
1. About CogVideoX-5B#
CogVideoX-5B is a cutting-edge text-to-video diffusion model developed by Zhipu AI at Tsinghua University. As part of the CogVideoX series, this model creates videos directly from text prompts using advanced AI techniques such as a 3D Variational Autoencoder (VAE) and an Expert Transformer. CogVideoX-5B generates high-quality, temporally consistent results that capture complex motion and detailed semantics.
With CogVideoX-5B, you achieve exceptional clarity and fluidity. The model ensures seamless flow, capturing intricate details and dynamic elements with extraordinary accuracy. Leveraging CogVideoX-5B reduces inconsistencies and artifacts, leading to a polished and engaging presentation. The high-fidelity outputs of CogVideoX-5B facilitate the creation of richly detailed and coherent scenes from text prompts, making it an essential tool for top-tier quality and visual impact.
2. The Technique of CogVideoX-5B#
2.1 3D Causal Variational Autoencoder (VAE) of CogVideoX-5B#
The 3D Causal VAE is a key component of CogVideoX-5B, enabling efficient video generation by compressing video data both spatially and temporally. Unlike traditional models that use 2D VAEs to process each frame individually—often resulting in flickering between frames—CogVideoX-5B uses 3D convolutions to capture both spatial and temporal information at once. This approach ensures smooth and coherent transitions across frames.
The architecture of the 3D Causal VAE includes an encoder, a decoder, and a latent space regularizer. The encoder compresses video data into a latent representation, which the decoder then uses to reconstruct the video. A Kullback-Leibler (KL) regularizer constrains the latent space, ensuring the encoded video remains within a Gaussian distribution. This helps maintain high video quality during reconstruction.
Key Features of the 3D Causal VAE
- Spatial and Temporal Compression: The VAE compresses video data by a factor of 4x in the temporal dimension and 8x8 in the spatial dimensions, achieving a total compression ratio of 4x8x8. This reduces computational demands, allowing the model to process longer videos with fewer resources.
- Causal Convolution: To preserve the order of frames in a video, the model uses temporally causal convolutions. This ensures that future frames don't influence the prediction of current or past frames, maintaining the sequence's integrity during generation.
- Context Parallelism: To manage the high computational load of processing long videos, the model uses context parallelism in the temporal dimension, distributing the workload across multiple devices. This optimizes the training process and reduces memory usage.
2.2 Expert Transformer Architecture of CogVideoX-5B#
CogVideoX-5B's expert transformer architecture is designed to handle the complex interaction between text and video data effectively. It uses an adaptive LayerNorm technique to process the distinct feature spaces of text and video.
Key Features of the Expert Transformer
- Patchification: After the 3D Causal VAE encodes the video data, it's divided into smaller patches along the spatial dimensions. This process, called patchification, converts the video into a sequence of smaller segments, making it easier for the transformer to process and align with the corresponding text data.
- 3D Rotary Positional Embedding (RoPE): To capture spatial and temporal relationships within the video, CogVideoX-5B extends the traditional 2D RoPE to 3D. This embedding technique applies positional encoding to the x, y, and t dimensions of the video, helping the transformer effectively model long video sequences and maintain consistency across frames.
- Expert Adaptive LayerNorm (AdaLN): The transformer uses an expert adaptive LayerNorm to process the text and video embeddings separately. This allows the model to align the different feature spaces of text and video, enabling smooth fusion of these two modalities.
2.3 Progressive Training Techniques of CogVideoX-5B#
CogVideoX-5B uses several progressive training techniques to improve its performance and stability during video generation.
Key Progressive Training Strategies
- Mixed-Duration Training: The model is trained on videos of various lengths within the same batch. This technique enhances the model's ability to generalize, enabling it to generate videos of different durations while maintaining consistent quality.
- Resolution Progressive Training: The model is first trained on lower-resolution videos and then gradually fine-tuned on higher-resolution videos. This approach allows the model to learn the basic structure and content of videos before refining its understanding at higher resolutions.
- Explicit Uniform Sampling: To stabilize the training process, CogVideoX-5B uses explicit uniform sampling, setting different timestep sampling intervals for each data parallel rank. This method accelerates convergence and ensures the model learns effectively across the entire video sequence.
