
Qwen 圖像 LoRA 推理:在 ComfyUI 中訓練匹配的 AI 工具包推理#
Qwen 圖像 LoRA 推理是一個生產就緒的 RunComfy 工作流程,用於在 ComfyUI 中將 AI 工具包訓練的 LoRA 應用於 Qwen 圖像,並具有 訓練匹配 行為。它的核心是 RC Qwen Image (RCQwenImage)——一個由 RunComfy 構建的開源自訂節點(source),運行 Qwen 圖像特定的推理管道(而不是通用採樣器圖形),並通過 lora_path 和 lora_scale 插入您的適配器。
為什麼 Qwen 圖像 LoRA 推理在 ComfyUI 中看起來經常不同#
AI 工具包預覽是由模型特定的推理管道生成的,具有 Qwen 圖像自己的條件和指導實施。如果您將 Qwen 圖像採樣重建為通用 ComfyUI 圖形,通常會更改管道默認值(以及 LoRA 應用的確切路徑),因此相同的提示/步驟/種子仍然可能漂移。當輸出不匹配時,通常是管道層級的不匹配——而不是單個“錯誤的旋鈕”。
RCQwenImage 自訂節點的功能#
RCQwenImage 將 Qwen 圖像推理包裹在預覽對齊的管道中,並通過 lora_path / lora_scale 將您的 AI 工具包 LoRA 應用於該管道中,從而使採樣行為對於此模型系列保持一致。參考實施:`src/pipelines/qwen_image.py`。
如何使用 Qwen 圖像 LoRA 推理工作流程#
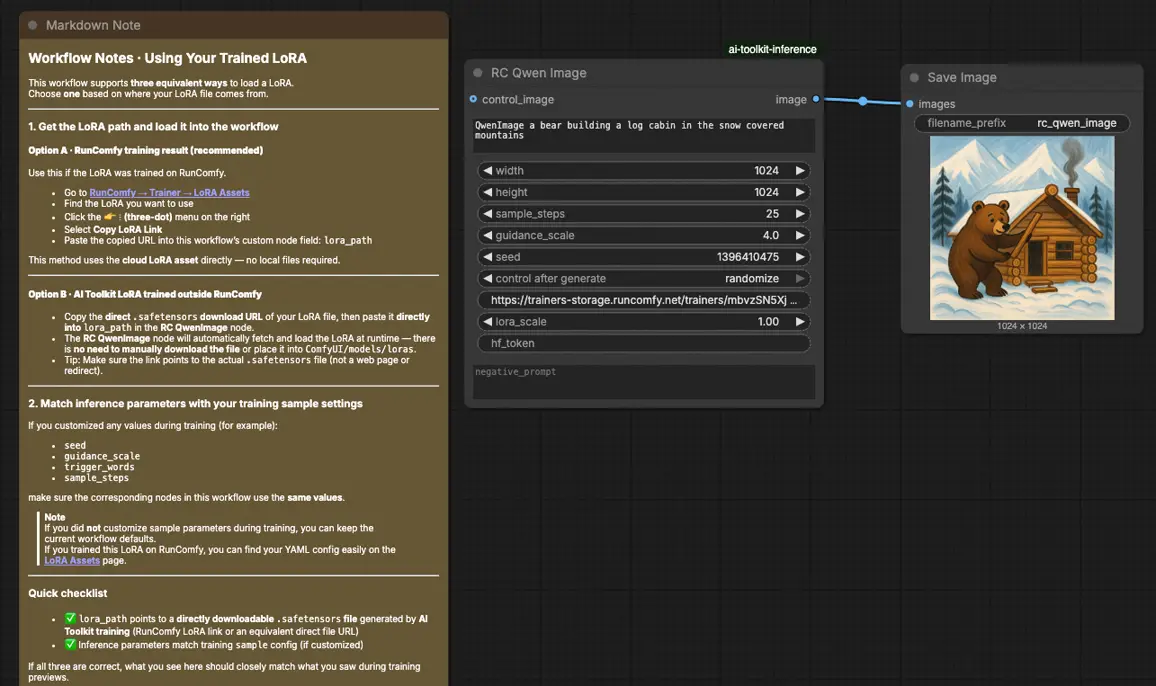
步驟 1:打開工作流程#
在 ComfyUI 中打開雲端保存的工作流程
步驟 2:導入您的 LoRA(2 種選擇)#
- 選項 A(RunComfy 訓練結果): RunComfy → Trainer → LoRA Assets → 找到您的 LoRA → ⋮ → 複製 LoRA 連結

- 選項 B(AI 工具包 LoRA 在 RunComfy 外部訓練): 複製 LoRA 的直接
.safetensors下載連結,並將該 URL 貼入lora_path(不需要下載到ComfyUI/models/loras)
步驟 3:配置 RCQwenImage 自訂節點以進行 Qwen 圖像 LoRA 推理#
設置節點的其餘參數(這些必須與您在比較結果時使用的 AI 工具包預覽採樣相匹配):
prompt:您的文本提示(包括您在訓練期間使用的相同觸發器令牌,如果有的話)negative_prompt:可選;如果您在訓練預覽中未使用負面則保持為空width/height:輸出解析度(建議使用 32 的倍數適用於 Qwen 圖像)sample_steps:Qwen 圖像管道使用的推理步驟數guidance_scale:指導強度(Qwen 圖像使用“真 CFG”比例;開始時先鏡像您的預覽值再調整)seed:固定種子以便重複性;僅在確認基線後更改lora_scale:LoRA 強度(從您的預覽強度開始,然後小幅調整)
訓練對齊注意事項:如果您調整了訓練樣本設置,請打開您的 AI 工具包訓練 YAML 並鏡像 width, height, sample_steps, guidance_scale, 和 seed。如果您在 RunComfy 上進行訓練,請使用 Trainer → LoRA Assets → 配置以將相同的預覽值複製到 RCQwenImage 中。

步驟 4:運行 Qwen 圖像 LoRA 推理#
排隊工作流程,然後運行它。SaveImage 節點將生成的圖像寫入您的標準 ComfyUI 輸出目錄。
Qwen 圖像 LoRA 推理故障排除#
大多數人在 Ostris AI 工具包 中訓練 Qwen 圖像 LoRA 後再嘗試在 ComfyUI 中運行時遇到的問題歸結於 管道 + LoRA 注入不匹配。
