
Генерация звукового эффекта Woosh: аудио, обусловленное подсказками и видео, в ComfyUI#
Генерация звукового эффекта Woosh — это рабочий процесс ComfyUI, который преобразует текстовые подсказки или видеоклипы в отточенные звуковые эффекты с использованием базовой модели Woosh от Sony Research. Он создан для создателей, которым нужно одно место для Фоли, основанного на подсказках, строго соответствующего видео звукового дизайна и быстрого переключения между высококачественными и быстрыми дистиллированными вариантами.
Рабочий процесс раскрывает обе семьи моделей Woosh: Flow/DFlow для text‑to‑audio и VFlow/DVFlow для video‑to‑audio. Общий сэмплер управляет генерацией на обоих путях, выводя аудио для немедленного предварительного просмотра и, в видео пути, предварительные просмотры кадров, которые рекомбинируются для быстрого создания дэйлисов. В основе он полагается на официальные узлы ComfyUI Woosh и VideoHelperSuite для бесперебойного ввода-вывода видео, так что Генерация звукового эффекта Woosh остается быстрой и простой, оставаясь гибкой. Ссылки: SonyResearch/Woosh, drbaph/Woosh на Hugging Face, статья, ComfyUI-Woosh, ComfyUI-VideoHelperSuite.
Ключевые модели в рабочем процессе Генерации звукового эффекта Woosh Comfyui#
- Sony Research Woosh — Flow: основной генератор text‑to‑audio, используемый для высококачественного Фоли и амбиента, обученный с целями сопоставления потоков. См. SonyResearch/Woosh и статья.
- Sony Research Woosh — DFlow: дистиллированная модель text‑to‑audio, оптимизированная для скорости с гораздо меньшим количеством шагов сэмплирования, идеальна для быстрого итеративного процесса. Веса доступны через drbaph/Woosh.
- Sony Research Woosh — VFlow‑8s: генератор, обусловленный видео, который синхронизирует начало и текстуры аудио с визуальными движениями для video‑to‑audio. См. SonyResearch/Woosh.
- Sony Research Woosh — DVFlow‑8s: дистиллированная модель video‑to‑audio для рабочих процессов с ориентацией на реальное время и быстрых предварительных просмотров. Веса: drbaph/Woosh.
- Woosh‑AE: аудио автоэнкодер, используемый для реконструкции волновых форм из латентов модели; требуется всеми генераторами. Веса: drbaph/Woosh.
- TextConditionerA и TextConditionerV: модули текстового кондиционирования, которые внедряют подсказки соответствующим образом для text‑to‑audio или video‑to‑audio прогонов. Подробности и использование задокументированы в ComfyUI-Woosh и статья.
Как использовать рабочий процесс Генерации звукового эффекта Woosh Comfyui#
Этот рабочий процесс имеет две параллельные группы, которые вы можете запускать независимо: Видео в Аудио для звукового дизайна, соответствующего видео, и Текст в Аудио для чистого Фоли, основанного на подсказках. Обе группы сходятся на одной и той же логике сэмплера и быстром предварительном просмотре аудио, делая Генерацию звукового эффекта Woosh последовательной в использовании независимо от входных данных.
