
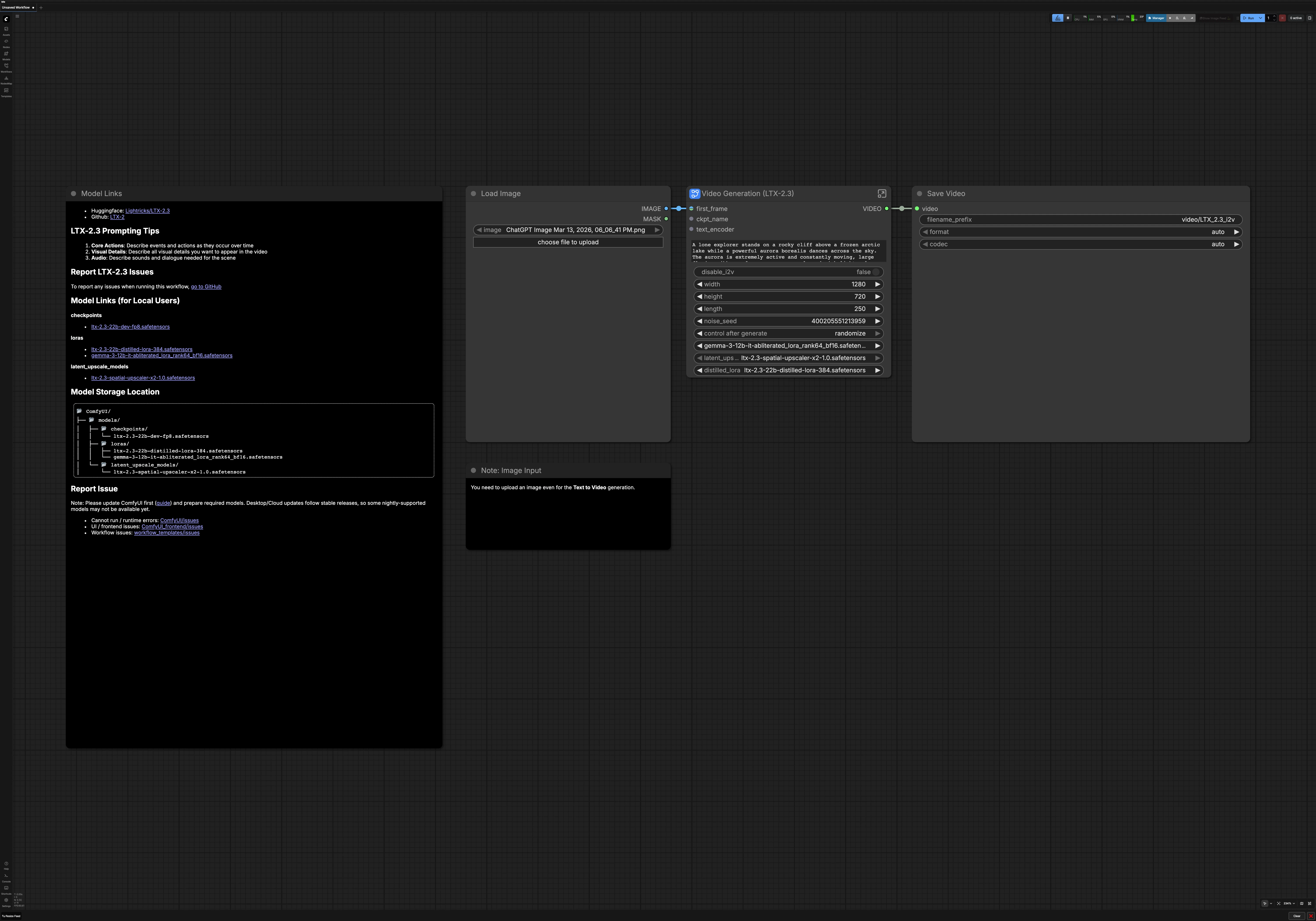
LTX 2.3 图像转视频在 ComfyUI#
这个工作流程将单张图像或纯文本提示转换为流畅的电影 AI 视频,使用 LTX 2.3 图像转视频。它专为希望高视觉连贯性、强场景一致性和精致运动而无需手动接线的创作者构建。可以在 RunComfy 或任何 ComfyUI 环境中使用,生成动态、风格化的结果,忠实于您的提示。
图表支持两种创意模式:以第一帧为视觉锚点的图像转视频,或完全由语言引导的文本转视频。它还包括自动提示增强、潜在上采样以获得更清晰的细节,以及可选的音频解码,使您的最终 LTX 2.3 图像转视频渲染准备发布。
ComfyUI LTX 2.3 图像转视频工作流程中的关键模型#
- Lightricks LTX 2.3 22B 视频模型。核心视频扩散转换器,从文本和可选图像指导中合成时间一致的运动和视觉。模型文件和文档可在 Hugging Face 上获得,代码级参考在 GitHub 上。
- LTX Audio VAE。音频变分自动编码器,用于将模型的音频潜在解码为音轨,以与帧合并。与 LTX 2.3 版本一起分发在 Hugging Face 上。
- LTX 2.3 空间上采样器 x2。潜在空间超分辨率模型,在最终高分辨率采样之前提高清晰度和空间保真度。可在 LTX 2.3 仓库中获得,位于 Hugging Face 上。
- Gemma 3 12B Instruct 文本编码器和 LoRA。一个紧凑的指令调优文本编码器和 LoRA,用于改进视频的提示理解和措辞。此模板使用的打包编码器和 LoRA 权重在 Comfy-Org LTX-2 资产中提供,位于 Hugging Face 上。
如何使用 ComfyUI LTX 2.3 图像转视频工作流程#
在高层次上,您的提示和可选的第一帧被编码,低分辨率潜在视频被采样,然后在潜在空间中上采样并在更高分辨率下优化。结果被解码为帧和音频,然后合成为最终的 MP4。您可以在运行之前随时在图像转视频和文本转视频之间切换。
- 模型
- 这组加载 LTX 2.3 检查点、音频 VAE 和文本编码器。它还将 LTX 2.3 LoRA 应用于基础模型以改善指令跟随。它们共同定义了 LTX 2.3 图像转视频管道的基础。除非您交换模型变体或 LoRA 样式,否则通常不会更改此处的任何内容。
- 提示
- 输入您的场景描述和可选的否定。文本被编码用于正面和负面条件,并与您选择的帧率配对,以便运动规划与时间保持一致。使用动词来描述变化,以保持语言与时间相关,例如“相机向前推进”或“叶子在风中旋转”。负面提示有助于避免不需要的伪影,如水印或卡通化简化。
- 提示增强
- 图表包括一个助手,分析您的图像和文本,然后生成一个更强的、时间感知的提示草稿,您可以采纳或编辑。这使得 LTX 2.3 图像转视频更容易朝向电影化、动作驱动的描述。尤其当您从单个静止图像开始并希望运动感觉有意时,它非常有用。预览节点允许您在生成之前检查增强的文本。
