
LatentSync 是一个最先进的端到端口型同步框架,利用音频条件的潜在扩散模型的力量,生成逼真的口型同步。LatentSync 的独特之处在于其能够直接建模音频和视觉组件之间复杂的关联,而无需依赖任何中间运动表示,革命性地改变了口型同步合成的方法。
LatentSync 流程的核心是 Stable Diffusion 的集成,这是一种强大的生成模型,以其卓越的捕捉和生成高质量图像的能力而著称。通过利用 Stable Diffusion 的能力,LatentSync 能够有效地学习和再现语音音频与相应口部运动之间的复杂动态,产生高度准确和令人信服的口型同步动画。
基于扩散的口型同步方法的一个关键挑战是保持生成帧之间的时间一致性,这对于实现逼真的结果至关重要。LatentSync 通过其突破性的时间表示对齐(TREPA)模块正面解决了这一问题,专门设计用于增强口型同步动画的时间连贯性。TREPA 使用先进技术从生成帧中提取时间表示,利用大规模自监督视频模型。通过将这些表示与真实帧对齐,LatentSync 的框架确保了高度的时间连贯性,产生显著平滑且令人信服的口型同步动画,与音频输入紧密匹配。
1.1 如何使用 LatentSync 工作流程?#
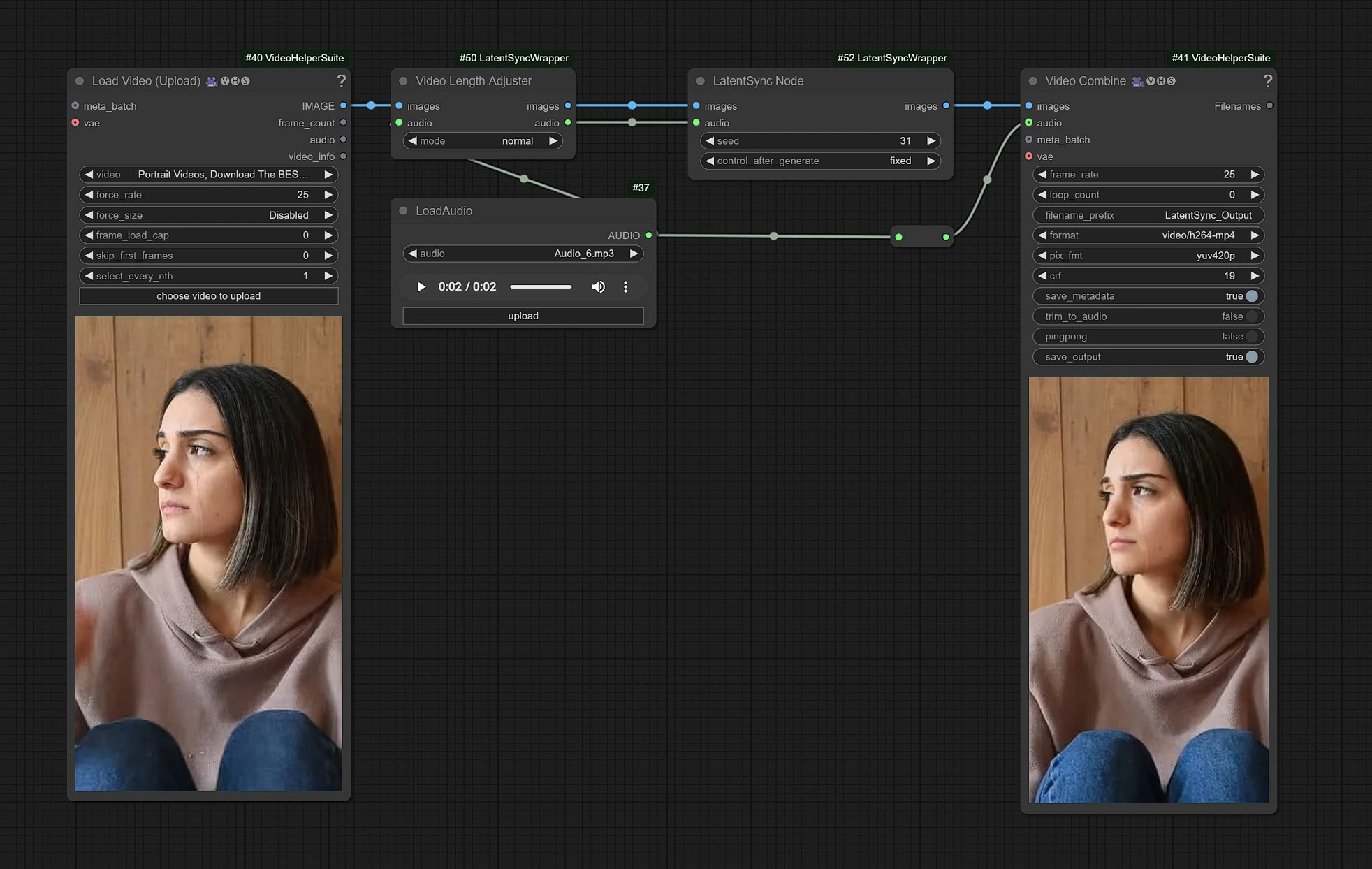
这是 LatentSync 的工作流程,左侧节点是上传视频的输入,中间是处理 LatentSync 节点,右侧是输出节点。
