
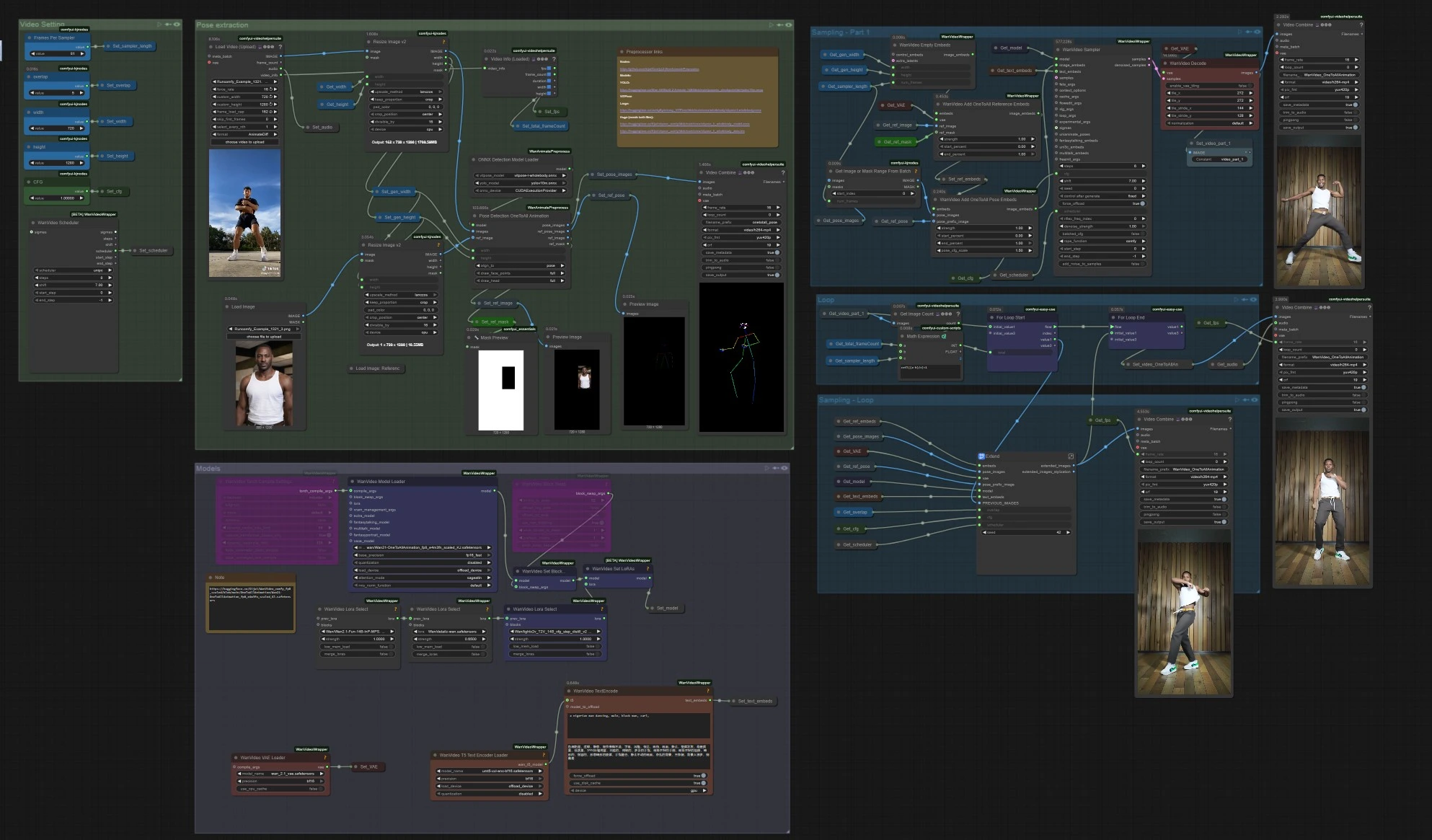
Анимация от одного ко всем: длинная форма, выравненное по позам видео с персонажем в ComfyUI#
Этот процесс анимации от одного ко всем превращает короткий эталонный клип в расширенное, высококачественное видео, сохраняя движение, выравнивание поз и идентичность персонажа на протяжении всей последовательности. Основан на генерации видео Wan 2.1 с руководством по позам для всего тела и расширителем скользящего окна, он идеально подходит для танцев, захвата производительности и нарративных кадров, где вы хотите, чтобы один внешний вид следовал за сложным движением.