- 视频设置
- 选择是运行图像转视频还是通过简单的切换切换到文本转视频。设置宽度、高度、持续时间和帧率以适应您的目标平台。这些设置驱动潜在分配和下游解码,因此请保持它们与您的创意意图同步。如果您计划广泛发布,请优先考虑编解码器友好的尺寸和时间。
- 图像预处理
- 您的第一帧被调整大小和标准化为模型友好的宽高比,同时保留构图。轻度预滤波有助于稳定边缘并减少压缩噪声,这可能导致运动期间的闪烁。即使您仅使用图像来建议布局和颜色,这一步也很重要。
- 空潜在
- 工作流程根据您的尺寸、持续时间和帧率分配空的视频和音频潜在。这为采样器提供了干净的画布,并确保音频和视频保持长度对齐。当您想要可重现性时,噪声是确定性生成的,或者在运行之间随机化以进行变化。
- 生成低分辨率
- 第一次采样通过将运动和结构雕刻成紧凑的潜在视频。如果您使用图像转视频,
LTXVImgToVideoInplace(#249) 会将您的第一帧注入为视觉锚点,因此运动从连贯的起点演变。正面和负面的文本指导内容和风格,同时ManualSigmas(#252) 和KSamplerSelect定义噪声随着时间的推移被移除的激进程度。LTXVCropGuides(#212) 有助于保持与您的提示相匹配的构图。然后将生成的音视频潜在分割以进行单独处理。
- 第一次采样通过将运动和结构雕刻成紧凑的潜在视频。如果您使用图像转视频,
- 潜在上采样
- 在承诺进行高分辨率优化之前,
LTXVLatentUpsampler(#253) 将 x2 空间上采样器应用于低分辨率潜在。在潜在空间中执行此操作快速且保留学习到的运动,同时提升细节容量。这是一种在不引入伪影的情况下增加清晰度的安全方法。
- 在承诺进行高分辨率优化之前,
- 生成高分辨率
- 第二个采样器在更大的空间尺寸上优化上采样的潜在,以锁定纹理、照明和小动作。在运行文本转视频时,早期的图像转视频步骤可以被绕过,
LTXVImgToVideoInplace(#230) 只需将潜在传递即可。VAEDecodeTiled(#251) 然后有效地将视频潜在解码为帧。与此同时,音频潜在通过 LTX Audio VAE 解码,因此两个流最终都保持帧准确。
- 第二个采样器在更大的空间尺寸上优化上采样的潜在,以锁定纹理、照明和小动作。在运行文本转视频时,早期的图像转视频步骤可以被绕过,
- 导出
CreateVideo(#242) 将帧和音频合并为单个视频,采用您选择的帧率。顶级SaveVideo节点将最终文件写入您的 ComfyUI 输出,以便您可以立即下载。您的 LTX 2.3 图像转视频渲染现在可以预览或发布。
ComfyUI LTX 2.3 图像转视频工作流程中的关键节点#
LTXVImgToVideoInplace(#249 和 #230)- 将静止图像转换为视频潜在或在禁用时传递潜在。当您希望第一帧定义布局、调色板和角色位置时使用它。如果您更喜欢运动仅从提示中出现,请切换文本转视频。操作员家族的文档在 ComfyUI 集成中维护,位于 GitHub 上。
