
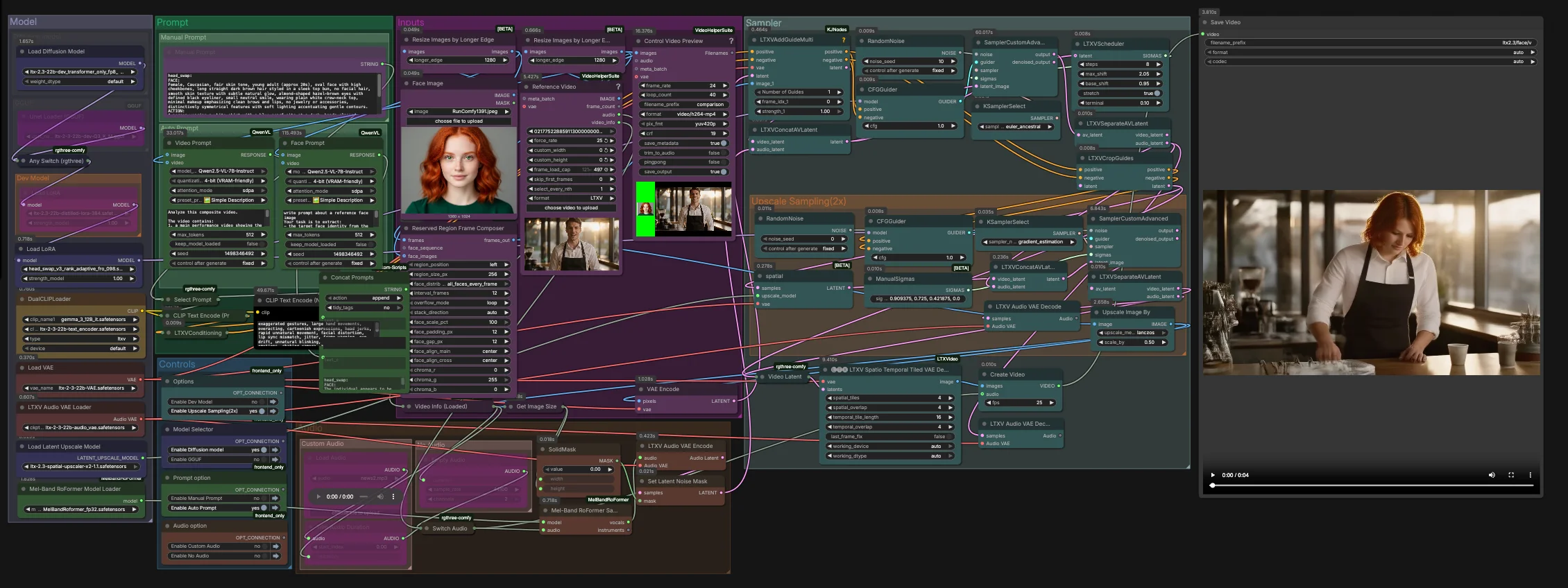
LTX-2.3-Video-Face-Swap для ComfyUI#
Этот процесс обеспечивает высокую точность и временную стабильность замены лиц в видео с использованием семейства LTX 2.3. Созданный для RunComfy и ComfyUI, он объединяет изображение руководства по идентичности с целевым видео и дополнительным аудио-руководством для сохранения выражений, освещения и движения на всех кадрах. Результат — реалистичная замена без мерцания, которая выдерживает крупные планы и средние кадры.
Создатели, VFX-артисты и AI-фильммейкеры могут использовать LTX-2.3-Video-Face-Swap для полного творческого контроля: вручную задавать подсказки или генерировать структурированные подсказки из входных данных, выбирать между dev, distilled, FP8 или GGUF вариантами и завершать пространственно-временной декодировкой и дополнительным 2x латентным увеличением для четких деталей.
Ключевые модели в процессе Comfyui LTX-2.3-Video-Face-Swap#
- LTX 2.3 22B Video Diffusion Transformer. Основная модель генерации и редактирования видео, которая обеспечивает сохранение идентичности и временную согласованность. См. официальное семейство моделей на Lightricks/LTX-2.3.
- LTX 2.3 Text Encoders. График сочетает текстовый кодировщик LTX 2.3 с инструкционным кодировщиком Gemma 3 12B для улучшения согласованности подсказок для редактирования видео. Примеры артефактов: ltx-2-3-22b-text_encoder.safetensors и gemma_3_12B_it.safetensors.