Видео в Аудио#
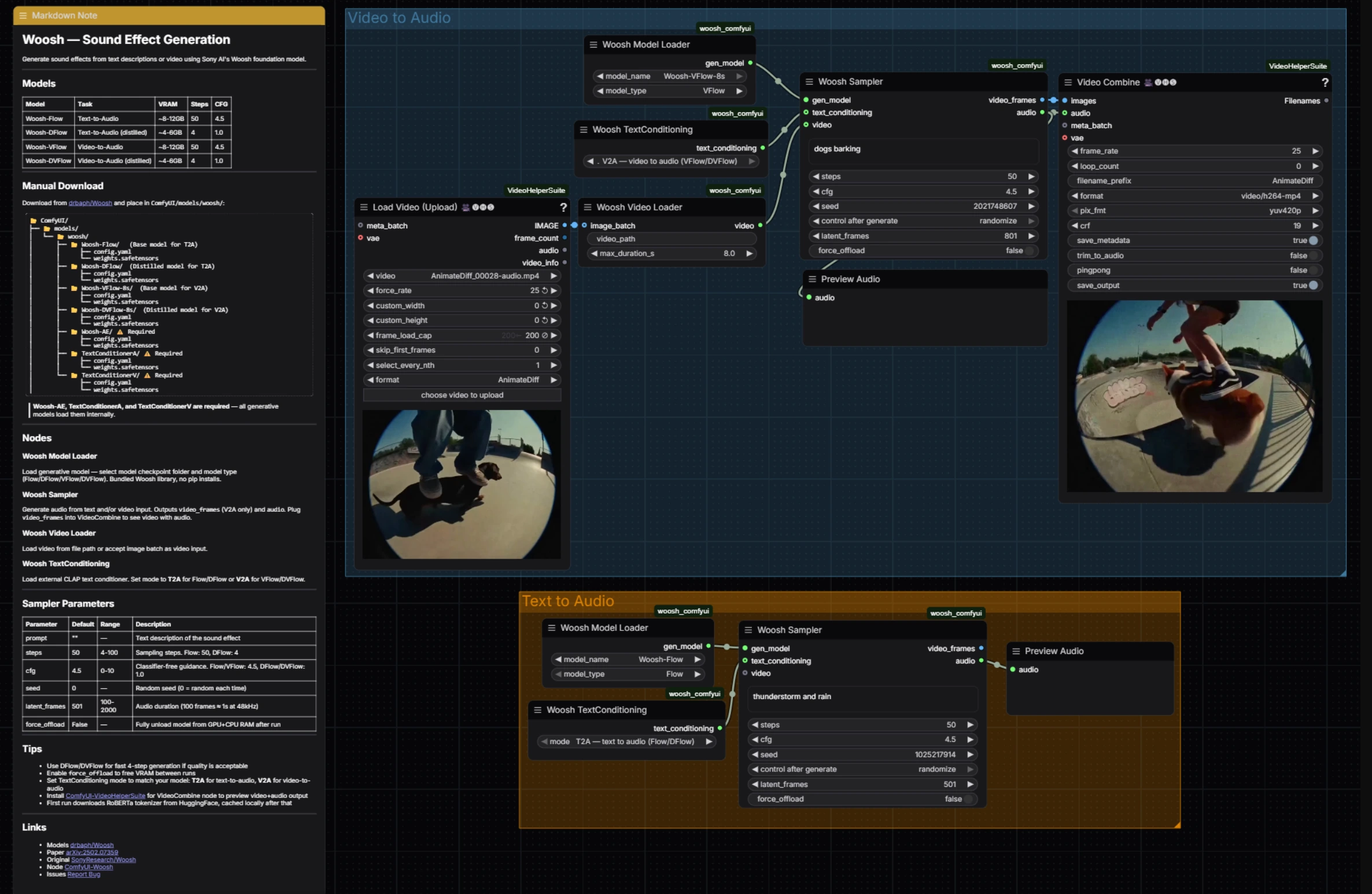
Группа Видео в Аудио загружает клип, выравнивает кадры и кондиционирование, а затем генерирует синхронизированный звук. Начните с подачи вашего клипа в VHS_LoadVideo (#34); он извлекает кадры с выбранной вами частотой, чтобы нижестоящие узлы видели чистую, ограниченную последовательность. Эти кадры упаковываются как поток кондиционирования видео WooshLoadVideo (#37), который стандартизирует продолжительность, чтобы генератор получал стабильные окна.
Выберите модель, обусловленную видео, в WooshLoadFlow (#7), обычно VFlow для верности или DVFlow для скорости. Укажите короткую описательную подсказку в сэмплере (для стиля или намерения) и установите WooshTextEncode (#19) на V2A, чтобы текст был внедрен с правильной ветвью кондиционирования. Запустите WooshSample (#38) для синтеза аудио; он выводит как audio для PreviewAudio (#9), так и video_frames, которые переходят в VHS_VideoCombine (#33) для быстрого сшитого предварительного просмотра, сохраняя Генерацию звукового эффекта Woosh компактной для редакторского просмотра.
Текст в Аудио#
Группа Текст в Аудио фокусируется на чистой генерации, основанной на подсказках. Выберите модель в WooshLoadFlow (#40), используя Flow, когда вам нужно максимальное качество, и DFlow, когда вам нужны очень быстрые, итеративные проходы. Установите WooshTextEncode (#41) на T2A, чтобы ваша подсказка была внедрена для генерации только текста. Введите ваше описание в WooshSample (#39) и выполните; результат отправляется в PreviewAudio (#43) для мгновенного прослушивания. Этот путь сохраняет Генерацию звукового эффекта Woosh легкой, когда вы создаете библиотеки или накладываете эффекты без изображения.