LTXVConditioning(#239)- 将编码的正面和负面文本与您的帧率结合,生成引导内容和运动节奏的条件。倾向于简短、清晰的句子,描述随时间变化的内容,并将否定保留用于您经常看到并希望抑制的伪影。这个节点是调整风格和场景行为而不触及采样器的最有效位置。
- 使用
ManualSigmas(#252) 和KSamplerSelect- 噪声计划和采样器共同工作以权衡大运动和精细细节。较高的早期噪声鼓励更广泛的运动,而后期步骤巩固纹理。只有在您有良好的提示和图像指导时才调整这些。基础采样控制遵循标准 ComfyUI 语义,参见 LTX 仓库中的参考实现,位于 GitHub 上。
LTXVLatentUpsampler(#253)- 在潜在空间中应用 LTX 2.3 空间上采样器,以便您可以在下一阶段优化高分辨率。当您需要额外的清晰度或计划提供更大格式时使用它。x2 模型与 LTX 2.3 一起分发在 Hugging Face 上。
VAEDecodeTiled(#251) 和CreateVideo(#242)- 瓦片解码防止在更高分辨率下出现内存峰值,并确保一致的帧质量。然后
CreateVideo将帧和解码的音轨合成为最终的 MP4,采用您选择的帧率。保持您的帧率与条件期间使用的值一致,以避免回放漂移。
- 瓦片解码防止在更高分辨率下出现内存峰值,并确保一致的帧质量。然后
可选附加功能#
- 即使使用文本转视频,您仍然必须上传第一帧图像。切换将在生成期间忽略它,但 UI 需要一个占位符图像。
- 对于 LTX 2.3 图像转视频提示,请以核心动作开头,然后是视觉细节,然后是气氛。时间词如“缓慢地”、“突然地”和“继续”帮助模型规划运动。
- 使用否定提示避免叠加和 UI 伪影,如“水印”、“字幕”或“静止帧”。
- 如果风格看起来太强或太弱,请尝试不同的 LoRA 或调整其在 LoRA 加载器中的权重。您也可以移除 LoRA 以依靠基础模型的外观。
- 当在文本上迭代时,重用固定的噪声种子以便重现性,然后在锁定镜头后随机化以进行变化。
鸣谢#
此工作流程实现并构建在以下作品和资源之上。我们感谢 Lightricks 对 LTX-2.3 和 EyeForAILabs 对 EyeForAILabs YouTube 教程的贡献和维护。有关权威细节,请参阅下方链接的原始文档和仓库。
资源#
- Lightricks/LTX-2.3
- GitHub: Lightricks/LTX-2
- Hugging Face: Lightricks/LTX-2.3
- arXiv: LTX-2: Efficient Joint Audio-Visual Foundation Model
- EyeForAILabs/YouTube Tutorial
- Docs / Release Notes: EyeForAILabs YouTube Tutorial
注意:使用引用的模型、数据集和代码须遵循其作者和维护者提供的各自许可证和条款。
