


1. ComfyUI LayerDiffuse 工作流程概述#
ComfyUI LayerDiffuse 工作流程整合了三個專門的子工作流程:創建透明圖像、從前景生成背景,以及根據現有背景生成前景的逆向過程。每個 LayerDiffuse 子工作流程獨立運行,提供你選擇並啟用符合創意需求的特定 LayerDiffuse 功能的靈活性。
1.1. 使用 LayerDiffuse 創建透明圖像:#
此工作流程允許直接創建透明圖像,提供你生成有或無指定 alpha 通道遮罩的圖像的靈活性。
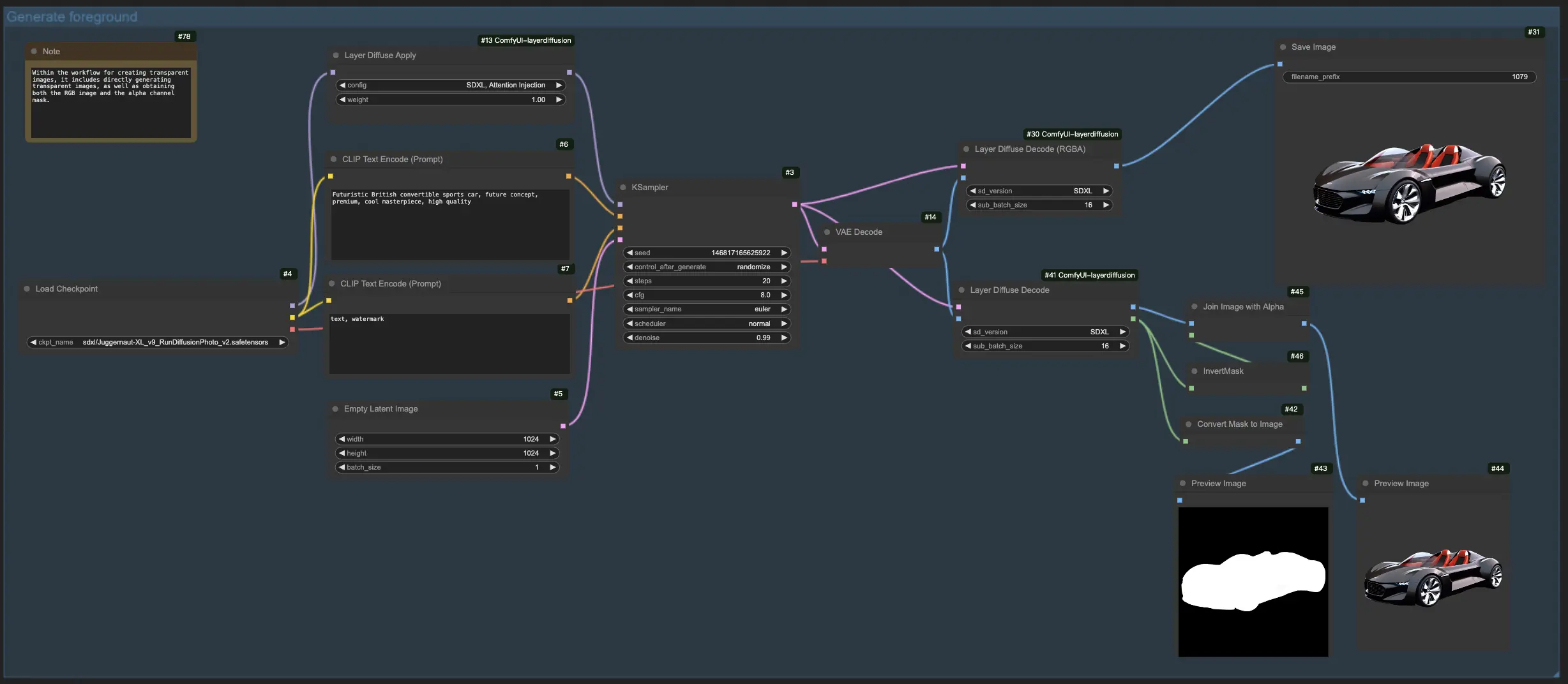
1.2. 使用 LayerDiffuse 從前景生成背景:#
對於此 LayerDiffuse 工作流程,首先上傳你的前景圖像並撰寫描述性提示。然後,LayerDiffuse 將這些元素融合以生成你所期望的圖像。在為 LayerDiffuse 撰寫提示時,務必詳細描述完整場景(例如,"一輛車停在街道旁"),而不僅僅是描述背景元素(例如,"街道")。