- LTX 2.3 VAE и Audio VAE. Кодировщики/декодировщики, используемые для сжатия и восстановления визуальных кадров и аудиотреков, сохраняя детали и синхронизацию. См. Lightricks/LTX-2.3 VAE files и аудио VAE варианты в раздельном репозитории vantagewithai/LTX-2.3-Split.
- LTX 2.3 Spatial Upscaler x2. Латентное 2x увеличение, которое повышает пространственную точность перед финальной декодировкой, идеально для деталей лица. ltx-2.3-spatial-upscaler-x2-1.1.safetensors.
- Head‑swap LoRA. Ранг-адаптивная LoRA, специализированная для передачи идентичности, которая улучшает сходство и стабильность при редактировании. Пример: head_swap_v3_rank_adaptive_fro_098.safetensors.
- MelBandRoFormer. Опциональная модель разделения источников музыки, используемая здесь для изоляции вокала для более сильного руководства движением губ. Kijai/MelBandRoFormer_comfy.
- Опциональные варианты развертывания. FP8 только веса трансформатора для скорости на поддерживаемых GPU Kijai/LTX2.3_comfy и легкие сборки UNet GGUF для CPU или сценариев с низким VRAM vantagewithai/LTX-2.3-GGUF.
Как использовать процесс Comfyui LTX-2.3-Video-Face-Swap#
Этот график работает в два этапа. На первом этапе выполняется основная замена на родном латентном разрешении с учетом аудио. На втором этапе происходит увеличение в латентном пространстве и уточнение области лица перед пространственно-временной декодировкой и финальным муксированием в видео.
Входные данные#
- Загрузите изображение вашей идентичности в "Face Image" ("LoadImage" (#255)). Используйте хорошо освещенный, фронтальный или трехчетвертной снимок для наиболее надежного извлечения идентичности.
- Загрузите целевой материал в "Reference Video" ("VHS_LoadVideo" (#393)). Кадры нормализуются и предварительно просматриваются через "ResizeImagesByLongerEdge" и "Control Video Preview" ("VHS_VideoCombine" (#396)) для быстрых проверок перед выборкой.
- "ReservedRegionFrameComposer" (#395) подготавливает руководящие кадры, которые выравнивают изображение лица с компоновкой сцены, помогая модели сосредоточиться на области замены во время кондиционирования.
Подсказка#
- Вы можете описать желаемый вид и действие вручную в "Manual Prompt" или позволить графику автоматически составить структурированную подсказку. "Video Prompt" ("AILab_QwenVL" (#400)) извлекает движение тела и сцену из видео, в то время как "Face Prompt" ("AILab_QwenVL" (#401)) извлекает детали идентичности из изображения лица.
- "Concat Prompts" объединяет идентичность и действие в одну краткую инструкцию, затем "Select Prompt" направляет ваш текст вручную или авто подсказку в "CLIP Text Encode". Отрицательный текст подсказки кодируется отдельно, чтобы подавить распространенные видеоартефакты.
Модель#
- Группа "Model" загружает LTX 2.3 UNet или его вариант GGUF, применяет дистиллированную LoRA и head-swap LoRA, и поднимает LTX VAEs и двойные текстовые кодировщики. Двухкодировочная установка улучшает согласованность для устного контента и блокировки камеры без чрезмерного ограничения идентичности.
- Если вы оптимизируете для скорости или памяти, переключайтесь между dev, distilled, FP8 только трансформатором или GGUF в предоставленном селекторе моделей. Дополнительная настройка в RunComfy не требуется.
Семплер#
- На первом этапе объединяются видео и аудио латенты в "LTXVConcatAVLatent" (#321), затем удаляются шумы с помощью "CFGGuider" (#326), "LTXVScheduler" (#324) и "SamplerCustomAdvanced" (#257). "LTXVAddGuideMulti" (#392) вводит ваш руководящий идентификатор, поэтому лицо устанавливается на ранних этапах и остается стабильным с течением времени.
- После первого прохода "LTXVSeparateAVLatent" (#323) разделяет потоки, чтобы "LTXVCropGuides" (#282) мог сосредоточить редактирование вокруг лица. Это концентрирует вычисления там, где они важны, и улучшает временную согласованность.
Масштабирование выборки (2x)#
- "LTXVLatentUpsampler" (#279) применяет LTX 2.3 x2 пространственное увеличение в латентном пространстве. Увеличенное латентное видео затем снова объединяется с аудио латентом в "LTXVConcatAVLatent" (#287) и уточняется вторым проходом "SamplerCustomAdvanced" (#288), управляемым "CFGGuider" (#284).
- Эта двухэтапная стратегия дает более четкие кожу, глаза и волосы, сохраняя замены в соответствии с запланированной идентичностью.