RunComfy 的 RC Qwen Image (RCQwenImage) 自訂節點旨在通過運行 Qwen 圖像特定推理管道(而不是通用採樣器圖形)並在 該管道中 通過 lora_path / lora_scale 注入您的適配器來使推理保持 管道對齊 與 AI 工具包預覽採樣。
(1)Qwen-Image Loras 在 comfyui 中不起作用#
為什麼會發生這種情況
這通常報告為:
- 許多
lora key not loaded警告,和/或 - LoRA “運行”但輸出沒有像在 AI 工具包採樣中那樣改變。
實際上,使用者發現這通常來自於 ComfyUI 尚未包含最新 Qwen LoRA 鍵映射的版本,或者 通過不匹配工作流程使用的 Qwen 圖像模塊名稱的通用路徑加載 LoRA。
如何修復
- 將 ComfyUI 切換到“夜間 / 開發”頻道並更新,然後重新運行相同的工作流程。多位用戶報告這樣可以去除
lora key not loaded垃圾信息並使 Qwen-Image LoRAs 正確應用。 - 使用 RCQwenImage 並僅通過
lora_path/lora_scale傳遞 LoRA(避免在其上堆疊額外的 LoRA 加載節點)。RCQwenImage 保持 管道層級的 LoRA 注入點 與 AI 工具包風格推理一致。 - 與 AI 工具包預覽進行比較時,精確鏡像預覽採樣器值:
width,height,sample_steps,guidance_scale,seed, 和lora_scale。
(2)使用 Qwen lighting 8 步驟 Lora 的 Qwen 圖像生成和質量輸出問題#
為什麼會發生這種情況
有人報告更新 ComfyUI 後,Qwen 圖像輸出變得扭曲或“怪異”,並且控制台顯示 lora key not loaded 用於 Lightning 8 步驟 LoRA——這意味著速度/質量 LoRA 可能 實際上沒有被應用,即使圖像仍然生成。
如何修復(用戶驗證 + 訓練匹配)
- 切換到 ComfyUI 夜間版並更新。這是最一致報告的修復
lora key not loaded與 Qwen-Image Lightning LoRAs 的方法。 - 如果您使用的是原生 Comfy 工作流程,用戶報告成功地在模型加載器和模型採樣節點之間插入
LoraLoaderModelOnly在最新的夜間版中。 - 對於訓練預覽匹配(AI 工具包),首先通過 RCQwenImage 驗證(管道對齊),然後僅在基線匹配後調整
lora_scale。
(3)Qwen 圖像角色 LoRA 與訓練樣本不同#
為什麼會發生這種情況
常見報告是:AI 工具包訓練樣本看起來不錯,但在 ComfyUI 中 LoRA “幾乎沒有影響”。對於 Qwen 圖像,這通常意味著:
- LoRA 沒有真正被應用(通常伴隨著
lora key not loaded/ 過時的 Qwen 支持),或者 - LoRA 是通過圖形/加載器路徑加載的,這不符合 Qwen 圖像期望模塊被修補的方式。
如何修復(用戶驗證 + 訓練匹配)
- 通過 RCQwenImage 驗證 LoRA(單節點,管道對齊注入通過
lora_path/lora_scale)。如果 LoRA 效果在這裡顯示但不在您的手動圖形中顯示,您已確認是 管道/加載器不匹配 而不是訓練失敗。 - 當匹配 AI 工具包預覽樣本時,在診斷時不要更改解析度/步驟/指導/種子。首先匹配預覽採樣器值,然後小幅調整
lora_scale。
現在運行 Qwen 圖像 LoRA 推理#
打開 RunComfy 工作流程,設置 lora_path,並運行 RCQwenImage 以保持 Qwen 圖像 LoRA 推理在 ComfyUI 中與您的 AI 工具包訓練預覽對齊。
