
daVinci-MagiHuman 用于 ComfyUI 的数字对话人类工作流程#
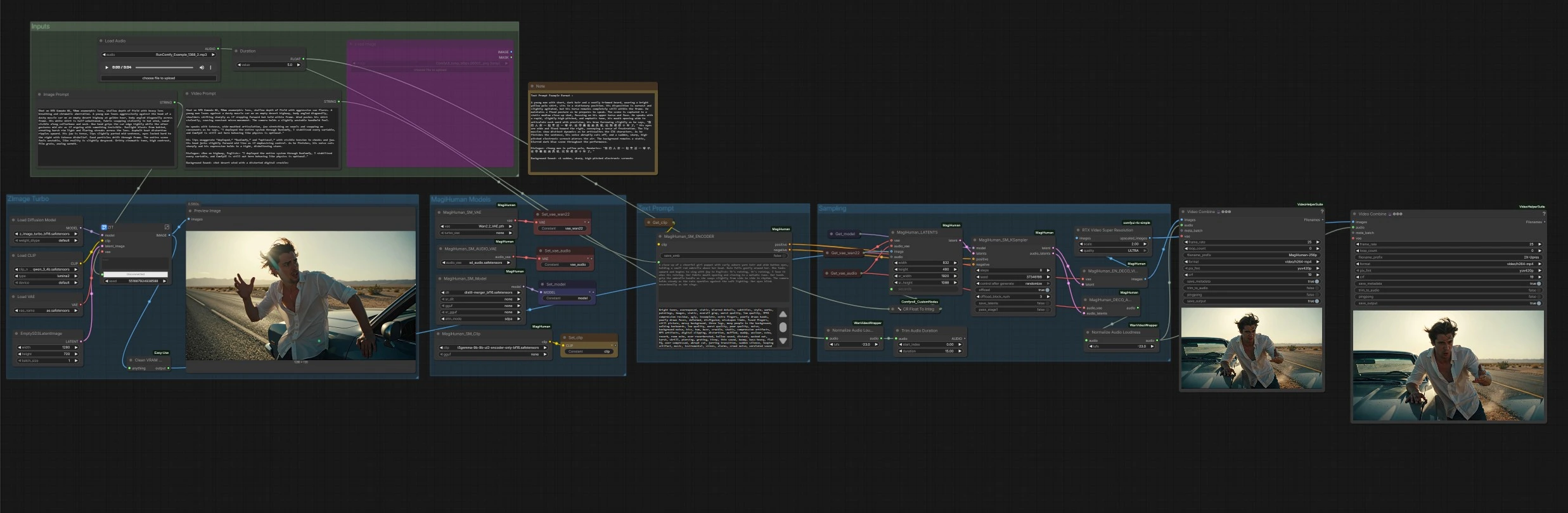
此 ComfyUI 工作流程围绕 daVinci-MagiHuman 构建了一个完整的文本到视频管道,以生成具有同步语音、唇部运动、表情和身体微运动的逼真数字人。它专为希望从描述性提示到带有清晰音频的 MP4 的快速单击路径的创作者而设计。图形可以为新生成的肖像或任何提供的参考图像制作动画,然后将视频和语音一起渲染,最后进行可选的放大和自动音频响度标准化。
daVinci-MagiHuman 核心使用单流 Transformer 从一个提示共同生成视频和音频,这有助于即使在短片中也能保持时间和唇形同步的保真度。此 ComfyUI 实现简化了控件:编写图像提示以定义外观,编写视频提示以定义性能和对话,设置剪辑时长,然后运行。
ComfyUI daVinci-MagiHuman 工作流程中的关键模型#
- daVinci-MagiHuman (15B 单流音视频生成器)。角色:从文本中联合生成视频帧和语音,同时保持时间一致性和唇形同步。参考资料:GitHub, arXiv, Hugging Face。
- T5Gemma 9B 编码器 (UL2 适配)。角色:将视频提示编码为丰富的条件,以指导 daVinci-MagiHuman 的运动、表现和风格。参考资料:Hugging Face。
- Z-Image Turbo 扩散模型。角色:快速生成高质量的静态肖像,从图像提示中用作动画的身份/参考。参考资料:Hugging Face (z_image_turbo), Hugging Face (z_image)。
- Qwen 3 4B 文本编码器用于 Z-Image Turbo。角色:解析图像提示以指导肖像生成。参考资料:Hugging Face file。
- Wan 2.2 VAE。角色:将 MagiHuman 视频潜变量解码为具有强时间一致性的 RGB 帧。参考资料:GitHub, Hugging Face 示例模型。
- Audio VAE (sd_audio)。角色:将 MagiHuman 音频潜变量解码为语音波形,与最终视频合并。参考资料:MagiHuman 的自定义节点包 GitHub。
- RTX 视频超分辨率(可选)。角色:在最终编码之前放大解码帧以提高感知清晰度和减少压缩伪影。参考资料:ComfyUI 包装器 GitHub。
如何使用 ComfyUI daVinci-MagiHuman 工作流程#
总体流程:Z-Image Turbo 组从您的图像提示中创建一个身份肖像。MagiHuman 模型组加载 daVinci-MagiHuman 检查点、视频 VAE 和音频 VAE,并准备文本编码器。文本提示组将您的视频提示转化为条件。采样组将参考图像和提示融合为联合视频和音频潜变量,然后解码两者。最后,输出阶段将帧与音频合并为 MP4,并提供可选的放大版本。
输入#
使用图像提示和视频提示文本框描述外观和性能。持续时间控件设置剪辑长度(以秒为单位)。如果您计划尝试音频驱动的变体,音频加载器是为了方便而存在,但此模板默认在文本驱动模式下运行。
ZImage Turbo#
此阶段使用 Z-Image Turbo UNet 和其捆绑的 VAE 从图像提示中渲染一个单一的参考肖像。它经过优化以快速、干净地生成具有电影外观的身份。结果将被预览,然后作为动画的参考图像转发。如果您已经有了头像,可以通过直接将图像连接到动画阶段来绕过此步骤。
MagiHuman 模型#
在这里,图形加载 daVinci-MagiHuman 基础或精炼检查点以及 Wan 2.2 视频 VAE、音频 VAE 和 T5Gemma 编码器。这使得文本编码、视频潜变量和音频潜变量在单流采样中保持一致。您可以在环境中有可用替代品时更换权重。
