
ChatterBox TTS ComfyUI: Multi-Mode TTS, Stimmenkonvertierung, Mehrsprachigkeit und Dialogsynthese in einem Graphen#
ChatterBox TTS ComfyUI ist ein kompakter, benutzerfreundlicher Audio-Workflow, der es Ihnen ermöglicht, Sprache in mehreren Modi von einer einzigen Leinwand zu erzeugen: Standard-TTS, Turbo-TTS für schnelle Entwürfe, mehrsprachige Erzählung, referenzgeführtes Stimmklonen, Stimmenkonvertierung und geskripteter Dialog mit zwei Sprechern. Es wird von der FL ChatterBox-Knotensuite von ComfyUI_Fill-ChatterBox angetrieben, die das Open-Source-Projekt Resemble AI Chatterbox integriert.
Verwenden Sie diesen Workflow, um KI-Stimmen zu prototypisieren, Zeilen in andere Sprachen zu lokalisieren, eine Aufführung in eine andere Stimme zu konvertieren oder Charakteraustausche zu blockieren. Das Layout hält jeden Pfad getrennt, sodass Sie Ergebnisse nebeneinander testen und schnell entscheiden können, welcher ChatterBox TTS ComfyUI-Modus für Ihre Aufgabe geeignet ist.
Wichtige Modelle im ComfyUI ChatterBox TTS ComfyUI-Workflow#
- Resemble AI Chatterbox TTS-Modelle. Kernneuronales TTS, das ein Skript in natürliche Sprache umwandelt, mit optionalem Referenzaudio zur Steuerung von Stimme und Stil. Resemble AI Chatterbox
- Resemble AI Chatterbox Turbo TTS. Eine TTS-Variante mit niedriger Latenz, die für Geschwindigkeit optimiert ist, wenn Sie schnelle Aufnahmen und iterative Aufforderungen benötigen. Resemble AI Chatterbox
- Resemble AI Chatterbox Mehrsprachiges TTS. Modelle, die Text in mehreren Sprachen wiedergeben und dabei einen gewählten Stil oder eine Referenzstimme beibehalten. Resemble AI Chatterbox
- Resemble AI Chatterbox Stimmenkonvertierung. Wandelt das Timbre einer Aufnahme in eine Zielstimme um, während Timing und Inhalt erhalten bleiben. Resemble AI Chatterbox
Verwendung des ComfyUI ChatterBox TTS ComfyUI-Workflows#
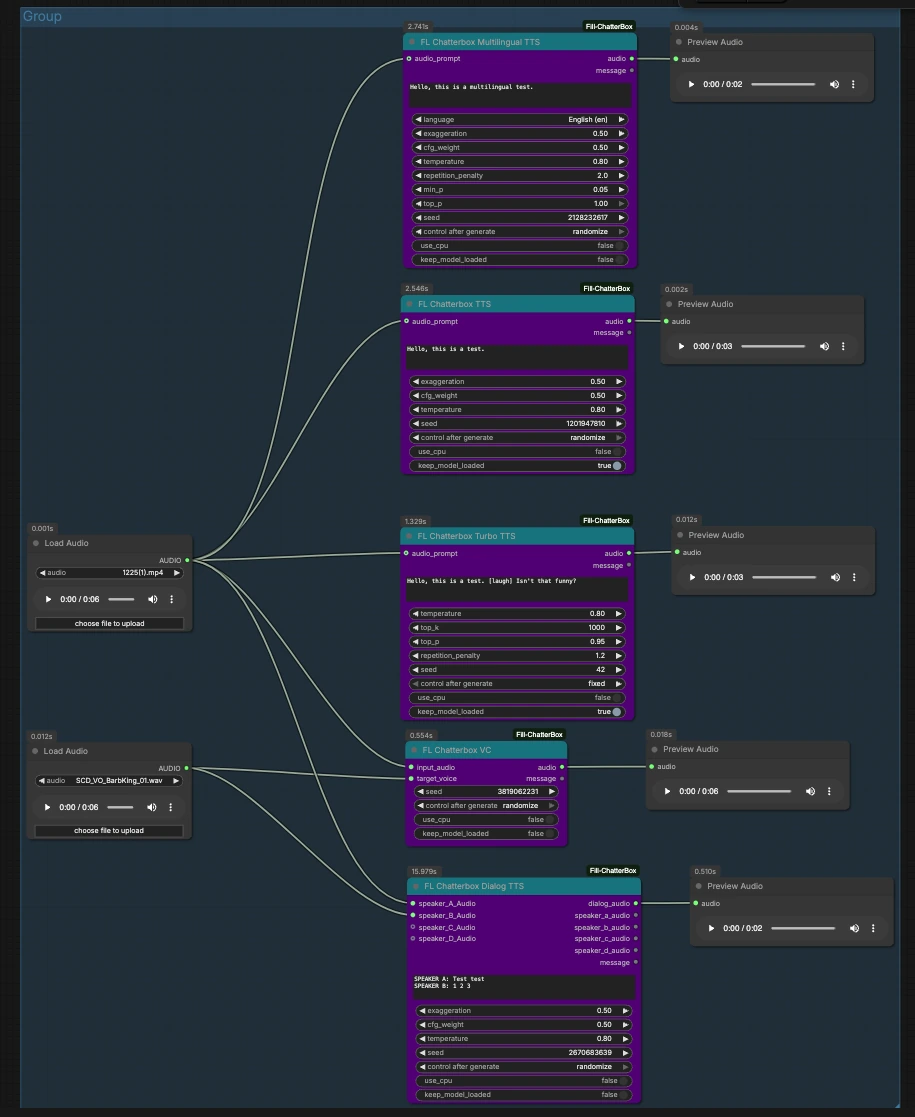
Dieser Graph ist als parallele Pfade organisiert, die von gemeinsamen Audioeingaben ausgehen und in ChatterBox-Knoten fließen, die jeweils ihr eigenes Ergebnis anzeigen. Laden oder ersetzen Sie die beiden Eingangsklips und aktivieren Sie den gewünschten Pfad.
