
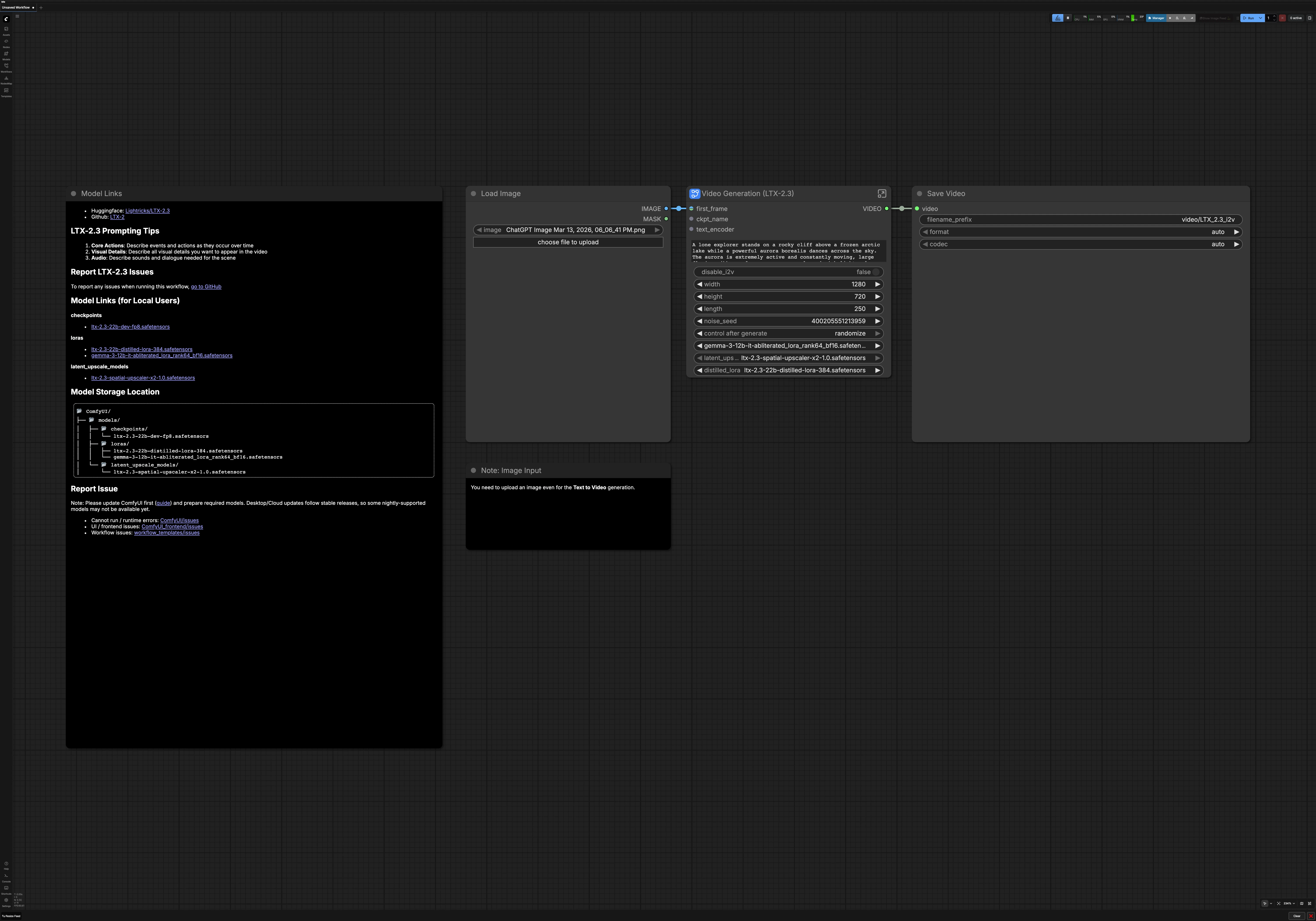
LTX 2.3 Изображение в Видео для ComfyUI#
Этот рабочий процесс превращает одно изображение или чистый текстовый запрос в плавное, кинематографическое AI-видео с LTX 2.3 Изображение в Видео. Он создан для создателей, которые хотят получить высокую визуальную согласованность, сильную консистентность сцены и отточенное движение без ручного подключения. Используйте его на RunComfy или в любой среде ComfyUI для генерации динамичных, стилизованных результатов, которые остаются верны вашему запросу.
