TripoSR stands out for its ability to quickly process images into 3D forms. It builds on the Large Reconstruction Model (LRM) network architecture but brings in significant improvements in handling data, designing the model, and refining the training process. These advancements make TripoSR more accurate and efficient than other models available today.
3.2. Technical Architecture of TripoSR#
The core of TripoSR includes three main parts: an image encoder, an image-to-triplane decoder, and a triplane-based neural radiance field (NeRF). The image encoder uses a pre-trained vision transformer model to capture both the broad and specific details of an input image. These details are then turned into a detailed 3D model using the innovative triplane-NeRF setup. Uniquely, TripoSR can guess the camera's settings, making it versatile and efficient in different image conditions without needing exact camera information.
3.3. TripoSR Performance Benchmarking#
The performance of TripoSR stands out when compared with other leading models. It consistently exceeds in capturing the fine textures and complex shapes of objects swiftly. This exceptional performance, achieved quickly on standard computer hardware, showcases TripoSR's potential to change the 3D reconstruction landscape.