Eingaben: Referenz- und Quellaudio#
Zwei LoadAudio-Knoten bieten wiederverwendbare Eingaben. LoadAudio (#12) speist mehrere Pfade als Stil- oder Quellenreferenz. LoadAudio (#20) dient als alternative Referenz oder Zielstimme. Sie können diese auf kurze, saubere Clips verweisen, die den Sprechstil oder die Identität darstellen, die Sie nachahmen möchten. Beide akzeptieren gängige Audiodateien und können auch Audio aus Videos extrahieren.
Standard-TTS mit optionaler Stilreferenz#
FL_ChatterboxTTS (#16) generiert Sprache aus Ihrem Skript und kann optional ein audio_prompt von LoadAudio (#12) aufnehmen, um Stimme und Lieferung zu erfassen. Geben Sie Ihren Text ein, verbinden Sie eine geeignete Referenz, wenn Sie Stimmähnlichkeit wünschen, und stellen Sie den Knoten in die Warteschlange. Verwenden Sie das angehängte PreviewAudio, um eine Vorschau zu hören. Fixieren Sie den Seed, wenn Sie reproduzierbare Aufnahmen benötigen, oder randomisieren Sie, um Variationen zu erkunden.
Turbo TTS für schnelle Iterationen#
FL_ChatterboxTurboTTS (#15) konzentriert sich auf schnelle Synthese für schnelle Entwürfe und interaktive Bearbeitung. Es akzeptiert ein audio_prompt von LoadAudio (#20), wenn Sie den Ton oder die Identität anstoßen möchten. Halten Sie Skripte kurz, wenn Sie sich schnell bewegen, und experimentieren Sie mit Markup wie dem Beispiel „[laugh]“, um nonverbale Hinweise zu testen. Hören Sie sich die Ausgabe an und wechseln Sie dann zu Standard- oder mehrsprachigem TTS, wenn Sie eine reichhaltigere Lieferung wünschen.
Mehrsprachige Erzählung#
FL_ChatterboxMultilingualTTS (#25) rendert Ihr Skript in der ausgewählten Sprache und kann Stil von audio_prompt auf LoadAudio (#12) übernehmen. Wählen Sie das Sprachlabel (zum Beispiel Englisch (en) wie im Graphen gezeigt) und geben Sie Text in dieser Sprache ein. Ein kurzer Referenzclip hilft, einen konsistenten Akzent oder eine Persona über Sprachen hinweg beizubehalten. Hören Sie in PreviewAudio und iterieren Sie die Formulierung für Klarheit.
Stimmenkonvertierung#
FL_ChatterboxVC (#19) konvertiert das Timbre einer input_audio-Zeile von LoadAudio (#12) in die target_voice von LoadAudio (#20). Dies ist ideal, wenn Sie bereits eine zeitlich perfekt abgestimmte Aufnahme haben und diese nur von einer anderen Stimme gesprochen werden soll. Schneiden Sie Stille aus und halten Sie die Zielstimme sauber, um Artefakte zu reduzieren. Verwenden Sie die Vorschau, um zu bestätigen, dass der Inhalt erhalten bleibt, während sich die Identität ändert.
Dialogsynthese mit zwei Sprechern#
FL_ChatterboxDialogTTS (#23) verwandelt ein mehrzeiliges Skript in eine einzelne dialog_audio-Spur. Geben Sie optionale speaker_A_Audio und speaker_B_Audio von den beiden LoadAudio-Knoten an, um die Stimme jedes Charakters zu verankern. Im Skriptfeld, Zeilen mit Sprecher-Tags wie „SPEAKER A:“ und „SPEAKER B:“ voranstellen, um die Reihenfolge zuzuweisen, wie im Graphen gezeigt. Sie können auf Sprecher C und D erweitern, indem Sie Referenzclips zu deren Eingaben hinzufügen.