Граф поддерживает два творческих режима: изображение в видео с вашим первым кадром в качестве визуального якоря или текст в видео, полностью управляемый языком. Он также включает автоматическое улучшение запроса, латентное увеличение разрешения для большей детализации и опциональное декодирование аудио, чтобы ваш финальный рендер LTX 2.3 Изображение в Видео был готов к публикации.
Ключевые модели в рабочем процессе ComfyUI LTX 2.3 Изображение в Видео#
- Модель видео Lightricks LTX 2.3 22B. Основной трансформер видео-диффузии, который синтезирует временно согласованное движение и визуальные эффекты из текста и опционального визуального руководства. Файлы модели и документация доступны на Hugging Face, а ссылки на уровне кода на GitHub.
- LTX Audio VAE. Аудио вариационный автокодировщик, используемый для декодирования латентного аудио модели в аудиотрек для смешивания с кадрами. Распространяется с выпуском LTX 2.3 на Hugging Face.
- LTX 2.3 Пространственный Увеличитель x2. Модель суперразрешения в латентном пространстве, которая улучшает резкость и пространственную точность перед финальной выборкой высокого разрешения. Доступно в репозитории LTX 2.3 на Hugging Face.
- Gemma 3 12B Инструкционный текстовый кодировщик плюс LoRA. Компактный инструкционно-настроенный текстовый кодировщик и LoRA, используемые здесь для улучшения понимания и формулировки запроса для видео. Упакованный кодировщик и веса LoRA, используемые в этом шаблоне, предоставлены в активах Comfy-Org LTX-2 на Hugging Face.
Как использовать рабочий процесс ComfyUI LTX 2.3 Изображение в Видео#
На высоком уровне ваш запрос и опциональный первый кадр кодируются, низкоразрешённое латентное видео образуется, затем увеличивается в латентном пространстве и уточняется при более высоком разрешении. Результат декодируется в кадры и аудио, затем компонуется в финальный MP4. Вы можете переключаться между изображением в видео и текстом в видео в любой момент перед запуском.
- Модель
- Эта группа загружает контрольную точку LTX 2.3, аудио VAE и текстовый кодировщик. Она также применяет LTX 2.3 LoRA к базовой модели для улучшенного следования инструкциям. Вместе они определяют основу, на которой строится остальная часть конвейера LTX 2.3 Изображение в Видео. Обычно вы не будете менять здесь ничего, если только не замените варианты модели или стили LoRA.
- Запрос
- Введите описание сцены и опциональные отрицания. Текст кодируется как для положительного, так и для отрицательного кондиционирования и сочетается с выбранной частотой кадров, чтобы планирование движения соответствовало временным рамкам. Держите язык в курсе времени с глаголами, описывающими изменения, например, "камера движется вперёд" или "листья кружатся на ветру". Отрицательные запросы помогают избежать нежелательных артефактов, таких как водяные знаки или мультяшные упрощения.
- Улучшение Запроса
- Граф включает помощника, который анализирует ваше изображение и текст, затем генерирует более сильный, временно ориентированный черновик запроса, который вы можете принять или отредактировать. Это облегчает управление LTX 2.3 Изображение в Видео в направлении кинематографических, ориентированных на действие описаний. Это особенно полезно, когда вы начинаете с одного статического изображения и хотите, чтобы движение ощущалось намеренным. Узел предварительного просмотра позволяет вам проверить улучшенный текст перед генерацией.