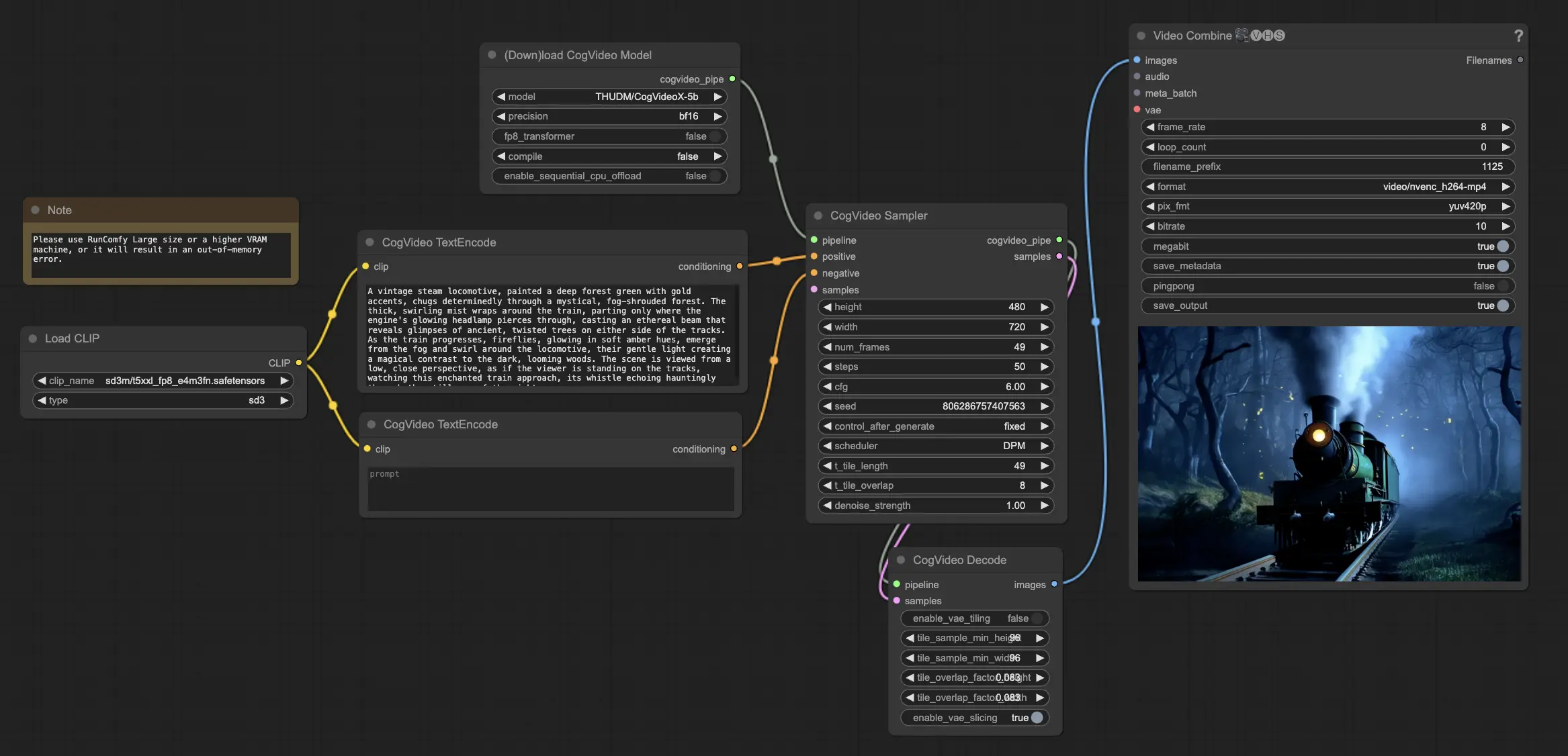
3. How to Use the ComfyUI CogVideoX-5B Workflow#
Step 1: Load the CogVideoX-5B Model#
Begin by loading the CogVideoX-5B model into the ComfyUI workflow. The CogVideoX-5B models have been preload on RunComfy's platform.
Step 2: Input Your Text Prompt#
Enter your desired text prompt in the designated node to guide the CogVideoX-5B video generation process. CogVideoX-5B excels at interpreting and transforming text prompts into dynamic video content.
4. License Agreement#
The code of CogVideoX models is released under the Apache 2.0 License.
The CogVideoX-2B model (including its corresponding Transformers module and VAE module) is released under the Apache 2.0 License.
The CogVideoX-5B model (Transformers module) is released under the CogVideoX LICENSE.