
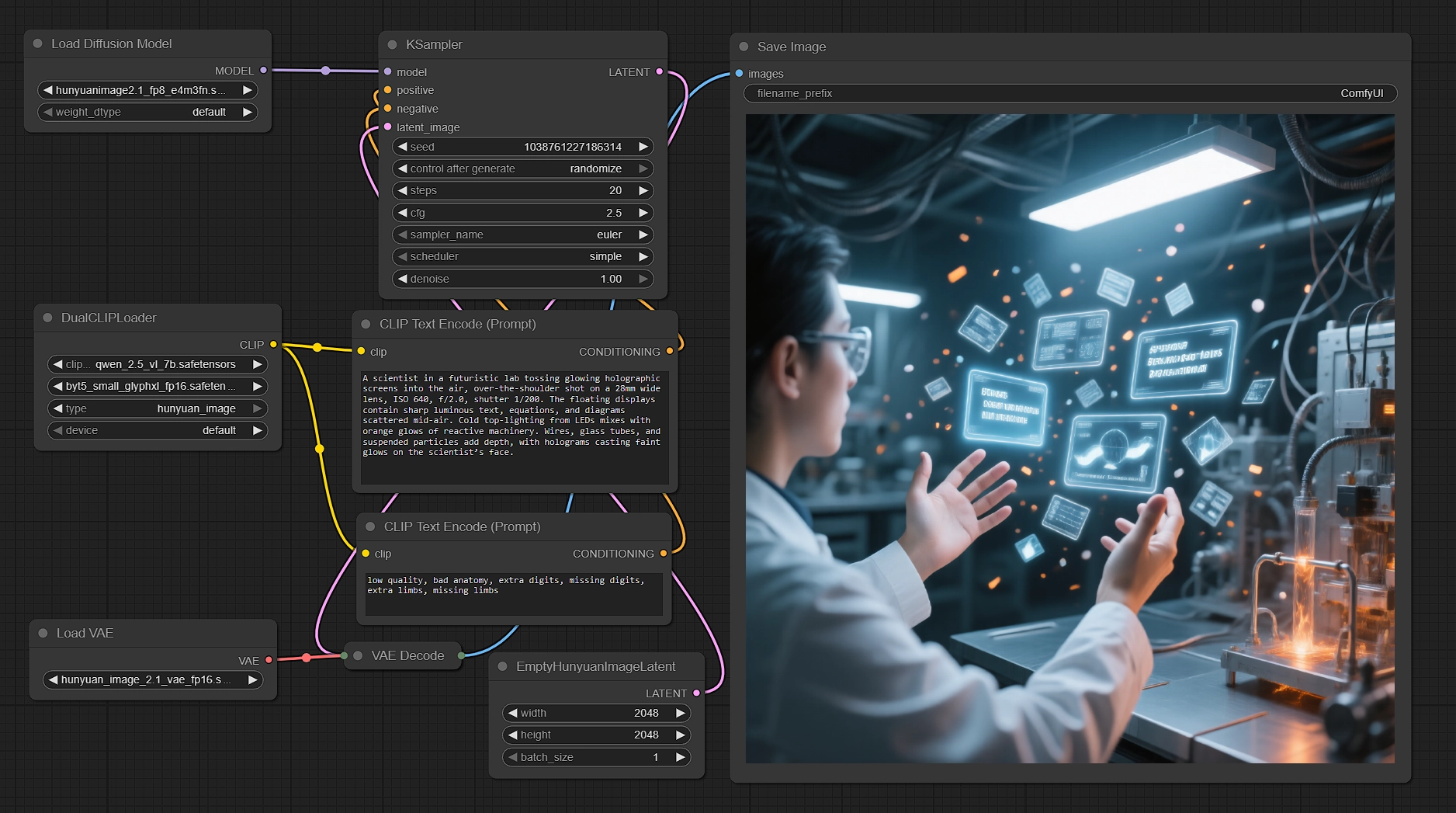










使用 Hunyuan Image 2.1 在 ComfyUI 中生成原生2K圖像#
此工作流程利用 Hunyuan Image 2.1 將您的提示轉換為清晰的原生2048×2048 渲染。它將騰訊的擴散變壓器與雙文本編碼器配對,以提高語義對齊和文本渲染質量,然後通過匹配的高壓縮 VAE 進行高效取樣和解碼。如果您需要生產就緒的場景、角色和圖像中清晰的文本,並同時保留速度和控制,這個 ComfyUI Hunyuan Image 2.1 工作流程專為您而設。
創作者、藝術總監和技術藝術家可以插入多語言提示,微調幾個旋鈕,並始終如一地獲得銳利的結果。該圖形配有合理的負面提示、原生2K畫布和FP8 UNet,以保持 VRAM 在控制範圍內,展示了 Hunyuan Image 2.1 的即時效果。
Comfyui Hunyuan Image 2.1 工作流程中的關鍵模型#
- HunyuanImage‑2.1 由騰訊提供。基本文本轉圖像模型,具有擴散變壓器骨幹、雙文本編碼器、32× VAE、RLHF 後訓練和平均流蒸餾以提高取樣效率。鏈接:Hugging Face · GitHub
- Qwen2.5‑VL‑7B‑Instruct。多模態視覺語言編碼器,在此用作語義文本編碼器,以提高跨複雜場景和語言的提示理解。鏈接:Hugging Face
- ByT5 Small。無需標記的字節級編碼器,增強圖像中字符和字形處理的文本渲染。鏈接:Hugging Face · Paper
如何使用 Comfyui Hunyuan Image 2.1 工作流程#
該圖形從提示到像素遵循明確的路徑:用兩個編碼器編碼文本,準備原生2K潛在畫布,使用 Hunyuan Image 2.1 進行取樣,通過匹配的 VAE 解碼並保存輸出。
使用雙編碼器進行文本編碼#
DualCLIPLoader(#33) 加載配置為 Hunyuan Image 2.1 的 Qwen2.5‑VL‑7B 和 ByT5 Small。這種雙編碼器設置讓模型能夠解析場景語義,同時對字形和多語言文本保持穩健。- 在
CLIPTextEncode(#6) 中輸入您的主要描述。您可以用英語或中文撰寫,混合攝影提示和照明,並包括圖像中的文本說明。 CLIPTextEncode(#7) 中的即用型負面提示可以抑制常見工件。您可以根據自己的風格進行調整或保持原樣以獲得平衡的結果。
原生2K的潛在畫布#
EmptyHunyuanImageLatent(#29) 以單批次初始化2048×2048畫布。Hunyuan Image 2.1 專為2K生成而設計,因此建議使用原生2K尺寸以獲得最佳質量。- 如有需要,調整寬度和高度,保持 Hunyuan 支持的長寬比。對於其他比例,請堅持使用模型友好的尺寸以避免工件。
使用 Hunyuan Image 2.1 進行高效取樣#
UNETLoader(#37) 加載 FP8 检查點以減少 VRAM 同時保持保真度,然後將其提供給KSampler(#3) 進行去噪。- 使用編碼器中的正負條件來引導構圖和清晰度。調整種子以獲得多樣性,調整步驟以獲得質量與速度的平衡,並調整指導以符合提示。
- 工作流程專注於基礎模型路徑。Hunyuan Image 2.1 還支持精細化階段;如果您想要額外的精細度,您可以稍後添加一個。
解碼並保存#
VAELoader(#34) 引入 Hunyuan Image 2.1 VAE,VAEDecode(#8) 使用模型的32×壓縮方案從取樣潛在圖像中重建最終圖像。SaveImage(#9) 將輸出寫入您選擇的目錄。如果您計劃跨種子或提示進行迭代,請設置清晰的文件名前綴。