Аудио#
- Группа "Audio" позволяет вам направлять оригинальное аудио, тишину или обрезанный сегмент через "Switch Audio". Для более сильных подсказок движения губ выбранный трек пропускается через "MelBandRoFormerSampler" (#355) для изоляции вокала, затем кодируется с помощью "LTXVAudioVAEEncode" (#364).
- Твердая маска шума ("SetLatentNoiseMask" (#365)) предотвращает непреднамеренные изменения, вызванные аудио, за пределами области рта, при этом используя время речи для управления выражениями.
Декодирование и экспорт#
- Финальные кадры реконструируются с помощью "LTXVSpatioTemporalTiledVAEDecode" (#377), который декодирует с учетом времени, чтобы избежать швов и поддерживать непрерывность движения. "CreateVideo" (#292) соединяет изображения с выбранным вами аудио, а "SaveVideo" записывает готовый клип.
Ключевые узлы в процессе Comfyui LTX-2.3-Video-Face-Swap#
- "LTXVAddGuideMulti" (#392). Подает выровненное руководство лица в поток кондиционирования, чтобы модель фиксировала целевую идентичность с первых шагов. Если сходство отклоняется при быстром движении, увеличьте количество или частоту руководящих кадров, а не повышайте руководство глобально.
- "LTXVCropGuides" (#282). Автоматически фокусирует второй проход на лицевой области, полученной из латентов первого этапа и подсказок. Используйте его, чтобы сузить область редактирования, когда фоны или руки конкурируют за внимание.
- "SamplerCustomAdvanced" (#257). Основной проход удаления шума, который устанавливает идентичность, освещение и грубое движение. Сочетайте его с "LTXVScheduler" для формирования шагов и сохраняйте выбор семплера стабильным на протяжении экспериментов, чтобы сравнения были значимыми.
- "LTXVLatentUpsampler" (#279). Выполняет 2x латентное увеличение с использованием пространственного увеличителя LTX перед уточнением. Используйте это, когда вам нужны более четкие поры, ресницы и швы шляпы, не вводя мерцание от пост-декодировочных пиксельных увеличителей.
- "SamplerCustomAdvanced" (#288). Проход уточнения после увеличения. Умеренно регулируйте руководство здесь, чтобы заострить черты, сохраняя идентичность, установленную первым проходом.
- "LTXVSpatioTemporalTiledVAEDecode" (#377). Декодер с учетом времени, который уменьшает швы плиток на кадрах. Если вы сталкиваетесь с ограничениями VRAM на длинных клипах, предпочитайте корректировать его компоновку плиток, а не снижать разрешение.
- "MelBandRoFormerSampler" (#355). Разделение вокала используется только для руководства. Если исходное аудио шумное, переключитесь на оригинальное или тихое аудио, чтобы избежать переноса артефактов в движение рта.
Дополнительные возможности#
- Качество изображения лица имеет значение. Используйте нейтральное, хорошо освещенное, фронтальное или слегка трехчетвертное фото в возрасте и с выражением, аналогичными выступлению.
- Держите эталонное видео стабильным. Статичные или снятые на штатив кадры дают наиболее стабильные результаты LTX-2.3-Video-Face-Swap, особенно в средних и крупных кадрах.
- Подсказки должны быть краткими. Опишите сцену и действие в одном абзаце и оставьте прилагательные идентичности для подсказки лица, а не действия.
- Аудио руководство является необязательным. Четкая речь улучшает формы рта; музыкальные треки без слов дают мало пользы, поэтому выберите тишину, чтобы сосредоточить вычисления на визуализации.
- Для низкого VRAM или только CPU запусков предпочтите сборку GGUF UNet; для высокой пропускной способности на современных GPU, FP8 только веса трансформатора являются хорошим выбором по умолчанию.
- Используйте ответственно. Получите согласие на любую заменяемую идентичность и соблюдайте применимые законы и политики платформ.
Благодарности#
Этот процесс реализует и основывается на следующих работах и ресурсах. Мы выражаем благодарность LTX-2.3 за модель LTX-2.3 и EyeForAILabs за руководство на YouTube за их вклад и поддержку. Для получения авторитетных деталей, пожалуйста, обратитесь к оригинальной документации и репозиториям, связанным ниже.
Ресурсы#
- LTX-2.3/LTX-2.3 Модель
- Hugging Face: Hugging Face Model
- EyeForAILabs/YouTube Руководство
- Документы / Примечания к выпуску: EyeForAILabs YouTube Tutorial
Примечание: Использование упомянутых моделей, наборов данных и кода подчиняется соответствующим лицензиям и условиям, предоставленным их авторами и поддерживающими.