Если вы создатель, которому нужны стабильные, управляемые позами результаты без дрожания или смещения идентичности, анимация от одного ко всем предоставляет вам четкий путь: извлеките позы из вашего исходного видео, объедините их с эталонным изображением и маской, создайте первый фрагмент, а затем расширяйте этот фрагмент повторно, пока не будет покрыта вся длина.
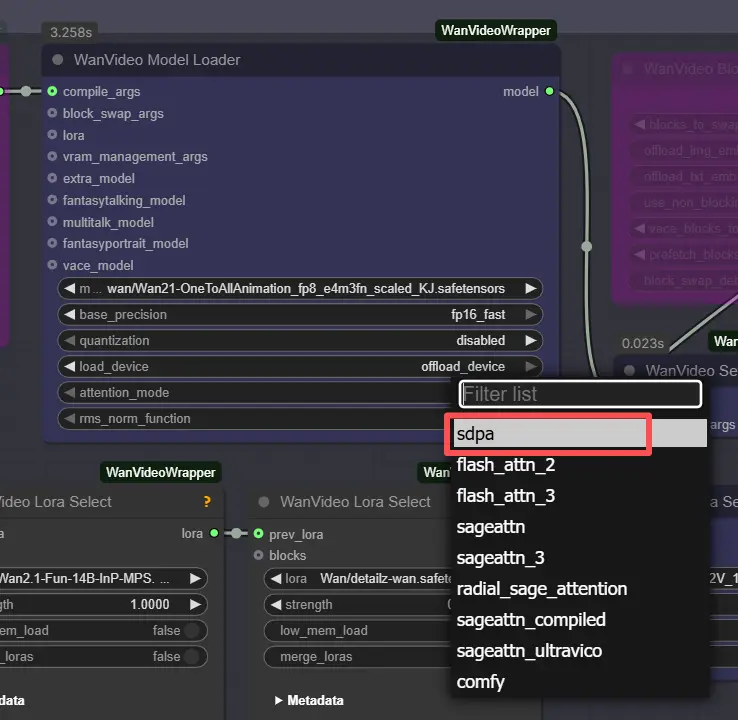
Примечание: на машинах 2XL или 3XL, пожалуйста, установите attention_mode на "sdpa" в узле WanVideo Model Loader. Стандартная бэкенд segeattn может вызвать проблемы совместимости на высокопроизводительных GPU.
Ключевые модели в рабочем процессе анимации от одного ко всем в Comfyui#
- Wan 2.1 OneToAllAnimation (генерация видео). Основная диффузионная модель, используемая для высококачественного движения и сохранения идентичности. Примеры весов: Wan21-OneToAllAnimation fp8, масштабированный Kijai. Model card
- UMT5-XXL текстовый кодировщик. Кодирует подсказки для генерации видео Wan. Model card
- ViTPose Whole-Body (оценка поз). Создает плотные ключевые точки скелета, которые обеспечивают точность поз. См. статью ViTPose и веса ONNX для всего тела. Paper • Weights
- YOLOv10m детектор (обнаружение человека/региона). Ускоряет надежное извлечение поз, сосредотачивая оценщик на объекте. Paper • Weights
- Альтернатива ViTPose-H по желанию. Модель для всего тела с большей емкостью для сложных движений. Weights и data file
- Дополнительные пакеты LoRA для стиля/управления. Примеры LoRA, используемые в этой графике, включают Wan2.1-Fun-InP-MPS, detailz-wan и lightx2v T2V; они улучшают текстуру, детали или управление на месте без повторного обучения.
Как использовать рабочий процесс анимации от одного ко всем в Comfyui#
Общая схема
- Рабочий процесс считывает ваше эталонное видео движения, извлекает позы всего тела, подготавливает встраивания анимации от одного ко всем, которые объединяют позу и эталон персонажа, генерирует начальный клип, а затем многократно расширяет этот клип с перекрытием, пока не будет покрыта вся длительность. В конце он объединяет аудио и экспортирует полное видео.