文本提示#
您的视频提示被编码为正面和负面条件。正面文本应描述相机距离、姿势、语言、表现风格和确切的对话内容。负面文本可以列出要避免的视觉或音频缺陷。编码器将这两组条件输入到采样器中,以塑造运动、唇部动态和音色。
采样#
采样器从参考图像和请求的持续时间构建初始潜在序列,然后使用 daVinci-MagiHuman 进行去噪以生成同步的视频和音频潜变量。一个实用程序将持续时间转换为完整的秒数以实现稳定的调度。当采样完成时,视频潜变量进入视频解码器,音频潜变量进入音频解码器。
解码、响度和导出#
视频潜变量用 Wan 2.2 VAE 解码为图像帧。音频潜变量解码为语音,然后标准化为广播友好的响度,以便最终的 MP4 在各种设备上实现一致播放。生成两个输出:一个基础渲染和一个使用 RTX 视频超分辨率的可选放大渲染。两者都与音频合并为 MP4,并以清晰的文件名前缀保存。
ComfyUI daVinci-MagiHuman 工作流程中的关键节点#
MagiHuman_LATENTS(#13)
构建视频和可选音频的联合潜在画布,使用参考图像和剪辑长度。调整 seconds 以设置持续时间,并确保您的参考图像在您描述的运动中良好构图。更高的基础分辨率有助于面部保真度,但也会增加 VRAM 和解码时间。
MagiHuman_SM_ENCODER(#95)
将视频提示编码为用于采样器的正面和负面条件。将确切的台词放在引号中,并命名语言以改善唇部闭合和时间。使用负面字段来抑制诸如“字幕”、“静态”或“房间回声”等伪影。
MagiHuman_SM_KSampler(#9)
运行 daVinci-MagiHuman 去噪以共同生成视频和语音潜变量。seed 控制可重复性,而 steps 和内部计划在速度与细节和运动稳定性之间进行权衡。若要在不失去身份的情况下变化,请更改 seed 或轻微改写提示的表现部分。
MagiHuman_EN_DECO_VIDEO(#5)
用 Wan 2.2 VAE 将视频潜变量解码为 RGB 帧以进行导出或放大。使用此路径可实现最快的端到端渲染;长剪辑或更高分辨率将线性增加解码时间。
MagiHuman_DECO_AUDIO(#6)
将音频潜变量解码为波形并通过响度标准化,以实现均匀播放。如果您后来切换到音频驱动的生成,将外部音频输入连接到潜变量构建器,并保留此解码路径以进行最终合并。
RTXVideoSuperResolution(#93)
可选的后期放大器,可锐化边缘并减少振铃。使用适度的强度来提高清晰度,而不会引入时间闪烁。
可选附加功能#
- 可靠唇形同步的提示模式:包括说话者标签和语言以及引用的台词,例如 Dialogue: <Presenter, English>: "Welcome to the show." 添加有关表现、镜头大小和相机稳定性的简要说明。
- 保持参考肖像为中等特写,头部完全在框内。紧凑的裁剪留给下巴和面颊动态的空间较小。
- 如果您需要更严格的时间安排,请修剪或延长您的脚本以匹配所选的持续时间。非常长的句子在非常短的剪辑中可能会导致不自然的发音。
- 此模板在仅提示模式下运行。对于音频驱动的测试,将外部音频文件连接到
MagiHuman_LATENTS(#13) 上的音频输入,并调整您的视频提示以描述表情而不是口述内容。
致谢#
此工作流程实现并构建在以下工作和资源之上。我们对 daVinci-MagiHuman 的贡献和维护表示衷心感谢。有关权威详细信息,请参阅下文链接的原始文档和存储库。
资源#
- daVinci-MagiHuman/Workflow Source
注意:使用所引用的模型、数据集和代码须遵守其作者和维护者提供的各自许可证和条款。