Vorschau und Vergleich#
Jeder Pfad fächert sich auf sein eigenes PreviewAudio auf, sodass Sie sofort hören und Modi vergleichen können. Führen Sie einen Pfad nach dem anderen aus oder stellen Sie mehrere in die Warteschlange, um Unterschiede zwischen Standard-, Turbo-, mehrsprachigen, Konvertierungs- und Dialogausgaben innerhalb derselben ChatterBox TTS ComfyUI-Sitzung zu testen.
Wichtige Knoten im ComfyUI ChatterBox TTS ComfyUI-Workflow#
FL_ChatterboxTTS (#16)#
Allzweck-TTS, das ein Skript und eine optionale audio_prompt-Referenz akzeptiert, um den Stil zu imitieren. Verwenden Sie es, wenn Qualität und Steuerbarkeit am wichtigsten sind. Verwenden Sie denselben Referenzclip über mehrere Aufnahmen hinweg für eine konsistente Identität und fixieren Sie den Seed, wenn Sie genaue Reproduzierbarkeit benötigen.
FL_ChatterboxTurboTTS (#15)#
Schnelles TTS für das Entwerfen von Zeilen, das Iterieren von Aufforderungen oder das Vorschauen von Markup-Ideen. Es akzeptiert auch audio_prompt für die Stimmsteuerung. Wenn Sie im Vergleich zum Standardpfad eine dünnere Prosodie bemerken, finalisieren Sie mit FL_ChatterboxTTS mit demselben Skript und derselben Referenz.
FL_ChatterboxMultilingualTTS (#25)#
Sprachbewusstes TTS, das eine gewählte Persona beibehält, während es die Sprachen wechselt. Wählen Sie das Sprachlabel und geben Sie den Text in dieser Sprache ein. Ein passendes audio_prompt hält Akzent und Energie mit Ihrer Referenzstimme abgestimmt.
FL_ChatterboxVC (#19)#
Stimmenkonvertierung, die eine input_audio-Aufführung in eine target_voice abbildet. Verwenden Sie einen sauberen, repräsentativen Zielclip und eine gut getaktete Quellaufnahme. Für beste Ergebnisse, schneiden Sie lange Pausen und vermeiden Sie starkes Hintergrundrauschen in beiden Clips.
FL_ChatterboxDialogTTS (#23)#
Multi-Sprecher-TTS, das markierte Zeilen in ein einzelnes Gespräch umwandelt. Weisen Sie Referenzen für jeden Charaktereingang zu, den Sie verwenden möchten, und strukturieren Sie das Skript mit klaren „SPEAKER X:“ Tags. Halten Sie die Reihenfolgen angemessen kurz für ein natürliches Timing und einfachere Bearbeitungen später.
Optionale Extras#
- Halten Sie Referenzclips kurz, sauber und ausdrucksstark; Raumklang und Rauschen reduzieren die Stimmqualität.
- Verwenden Sie einen festen Seed, wenn Sie Timing und Lieferung über Überarbeitungen hinweg abstimmen müssen; randomisieren Sie, um Alternativen zu erkunden.
- Wenn ein Pfad zu laut oder abgeschnitten klingt, normalisieren Sie Ihre Referenzen und reduzieren Sie den Eingangspegel vor der Synthese.
- Turbo ist großartig für die Erkundung von Aufforderungen; führen Sie vielversprechende Zeilen mit Standard- oder mehrsprachigem TTS erneut aus, um den letzten Schliff zu geben.
- Dialogskripte sind leichter zu pflegen, wenn Sie pro Zeile eine Äußerung platzieren und die Sprecher konsequent markieren.
- Fügen Sie nach jeder Vorschau einen
SaveAudio-Knoten hinzu, wenn Sie Dateien direkt von der Leinwand exportieren möchten.
ChatterBox TTS ComfyUI bietet Ihnen einen flexiblen, einheitlichen Graphen-Spielplatz, um Stimmen, Sprachen und Dialoge ohne Kontextwechsel auszuprobieren, unterstützt von ComfyUI_Fill-ChatterBox und Resemble AI Chatterbox.
Danksagungen#
Dieser Workflow implementiert und baut auf den folgenden Arbeiten und Ressourcen auf. Wir danken filliptm für ComfyUI_Fill-ChatterBox und Resemble AI für Chatterbox für ihre Beiträge und Pflege. Für autoritative Details, konsultieren Sie bitte die originale Dokumentation und die unten verlinkten Repositories.
Ressourcen#
- filliptm/ComfyUI_Fill-ChatterBox
- GitHub: filliptm/ComfyUI_Fill-ChatterBox
- resemble-ai/chatterbox
- GitHub: resemble-ai/chatterbox
Hinweis: Die Nutzung der referenzierten Modelle, Datensätze und des Codes unterliegt den jeweiligen Lizenzen und Bedingungen der Autoren und Pfleger.