- 在输入节点上传您的视频。
- 上传您的对话音频输入。
- 点击渲染!!!
1.2 视频输入#
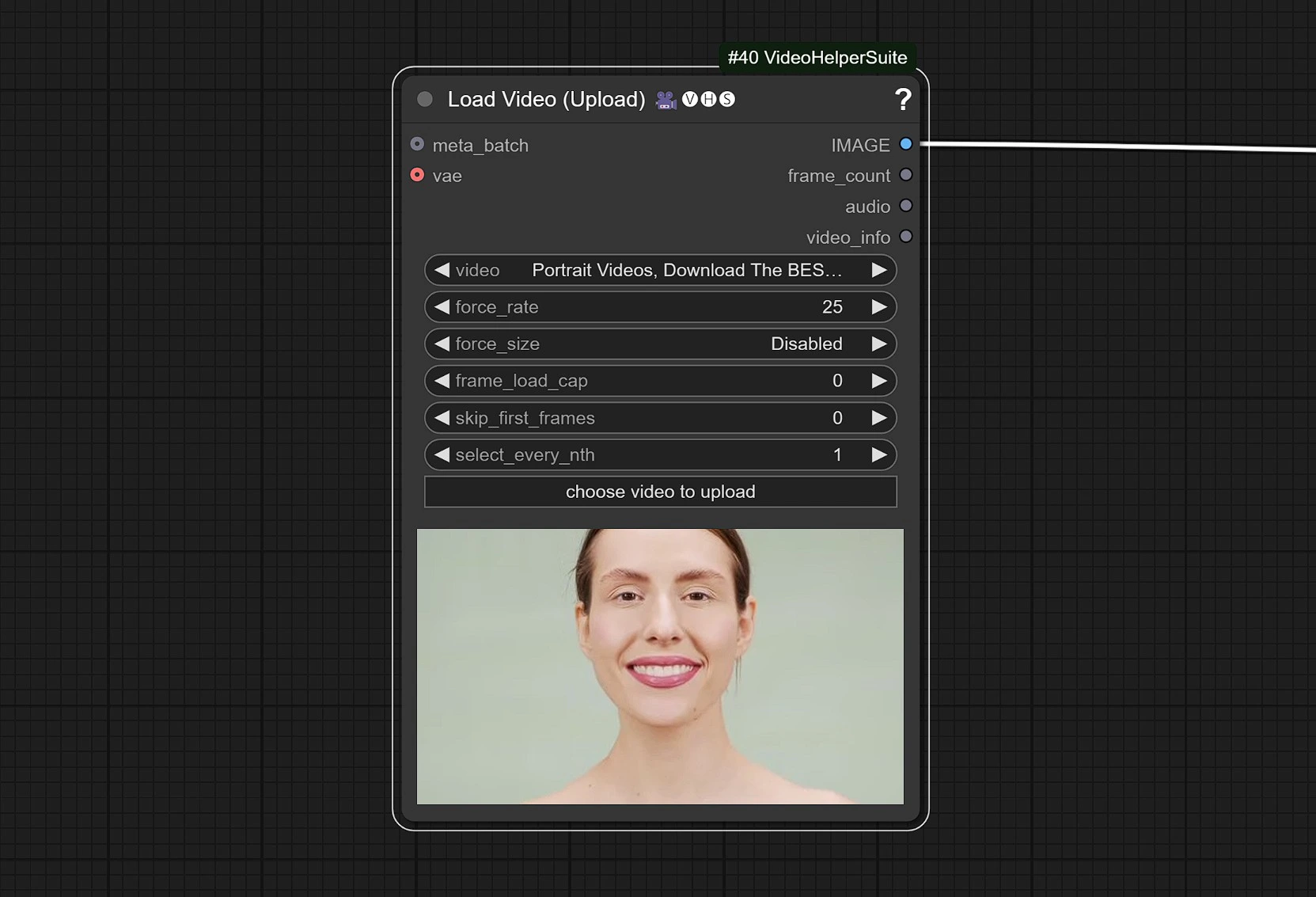
- 点击并上传包含面部的参考视频。
视频调整为 25 FPS,以便与音频模型正确同步。
1.3 音频输入#
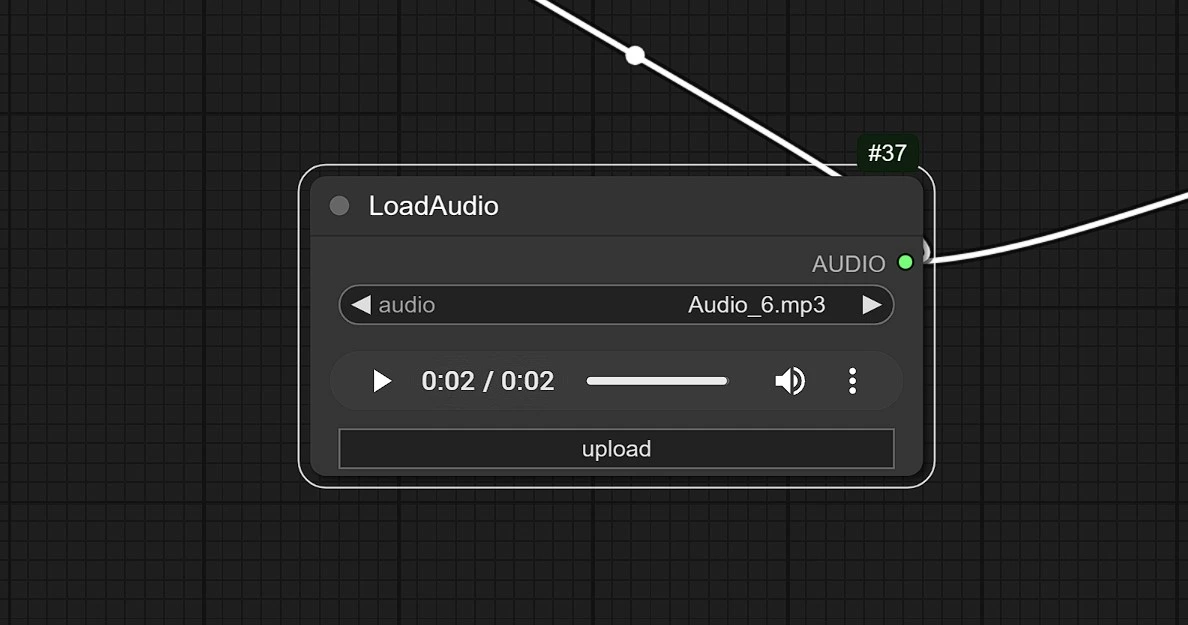
- 点击并在此处上传您的音频。
LatentSync 以其创新的音频视觉生成方法设定了口型同步的新基准。通过结合精确性、时间一致性和 Stable Diffusion 的力量,LatentSync 改变了我们创建同步内容的方式。使用 LatentSync 重新定义口型同步的可能性。