
LTX 2.3 LoRA ComfyUI 推理:使用 LTX 2.3 管道的训练匹配 AI Toolkit LoRA 输出#
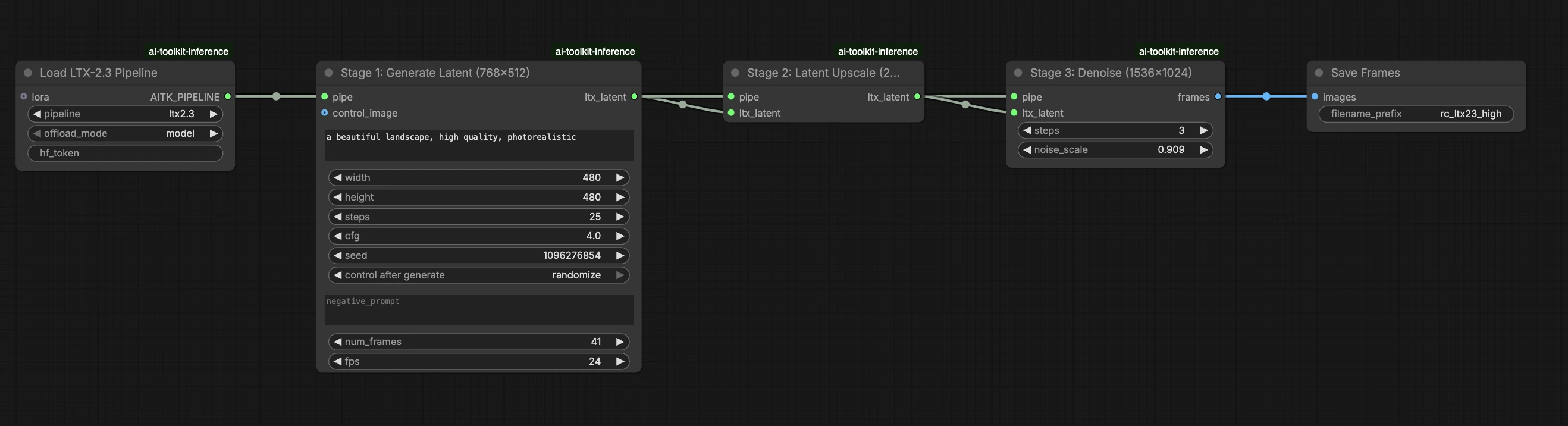
这个生产就绪的 RunComfy 工作流通过 RC LTX 2.3 (LTX2Pipeline) 在 ComfyUI 中运行 LTX 2.3 LoRA 推理(管道级对齐,不是通用采样器图)。RunComfy 构建并开源了这个自定义节点——请参阅 runcomfy-com repositories——您可以通过 lora_path 和 lora_scale 控制适配器应用。
注意:此工作流需要 2X Large 或更大的机器运行。
为什么 LTX 2.3 LoRA ComfyUI 推理在 ComfyUI 中经常看起来不同#
AI Toolkit 训练预览通过模型特定的 LTX 2.3 管道渲染,其中文本编码、调度和 LoRA 注入被设计为协同工作。在 ComfyUI 中,使用不同的图(或不同的 LoRA 加载路径)重建 LTX 2.3 可能会改变这些交互,因此即使复制相同的提示、步骤、CFG 和种子,仍然会产生可见的漂移。RunComfy RC 管道节点通过在 LTX2Pipeline 中端到端执行 LTX 2.3 并在该管道内应用您的 LoRA 来弥合这种差距,从而保持推理与预览行为一致。来源:RunComfy 开源库。
如何使用 LTX 2.3 LoRA ComfyUI 推理工作流#
步骤 1:获取 LoRA 路径并将其加载到工作流中(2 种选择)#
选项 A — RunComfy 训练结果 → 下载到本地 ComfyUI:
- 前往 Trainer → LoRA Assets
- 找到您想使用的 LoRA
- 点击右侧的 ⋮ (三点) 菜单 → 选择 复制 LoRA 链接
- 在 ComfyUI 工作流页面,将复制的链接粘贴到 UI 右上角的 下载 输入字段
- 在点击下载之前,确保目标文件夹设置为 ComfyUI > models > loras(必须选择此文件夹为下载目标)
- 点击 下载 — 这确保 LoRA 文件被保存到正确的
models/loras目录中 - 下载完成后,刷新页面
- LoRA 现在出现在工作流中的 LoRA 选择下拉菜单中 — 选择它
选项 B — 直接 LoRA URL(覆盖选项 A):
- 将 直接
.safetensors下载 URL 粘贴到 LoRA 节点的path / url输入字段中 - 当此处提供 URL 时,它覆盖选项 A — 工作流在运行时直接从 URL 加载 LoRA
- 不需要本地下载或文件放置
提示:确认 URL 解析到实际的 .safetensors 文件(而不是登录页面或重定向)。
步骤 2:将推理参数与您的训练样本设置匹配#
在 LoRA 节点中,选择您的适配器在 lora_path(选项 A),或在 path / url 中粘贴一个直接 .safetensors 链接(选项 B 覆盖下拉菜单)。然后将 lora_scale 设置为您在训练预览中使用的相同强度,并从那里进行调整。
其余参数在 Generate 节点上(并且,取决于图,可能在 Load Pipeline 节点上):
prompt:您的文本提示(如果您使用触发词进行训练,请包含它们)width/height:输出分辨率;匹配您的训练预览尺寸以获得最干净的对比(建议使用 LTX 2.3 的 32 的倍数)num_frames:输出视频帧数sample_steps:推理步骤数(30 是常见的默认值)guidance_scale:CFG/引导值(5.5 是常见的默认值;不要超过 7)seed:固定种子以重现;更改它以探索变化seed_mode(仅在存在时):选择fixed或randomizeframe_rate:输出 FPS;保持与训练设置一致以实现运动对齐
训练对齐提示:如果您在训练期间自定义了采样值(seed、guidance_scale、sample_steps、触发词、分辨率),请在此处镜像这些确切的值。如果您在 RunComfy 上进行训练,请打开 Trainer → LoRA Assets > 配置以查看已解析的 YAML 并将预览/样本设置复制到工作流节点中。
步骤 3:运行 LTX 2.3 LoRA ComfyUI 推理#
