
⚠️ Важное примечание: Эта реализация ComfyUI MultiTalk в настоящее время поддерживает генерацию ТОЛЬКО ОДНОГО ЧЕЛОВЕКА. Функции многопользовательского диалога появятся в ближайшее время.
1. Что такое MultiTalk?#
MultiTalk — это революционный фреймворк для аудио-управляемой генерации многопользовательских разговорных видео, разработанный MeiGen-AI. В отличие от традиционных методов генерации говорящих голов, которые лишь анимируют движения лица, технология MultiTalk может генерировать реалистичные видео людей, говорящих, поющих и взаимодействующих, сохраняя при этом идеальную синхронизацию губ с аудиовходом. MultiTalk преобразует статические фотографии в динамические говорящие видео, заставляя человека говорить или петь именно то, что вы хотите.
2. Как работает MultiTalk#
MultiTalk использует передовую технологию ИИ для понимания как аудиосигналов, так и визуальной информации. Реализация ComfyUI MultiTalk сочетает MultiTalk + Wan2.1 + Uni3C для оптимальных результатов:
Анализ аудио: MultiTalk использует мощный аудиокодировщик (Wav2Vec) для понимания нюансов речи, включая ритм, тон и паттерны произношения.
Визуальное понимание: Построенный на надёжной модели диффузии видео Wan2.1, MultiTalk понимает анатомию человека, выражения лица и движения тела (вы можете посетить наш рабочий процесс Wan2.1 для генерации t2v/i2v).
Управление камерой: MultiTalk с Uni3C controlnet обеспечивает тонкие движения камеры и управление сценой, делая видео более динамичным и профессиональным. Ознакомьтесь с нашим рабочим процессом Uni3C для создания красивого переноса движений камеры.
Идеальная синхронизация: Через сложные механизмы внимания MultiTalk учится идеально синхронизировать движения губ с аудио, сохраняя при этом естественные выражения лица и язык тела.
Следование инструкциям: В отличие от более простых методов, MultiTalk может следовать текстовым подсказкам для управления сценой, позой и общим поведением, сохраняя при этом синхронизацию с аудио.
3. Преимущества ComfyUI MultiTalk#
- Высококачественная синхронизация губ: MultiTalk достигает миллисекундной точности синхронизации губ, особенно впечатляющей для сценариев пения
- Разностороннее создание контента: MultiTalk поддерживает генерацию как речи, так и пения с различными типами персонажей, включая мультипликационных
- Гибкое разрешение: MultiTalk генерирует видео в 480P или 720P с произвольными соотношениями сторон
- Поддержка длинных видео: MultiTalk создаёт видео длительностью до 15 секунд
- Следование инструкциям: MultiTalk управляет действиями персонажей и настройками сцены через текстовые подсказки
4. Как использовать рабочий процесс ComfyUI MultiTalk#
Пошаговое руководство по MultiTalk#
Шаг 1: Подготовьте входные данные MultiTalk
- Загрузите референсное изображение: Нажмите "choose file to upload" в узле Load Image
- Используйте чёткие фотографии анфас для лучших результатов MultiTalk
- Изображение будет автоматически масштабировано до оптимальных размеров (рекомендуется 832px)
- Загрузите аудиофайл: Нажмите "choose file to upload" в узле LoadAudio
- MultiTalk поддерживает различные аудиоформаты (WAV, MP3 и др.)
- Чёткая речь/пение работает лучше всего с MultiTalk
- Для создания пользовательских песен рассмотрите использование нашего рабочего процесса генерации музыки Ace-Step, который создаёт высококачественную музыку с синхронизированными текстами.