Извлечение поз
- Загрузите ваш источник движения в
VHS_LoadVideo(#454). Кадры изменяются по размеру с помощьюImageResizeKJv2(#131), чтобы соответствовать аспектному соотношению генерации для стабильной выборки. OnnxDetectionModelLoader(#128) загружает YOLOv10m и ViTPose для всего тела;PoseDetectionOneToAllAnimation(#141) затем выдает карту позы на кадр, эталонное изображение позы и чистую эталонную маску.- Используйте
PreviewImage(#145), чтобы быстро проверить, что позы отслеживают объект. Четкие, высококонтрастные кадры с минимальным размытием движения дают лучшие результаты анимации от одного ко всем.
Модели
WanVideoModelLoader(#22) загружает веса Wan 2.1 OneToAllAnimation;WanVideoVAELoader(#38) предоставляет сопряженный VAE. При желании, сложите стили/управление LoRAs черезWanVideoLoraSelect(#452, #451, #56) и примените их сWanVideoSetLoRAs(#80).- Текстовые подсказки кодируются
WanVideoTextEncode(#16). Напишите краткую, ориентированную на идентичность положительную подсказку и сильную очистительную отрицательную, чтобы сохранить персонажа в модели.
Настройки видео
- Ширина и высота устанавливаются в группе "Video Setting" и распространяются на извлечение поз и генерацию, чтобы все оставалось выровненным.
Примечание: ⚠️ Ограничение разрешения : Этот рабочий процесс фиксирован на 720×1280 (720p). Использование любого другого разрешения вызовет ошибки несоответствия размеров, если рабочий процесс не будет настроен вручную.
WanVideoScheduler(#231) и управлениеCFGвыбирают график шума и силу подсказки. Более высокие значения CFG больше соответствуют подсказке; более низкие значения отслеживают позу немного более свободно, но могут уменьшить артефакты.VHS_VideoInfoLoaded(#440) считывает fps и количество кадров исходного клипа, которые используются в цикле для определения того, сколько окон анимации от одного ко всем требуется.
Выборка – Часть 1
WanVideoEmptyEmbeds(#99) создает контейнер для кондиционирования до целевого размера.WanVideoAddOneToAllReferenceEmbeds(#105) внедряет ваше эталонное изображение и егоref_mask, чтобы заблокировать идентичность и сохранить или игнорировать области, такие как фон или одежда.WanVideoAddOneToAllPoseEmbeds(#98) прикрепляет извлеченныеpose_imagesиpose_prefix_image, чтобы первый созданный фрагмент следовал за исходным движением с первого кадра.WanVideoSampler(#27) создает начальный латентный клип, который декодируетсяWanVideoDecode(#28) и по желанию предварительно просматривается или сохраняется с помощьюVHS_VideoCombine(#139). Это сегмент семени, который будет расширен.
Цикл
VHS_GetImageCount(#327) иMathExpression|pysssss(#332) рассчитывают, сколько проходов расширения требуется на основе общего количества кадров и длины каждого прохода.easy forLoopStart(#329) начинает проходы расширения, используя начальный клип как начальный контекст.
Выборка – Цикл
Extend(#263) – это сердце длинной анимации от одного ко всем. Он пересчитывает кондиционирование сWanVideoAddOneToAllExtendEmbeds(внутри подграфа), чтобы поддерживать непрерывность от предыдущих латентов, затем выбирает и декодирует следующее окно.ImageBatchExtendWithOverlap(внутриExtend) смешивает каждое новое окно с накопленным видео, используя областьoverlap, сглаживая границы и уменьшая временные швы.easy forLoopEnd(#334) добавляет каждый расширенный блок. Результат сохраняется с помощьюSet_video_OneToAllAnimation(#386) для экспорта.
Экспорт
VHS_VideoCombine(#344) записывает финальное видео, используя fps источника и дополнительное аудио изVHS_LoadVideo. Если вы предпочитаете беззвучный результат, пропустите или отключите аудиовход здесь.