Ключевые узлы в рабочем процессе Генерации звукового эффекта Woosh Comfyui#
WooshSample (#38)#
Центральный сэмплер для генерации, обусловленной видео. Настройте подсказку, чтобы управлять стилем и началом, затем отрегулируйте steps для компромисса между качеством и скоростью (используйте меньше шагов при запуске DVFlow). cfg контролирует соблюдение подсказок, а latent_frames определяет длину вывода, чтобы она совпадала или намеренно смещалась относительно клипа. Установите seed для воспроизведения дублей и включите force_offload, когда вам нужно очистить память между длинными запусками. Реализация узла и поведение следуют официальному ComfyUI-Woosh.
WooshSample (#39)#
Сэмплер для text‑to‑audio с такими же контролями и поведением, за исключением видеопотока. Для быстрой генерации выберите DFlow и низкие steps; для финалов переключитесь на Flow и увеличьте steps для детализации. Держите cfg умеренным для естественных текстур, поднимайте выше для стилизованных, строго соответствующих подсказкам результатов. Используйте latent_frames, чтобы точно установить продолжительность при создании активов для библиотек или временных шкал DAW.
WooshLoadFlow (#7)#
Выбор модели для пути Видео в Аудио. Выберите VFlow для наивысшей точности выравнивания с движением или DVFlow, когда вам нужны почти в реальном времени предварительные просмотры. Убедитесь, что WooshTextEncode установлен на V2A, чтобы внедрения соответствовали выбранной семье моделей. См. drbaph/Woosh для вариантов моделей.
WooshLoadFlow (#40)#
Выбор модели для пути Текст в Аудио. Выберите Flow для богатой детализации и более широкого разнообразия текстур или DFlow для быстрого итеративного процесса с минимальными шагами. Сопоставьте это с WooshTextEncode в режиме T2A, чтобы избежать несоответствий кондиционирования. Поведение узла и опции следуют официальному ComfyUI-Woosh.
VHS_VideoCombine (#33)#
Утилита для сборки сгенерированного audio с предварительным просмотром video_frames из сэмплера для создания клипа для просмотра. Используйте его, чтобы заметить синхронизацию, оценить переходы и поделиться дэйлисами, не выходя из ComfyUI. Часть ComfyUI-VideoHelperSuite.
Дополнительные возможности#
- Используйте DVFlow/DFlow для быстрого поиска, затем переключитесь на VFlow/Flow для финалов, когда Генерация звукового эффекта Woosh должна блеснуть.
- Держите ваш входной клип в пределах окна выбранной модели (например, 8-секундные варианты VFlow) и обрабатывайте более длинные сцены в перекрывающихся фрагментах, которые можно перекрестно затухать.
- Поддерживайте постоянную частоту кадров от
VHS_LoadVideoдоVHS_VideoCombine, чтобы уменьшить дрейф между аудио и изображением. - Для подсказок сочетайте слова действия с текстурой и акустическим контекстом (например, "быстрый металлический свист в бетонной лестничной клетке"), чтобы получить предсказуемые результаты.
- Включите
force_offloadв сэмплере между тяжелыми запусками, если память GPU ограничена.
Благодарности#
Этот рабочий процесс реализует и опирается на следующие работы и ресурсы. Мы искренне благодарим Sony Research за Woosh (проект и статья), Saganaki22 за ComfyUI-Woosh (узел ComfyUI) и Kosinkadink за ComfyUI-VideoHelperSuite за их вклад и поддержку. Для авторитетных деталей, пожалуйста, обратитесь к оригинальной документации и репозиториям, указанным ниже.
Ресурсы#
- Saganaki22/ComfyUI-Woosh
- GitHub: Saganaki22/ComfyUI-Woosh
- drbaph/Woosh
- Hugging Face: drbaph/Woosh
- SonyResearch/Woosh
- GitHub: SonyResearch/Woosh
- Sony Research/Woosh (статья)
- arXiv: 2502.07359
- Kosinkadink/ComfyUI-VideoHelperSuite
Примечание: Использование упомянутых моделей, наборов данных и кода подчиняется соответствующим лицензиям и условиям, предоставленным их авторами и поддерживающими.