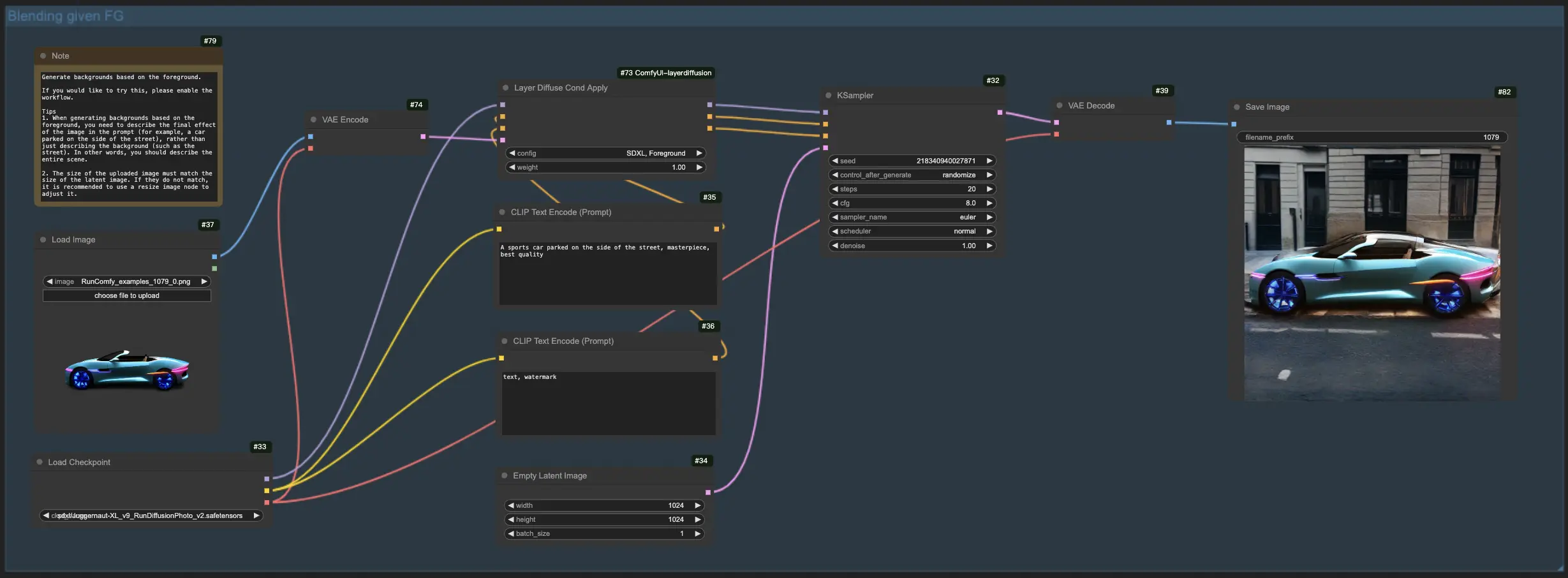
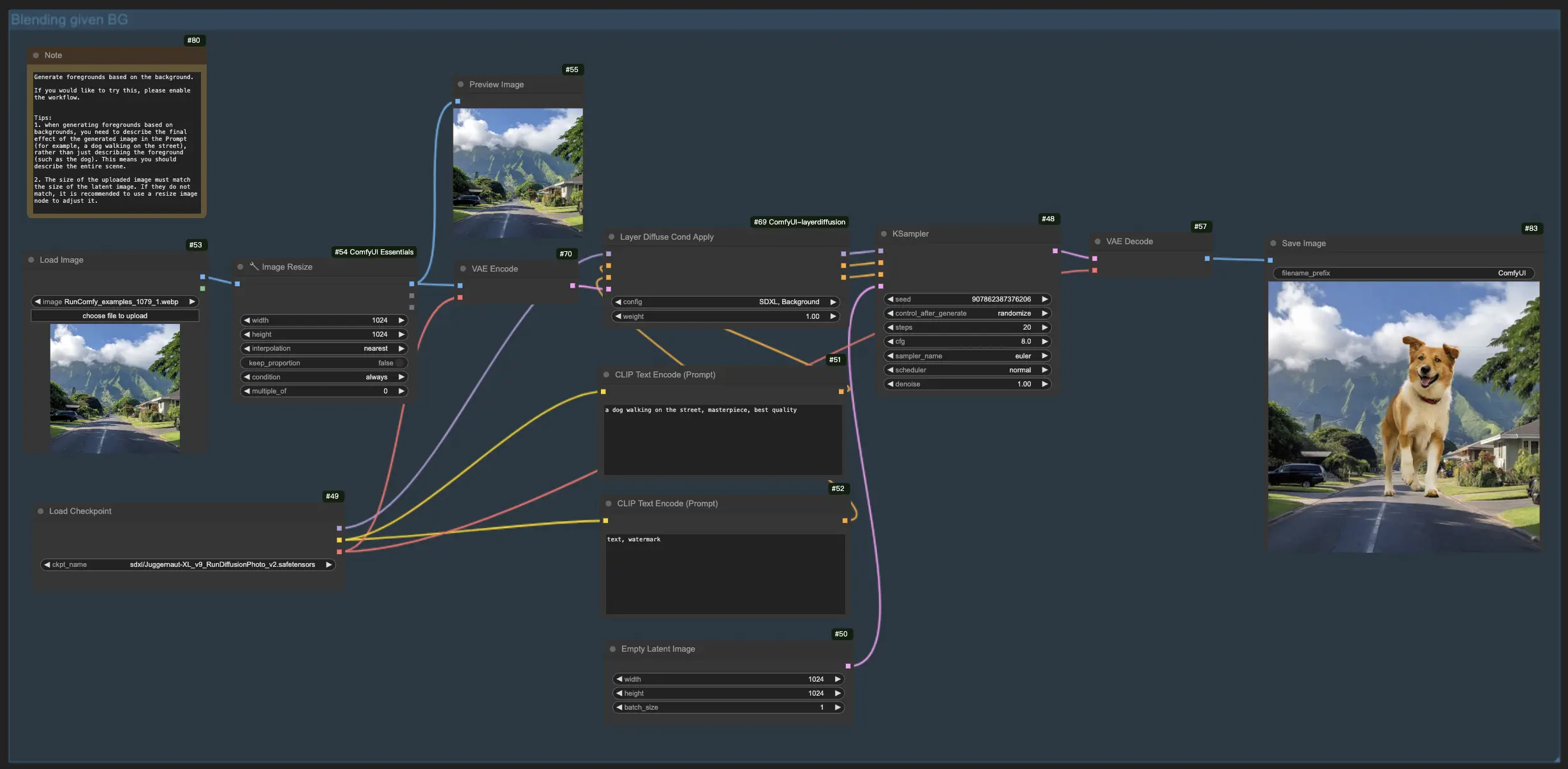
1.3. 基於背景生成前景:#
與之前的工作流程類似,這一 LayerDiffuse 功能反轉了焦點,旨在將前景元素與現有背景合併。因此,你需要上傳背景圖像並在提示中描述預想的最終圖像,強調完整的場景(例如,"一隻狗在街上行走"),而非單一元素(例如,"狗")。
更多 LayerDiffuse 工作流程,請查看 github
2. LayerDiffuse 工作流程效能#
創建透明圖像的過程穩健且能可靠地產生高質量的結果,而背景與前景融合的工作流程則更具實驗性。它們可能無法始終達到完美融合,這表明了此技術的創新但仍在發展的特質。
3. LayerDiffuse 的技術介紹#
LayerDiffuse 是一種創新方法,旨在使大型預訓練潛在擴散模型生成具有透明度的圖像。此技術引入了"潛在透明度"的概念,涉及將 alpha 通道透明度直接編碼到現有模型的潛在流形中。這允許創建透明圖像或多個透明層,而不顯著改變預訓練模型的原始潛在分佈。目標是保持這些模型的高質量輸出,同時增加生成具有透明度的圖像的能力。
為達到此目的,LayerDiffuse 通過調整其潛在空間以包括作為潛在偏移的透明度來微調預訓練潛在擴散模型。這個過程對模型的變更極少,保持了其原有的品質和性能。LayerDiffuse 的訓練使用了一個由 100 萬個透明圖像層對組成的數據集,通過人工介入的方案收集,以確保多樣的透明效果。
此方法已證明可適應於各種開源圖像生成器,並可整合到不同的條件控制系統中。這種多樣性允許一範圍的應用,例如生成具有前景/背景特定透明度的圖像、創建具有聯合生成能力的層,以及控制層的結構內容。