Ключевые узлы в рабочем процессе анимации от одного ко всем в Comfyui#
PoseDetectionOneToAllAnimation (#141)
- Обнаруживает объект и оценивает ключевые точки всего тела, которые управляют руководством по позам. Поддерживается YOLOv10 и ViTPose, он устойчив к быстрому движению и частичному перекрытию. Если ваш объект дрейфует или сцены с несколькими людьми сбивают с толку детектор, обрежьте ввод или переключитесь на веса ViTPose-H с большей емкостью, указанные выше.
WanVideoAddOneToAllReferenceEmbeds (#105)
- Объединяет эталонное изображение и
ref_maskв кондиционирование, чтобы идентичность, наряд или защищенные области оставались стабильными на протяжении всех кадров. Узкие маски сохраняют лица и волосы; более широкие маски могут зафиксировать фон. При изменении внешнего вида замените эталон и сохраните то же движение.
WanVideoAddOneToAllPoseEmbeds (#98)
- Привязывает карты поз и префикс позы к встраиваниям анимации от одного ко всем. Для более строгой хореографии увеличьте влияние позы; для более свободной интерпретации немного уменьшите его. Комбинируйте с LoRAs, когда вы хотите сохранить текстуру, при этом соответствуя движению.
WanVideoSampler (#27)
- Основной видеосемплер, который превращает встраивания и текст в начальный латентный клип.
cfgконтролирует соблюдение подсказки, аschedulerобменивает качество, скорость и стабильность. Используйте ту же семью семплеров здесь и в цикле, чтобы избежать мерцания.
Extend (#263)
- Компактный подграф, который выполняет расширение скользящего окна с перекрытием. Настройка
overlapявляется ключевым регулятором: большее перекрытие делает переходы более плавными за счет дополнительных вычислений; меньшее перекрытие быстрее, но может выявить швы. Этот узел также повторно использует предыдущие латенты, чтобы сохранить сцену и персонажа согласованными между окнами.
VHS_VideoCombine (#344)
- Финальное мультиплексирование и сохранение. Установите
frame_rateиз обнаруженного fps, чтобы сохранить верность тайминга движения источнику. Вы можете обрезать или зациклить в постобработке, но экспорт при оригинальной частоте кадров сохраняет ощущение исполнения.
Дополнительные возможности#
- Установочные заметки для препроцессоров. Узлы извлечения поз взяты из дополнения сообщества. См. репозиторий для настройки и размещения ONNX. ComfyUI-WanAnimatePreprocess
- Предпочтение ViTPose-H для сложных движений. Переключитесь на ViTPose-H, когда руки/ноги двигаются быстро или частично перекрыты; загрузите как модель, так и ее файл данных с вышеуказанных страниц.
- Настройка для длительных запусков. Если вы столкнулись с ограничениями VRAM, уменьшите длину окна на проход или упростите стеки LoRA. Затем перекрытие можно немного увеличить, чтобы сохранить чистоту переходов.
- Сильное сохранение идентичности. Используйте высококачественное, фронтальное эталонное изображение и нарисуйте точную
ref_mask, чтобы защитить лицо, волосы или наряд. Это критично для длинных последовательностей анимации от одного ко всем. - Чистые кадры помогают. Высокая скорость затвора, равномерное освещение и четкий объект на переднем плане значительно улучшат отслеживание поз и уменьшат дрожание в выходах анимации от одного ко всем.
- Утилиты для видео. Экспортер и вспомогательные узлы взяты из Video Helper Suite. Если вы хотите дополнительный контроль над кодеками или предварительным просмотром, ознакомьтесь с документацией проекта. Video Helper Suite
Благодарности#
Этот рабочий процесс реализует и основывается на следующих работах и ресурсах. Мы искренне благодарим Innovate Futures @ Benji за руководство по рабочему процессу анимации от одного ко всем и ssj9596 за проект One-to-All Animation за их вклад и поддержку. Для получения авторитетной информации обратитесь к оригинальной документации и репозиториям, указанным ниже.
Ресурсы#
- Innovate Futures @ Benji/Источник анимации от одного ко всем
- GitHub: ssj9596/One-to-All-Animation
- Hugging Face: MochunniaN1/One-to-All-1.3b_1
- arXiv: 2511.22940
- Документы / Примечания к выпуску: Patreon пост
Примечание: использование упомянутых моделей, наборов данных и кода подчиняется соответствующим лицензиям и условиям, предоставленным их авторами и поддерживающими.