- Напишите текстовую подсказку: Опишите желаемую сцену в узлах кодирования текста для генерации MultiTalk
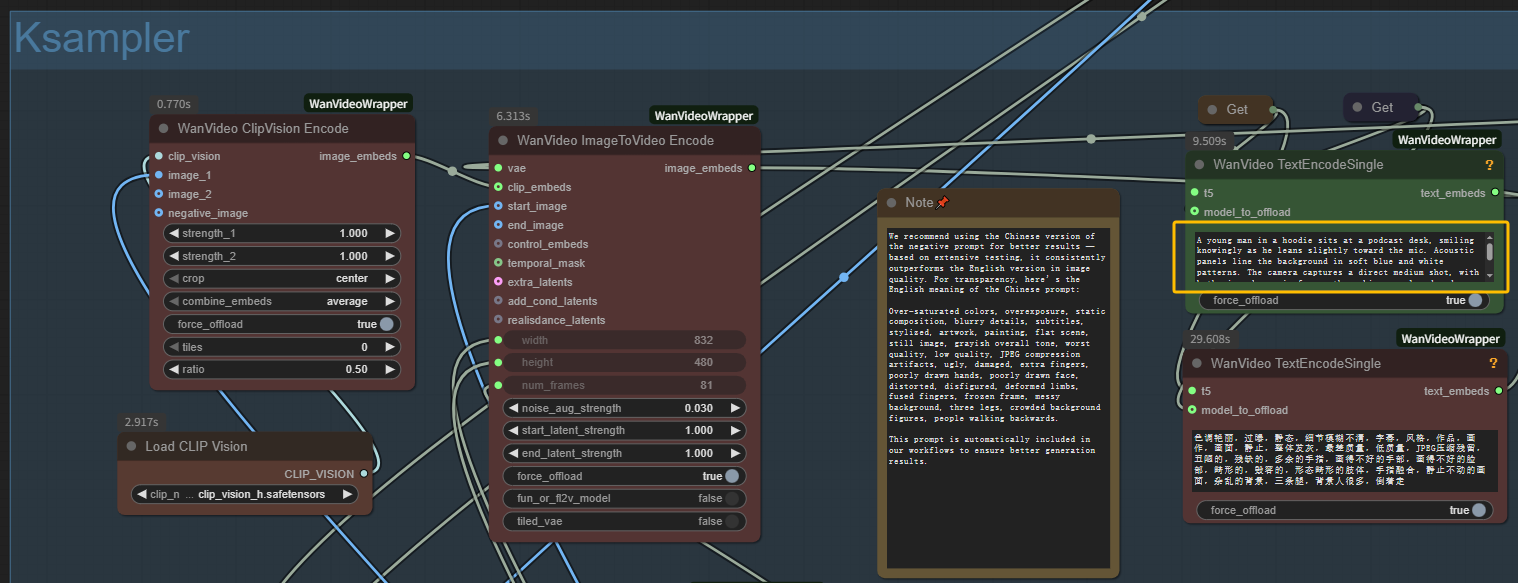
Шаг 2: Настройте параметры генерации MultiTalk
- Шаги сэмплирования: 20-40 шагов (больше = лучшее качество MultiTalk, более медленная генерация)
- Audio Scale: Оставьте 1.0 для оптимальной синхронизации губ MultiTalk
- Embed Cond Scale: 2.0 для сбалансированного аудиокондиционирования MultiTalk
- Управление камерой: Включите Uni3C для тонких движений или отключите для статичных кадров MultiTalk
Шаг 3: Опциональные улучшения MultiTalk
- Ускорение LoRA: Включите для более быстрой генерации MultiTalk с минимальной потерей качества
- Улучшение видео: Используйте узлы улучшения для постобработки MultiTalk
- Негативные подсказки: Добавьте нежелательные элементы для исключения из вывода MultiTalk (размытие, искажения и т.д.)
Шаг 4: Генерация с MultiTalk
- Поставьте подсказку в очередь и дождитесь генерации MultiTalk
- Следите за использованием VRAM (рекомендуется 48 ГБ для MultiTalk)
- Время генерации MultiTalk: 7-15 минут в зависимости от настроек и оборудования
5. Благодарности#
Оригинальное исследование: MultiTalk разработан MeiGen-AI при сотрудничестве с ведущими исследователями в этой области. Оригинальная статья "Let Them Talk: Audio-Driven Multi-Person Conversational Video Generation" представляет революционное исследование, стоящее за этой технологией.
Интеграция ComfyUI: Реализация ComfyUI предоставлена Kijai через репозиторий ComfyUI-WanVideoWrapper, делая эту передовую технологию доступной более широкому творческому сообществу.
Базовая технология: Построена на модели диффузии видео Wan2.1 и включает методы обработки аудио из Wav2Vec, представляя собой синтез передовых исследований ИИ.
6. Ссылки и ресурсы#
- Оригинальное исследование: MeiGen-AI MultiTalk Repository
- Страница проекта: https://meigen-ai.github.io/multi-talk/
- Интеграция ComfyUI: ComfyUI-WanVideoWrapper