Comfyui Hunyuan Image 2.1 工作流程中的關鍵節點#
DualCLIPLoader (#33)#
此節點加載 Hunyuan Image 2.1 所需的文本編碼器對。保持模型類型設置為 Hunyuan,並選擇 Qwen2.5‑VL‑7B 和 ByT5 Small 以結合強大的場景理解和字形感知文本處理。如果您在風格上進行迭代,請配合指導調整正面提示,而不是更換編碼器。
CLIPTextEncode (#6 和 #7)#
這些節點將您的正面和負面提示轉換為條件。保持正面提示在最上方簡潔,然後添加鏡頭、照明和風格提示。使用負面提示抑制如額外肢體或噪聲文本等工件;如果您覺得它對您的概念過於限制,可以進行修剪。
EmptyHunyuanImageLatent (#29)#
定義工作分辨率和批次。默認的2048×2048與 Hunyuan Image 2.1 的原生2K能力對齊。對於其他長寬比,選擇模型友好的寬高對,並考慮在遠離正方形時略微增加步驟。
KSampler (#3)#
驅動 Hunyuan Image 2.1 的去噪過程。當您需要更精細的微細節時增加步驟,快速草稿則減少。提高指導以獲得更強的提示符合性,但要注意過度飽和或僵化;降低以獲得更自然的變化。更換種子以探索不同的構圖,而不改變您的提示。
UNETLoader (#37)#
加載 Hunyuan Image 2.1 UNet。包含的 FP8 檢查點保持記憶體使用量適中,以便輸出2K。如果您有足夠的 VRAM 並希望為激進設置提供最大空間,請考慮從官方發布中選擇高精度版本的相同模型。
VAELoader (#34) 和 VAEDecode (#8)#
這些節點必須與 Hunyuan Image 2.1 發布版本匹配才能正確解碼。模型的高壓縮 VAE 是快速2K生成的關鍵;配對正確的 VAE 可以避免顏色偏移和塊狀紋理。如果您更改基礎模型,請務必相應更新 VAE。
可選附加項#
- 提示
- Hunyuan Image 2.1 對結構化提示反應良好:主題、動作、環境、鏡頭、照明和風格。對於圖像中的文本,請引用您想要的準確字詞並保持簡短。
- 速度和內存
- FP8 UNet 已經很高效。如果您需要進一步壓縮,請禁用大型批次並偏好較少的步驟。圖形中有可選的 GGUF 加載器節點,但默認禁用;高級用戶可以在試驗量化檢查點時將其替換。
- 長寬比
- 堅持使用原生2K友好的尺寸以獲得最佳效果。如果您冒險進入寬或高格式,請驗證清晰的渲染並考慮略微增加步驟。
- 精細化
- Hunyuan Image 2.1 支持精細化階段。要嘗試,請在基礎通過後添加第二個取樣器,使用精細化檢查點和輕微去噪,以在提高微細節的同時保持結構。
- 參考
- Hunyuan Image 2.1 模型詳情和下載:Hugging Face · GitHub
- Qwen2.5‑VL‑7B‑Instruct:Hugging Face
- ByT5 Small 和論文:Hugging Face · Paper
致謝#
此工作流程實現並基於以下作品和資源構建。我們感謝 @Ai Verse 和 Hunyuan 提供的 Hunyuan Image 2.1 演示的貢獻和維護。有關權威細節,請參閱下方鏈接的原始文檔和版本庫。
資源#
- Hunyuan/Hunyuan Image 2.1 演示
注意:使用參考的模型、數據集和代碼需遵守其作者和維護者提供的相關許可和條款。