- Настройки Видео
- Выберите, хотите ли вы запустить изображение в видео или переключиться на текст в видео с помощью простого переключателя. Установите ширину, высоту, продолжительность и частоту кадров в соответствии с вашей целевой платформой. Эти настройки определяют распределение латентного и последующее декодирование, поэтому держите их в соответствии с вашим творческим замыслом. Если вы планируете широко публиковать, отдавайте предпочтение размерам и временным рамкам, которые совместимы с кодеком.
- Предобработка Изображения
- Ваш первый кадр изменяется в размере и нормализуется до аспекта, подходящего для модели, при этом сохраняется композиция. Лёгкий предварительный фильтр помогает стабилизировать края и уменьшить шум компрессии, который может вызывать мерцание во время движения. Этот шаг важен, даже если вы используете изображение только для предложения компоновки и цвета.
- Пустой Латент
- Рабочий процесс выделяет пустые латентные видео и аудио на основе ваших размеров, продолжительности и частоты кадров. Это обеспечивает чистое полотно для выборщика и гарантирует, что аудио и видео остаются выровненными по длине. Шум генерируется детерминированно, когда вы хотите воспроизводимость, или случайным образом для вариаций между запусками.
- Генерация Низкого Разрешения
- Первая выборка вырезает движение и структуру в компактное латентное видео. Если вы используете изображение в видео,
LTXVImgToVideoInplace(#249) внедряет ваш первый кадр в качестве визуального якоря, чтобы движение развивалось от согласованной отправной точки. Кондиционирование из вашего положительного и отрицательного текста направляет содержимое и стиль, в то время какManualSigmas(#252) иKSamplerSelectопределяют, насколько агрессивно шум удаляется с течением времени.LTXVCropGuides(#212) помогает сохранить кадрирование, соответствующее вашему запросу. Полученное латентное аудио-видео затем разделяется для отдельной обработки.
- Первая выборка вырезает движение и структуру в компактное латентное видео. Если вы используете изображение в видео,
- Латентное Увеличение
- Перед тем как приступить к уточнению высокого разрешения,
LTXVLatentUpsampler(#253) применяет x2 пространственный увеличитель к латенту низкого разрешения. Делать это в латентном пространстве быстро и сохраняет изученное движение, увеличивая при этом детализацию. Это безопасный способ добавить чёткость без введения артефактов.
- Перед тем как приступить к уточнению высокого разрешения,
- Генерация Высокого Разрешения
- Второй выборщик уточняет увеличенный латент при большем пространственном размере, чтобы зафиксировать текстуры, освещение и мелкие движения. При запуске текста в видео, ранний шаг изображения в видео можно обойти, и
LTXVImgToVideoInplace(#230) просто пропускает латент.VAEDecodeTiled(#251) затем эффективно декодирует латент видео в кадры. Параллельно, латентное аудио декодируется с помощью LTX Audio VAE, так что оба потока оказываются точными по кадрам.
- Второй выборщик уточняет увеличенный латент при большем пространственном размере, чтобы зафиксировать текстуры, освещение и мелкие движения. При запуске текста в видео, ранний шаг изображения в видео можно обойти, и
- Экспорт
CreateVideo(#242) объединяет кадры и аудио в одно видео с выбранной частотой кадров. Узел верхнего уровняSaveVideoзаписывает финальный файл в ваш вывод ComfyUI, чтобы вы могли сразу его скачать. Ваш рендер LTX 2.3 Изображение в Видео теперь готов для предварительного просмотра или публикации.
Ключевые узлы в рабочем процессе ComfyUI LTX 2.3 Изображение в Видео#
LTXVImgToVideoInplace(#249 и #230)- Превращает статическое изображение в латентное видео или пропускает латент при отключении. Используйте его, когда хотите, чтобы первый кадр определял компоновку, палитру и расположение персонажей. Переключите переключатель текста в видео, если предпочитаете, чтобы движение возникало исключительно из запроса. Документация для семейства операторов поддерживается в интеграции ComfyUI на GitHub.