点击 Queue/Run — SaveVideo 节点将结果写入您的 ComfyUI 输出文件夹。
快速检查清单:
- ✓ LoRA 通过以下方式下载:下载到
ComfyUI/models/loras(选项 A),或通过直接.safetensorsURL 加载(选项 B) - ✓ 本地下载后刷新页面(仅限选项 A)
- ✓ 推理参数匹配训练
sample配置(如果自定义)
如果以上所有内容正确,这里的推理结果应该与您的训练预览非常接近。
LTX 2.3 LoRA ComfyUI 推理的故障排除#
大多数 LTX 2.3 "训练预览与 ComfyUI 推理" 差距来自 管道级差异(模型的加载方式、调度方式以及 LoRA 的合并方式),而不是单个错误的旋钮。 这个 RunComfy 工作流通过在 RC LTX 2.3 (LTX2Pipeline) 中端到端运行推理并通过 lora_path / lora_scale 应用您的 LoRA(而不是堆叠通用加载器/采样器节点)来恢复最接近的 "训练匹配" 基线。
(1) LoRA 形状不匹配或 "key not loaded" 警告#
为什么会发生这种情况 LoRA 是为不同的模型家族或不同的 LTX 变体训练的。您将看到许多 lora key not loaded 行,可能还有形状不匹配错误。
如何修复(推荐)
- 确保 LoRA 是专门为 LTX 2.3 使用 AI Toolkit 训练的(LTX 2.0 / 2.1 / 2.2 LoRAs 不能互换)。
- 保持图 "单路径" 用于 LoRA:仅通过工作流的
lora_path输入加载适配器,并让 LTX2Pipeline 处理合并。不要并行堆叠额外的通用 LoRA 加载器。 - 如果您已经遇到了不匹配,并且 ComfyUI 之后开始产生无关的 CUDA/OOM 错误,请重启 ComfyUI 进程以完全重置 GPU + 模型状态,然后使用兼容的 LoRA 重试。
(2) 推理结果与训练预览不匹配#
为什么会发生这种情况 即使 LoRA 加载,结果仍可能漂移,如果您的 ComfyUI 图不匹配训练预览管道(不同的默认设置,不同的 LoRA 注入路径,不同的调度)。
如何修复(推荐)
- 使用此工作流并将您的直接
.safetensors链接粘贴到lora_path。 - 从您的 AI Toolkit 训练配置(或 RunComfy Trainer → LoRA Assets 配置)中复制采样值:
width、height、num_frames、sample_steps、guidance_scale、seed、frame_rate。 - 除非您在训练/采样时使用了它们,否则不要将 "额外速度堆栈" 纳入对比。
(3) 使用 LoRAs 显著增加推理时间#
为什么会发生这种情况 当 LoRA 路径强制额外的修补/去量化工作或在比基础模型单独应用权重的更慢的代码路径中应用权重时,LoRA 可以使 LTX 2.3 慢得多。
如何修复(推荐)
- 使用此工作流的 RC LTX 2.3 (LTX2Pipeline) 路径,并通过
lora_path/lora_scale传递您的适配器。在这种设置中,LoRA 在管道加载期间合并 一次(AI Toolkit 风格),因此 每步采样成本 接近基础模型。 - 当您追求预览匹配行为时,避免堆叠多个 LoRA 加载器或混合加载路径。保持为 一个
lora_path+ 一个lora_scale,直到基线匹配。
(4) 大分辨率或长视频上的 OOM 错误#
为什么会发生这种情况 LTX 2.3 是一个 22B 参数模型,视频生成是 VRAM 密集型的。高分辨率或多帧可能会超过 GPU 内存,尤其是在 LoRA 开销下。
如何修复(推荐)
- 使用 2X Large (80 GB VRAM) 或更大的机器。此工作流与 Medium、Large 或 X Large 机器不兼容。
- 如果您需要快速迭代,请降低分辨率或帧数,然后进行最终渲染时再放大。
- 如果可用,启用 VAE 平铺 — 它可以在质量损失最小的情况下节省约 3 GB VRAM。
立即运行 LTX 2.3 LoRA ComfyUI 推理#
打开工作流,设置 lora_path,然后点击 Queue/Run 以获得与您的 AI Toolkit 训练预览接近的 LTX 2.3 LoRA 结果。