LTXVConditioning(#239)- Комбинирует закодированный положительный и отрицательный текст с вашей частотой кадров для создания кондиционирования, которое направляет как содержимое, так и темп движения. Отдавайте предпочтение коротким, ясным предложениям, описывающим изменения с течением времени, и резервируйте отрицания для артефактов, которые вы постоянно видите и хотите подавить. Этот узел является наиболее эффективным местом для настройки стиля и поведения сцены без изменения выборщиков.
ManualSigmas(#252) сKSamplerSelect- График шума и выборщик работают вместе, чтобы сбалансировать большое движение и мелкие детали. Более высокий ранний шум способствует более широкому движению, в то время как поздние шаги консолидируют текстуру. Настраивайте их только после того, как у вас будут хорошие запросы и визуальное руководство. Основные элементы управления выборкой следуют стандартной семантике ComfyUI, см. ссылочные реализации в репозитории LTX на GitHub.
LTXVLatentUpsampler(#253)- Применяет пространственный увеличитель LTX 2.3 в латентном пространстве, чтобы вы могли уточнять при более высоком разрешении на следующем этапе. Используйте его, когда вам нужна дополнительная чёткость или вы планируете доставлять более крупные форматы. Модель x2 распространяется с LTX 2.3 на Hugging Face.
VAEDecodeTiled(#251) иCreateVideo(#242)- Плиточное декодирование предотвращает всплески памяти при более высоких разрешениях и обеспечивает последовательное качество кадров.
CreateVideoзатем собирает кадры и декодированный аудиотрек в финальный MP4 с выбранной частотой кадров. Держите вашу частоту кадров согласованной со значением, использованным при кондиционировании, чтобы избежать дрейфа при воспроизведении.
- Плиточное декодирование предотвращает всплески памяти при более высоких разрешениях и обеспечивает последовательное качество кадров.
Дополнительные возможности#
- Вы всё равно должны загрузить изображение первого кадра, даже если используете текст в видео. Переключатель игнорирует его во время генерации, но интерфейс требует изображения-заполнителя.
- Для запроса LTX 2.3 Изображение в Видео, начните с основного действия, затем визуальные детали, затем атмосфера. Временные слова, такие как "медленно", "вдруг" и "продолжает", помогают модели планировать движение.
- Используйте отрицательные запросы, чтобы избежать наложений и артефактов интерфейса, таких как "водяной знак", "субтитры" или "статический кадр".
- Если стиль выглядит слишком сильным или слишком слабым, попробуйте другой LoRA или отрегулируйте его вес в загрузчике LoRA. Вы также можете удалить LoRA, чтобы полагаться на внешний вид базовой модели.
- Повторите фиксированное семя шума для воспроизводимости при итерации текста, затем рандомизируйте для вариации, как только вы зафиксируете кадр.
Благодарности#
Этот рабочий процесс реализует и основывается на следующих работах и ресурсах. Мы выражаем благодарность Lightricks за LTX-2.3 и EyeForAILabs за YouTube Tutorial EyeForAILabs за их вклад и поддержку. Для авторитетных деталей, пожалуйста, обратитесь к оригинальной документации и репозиториям, приведённым ниже.
Ресурсы#
- Lightricks/LTX-2.3
- GitHub: Lightricks/LTX-2
- Hugging Face: Lightricks/LTX-2.3
- arXiv: LTX-2: Efficient Joint Audio-Visual Foundation Model
- EyeForAILabs/YouTube Tutorial
- Документация / Заметки о выпуске: EyeForAILabs YouTube Tutorial
Примечание: Использование упомянутых моделей, наборов данных и кода подлежит соответствующим лицензиям и условиям, предоставленным их авторами и поддерживающими.