
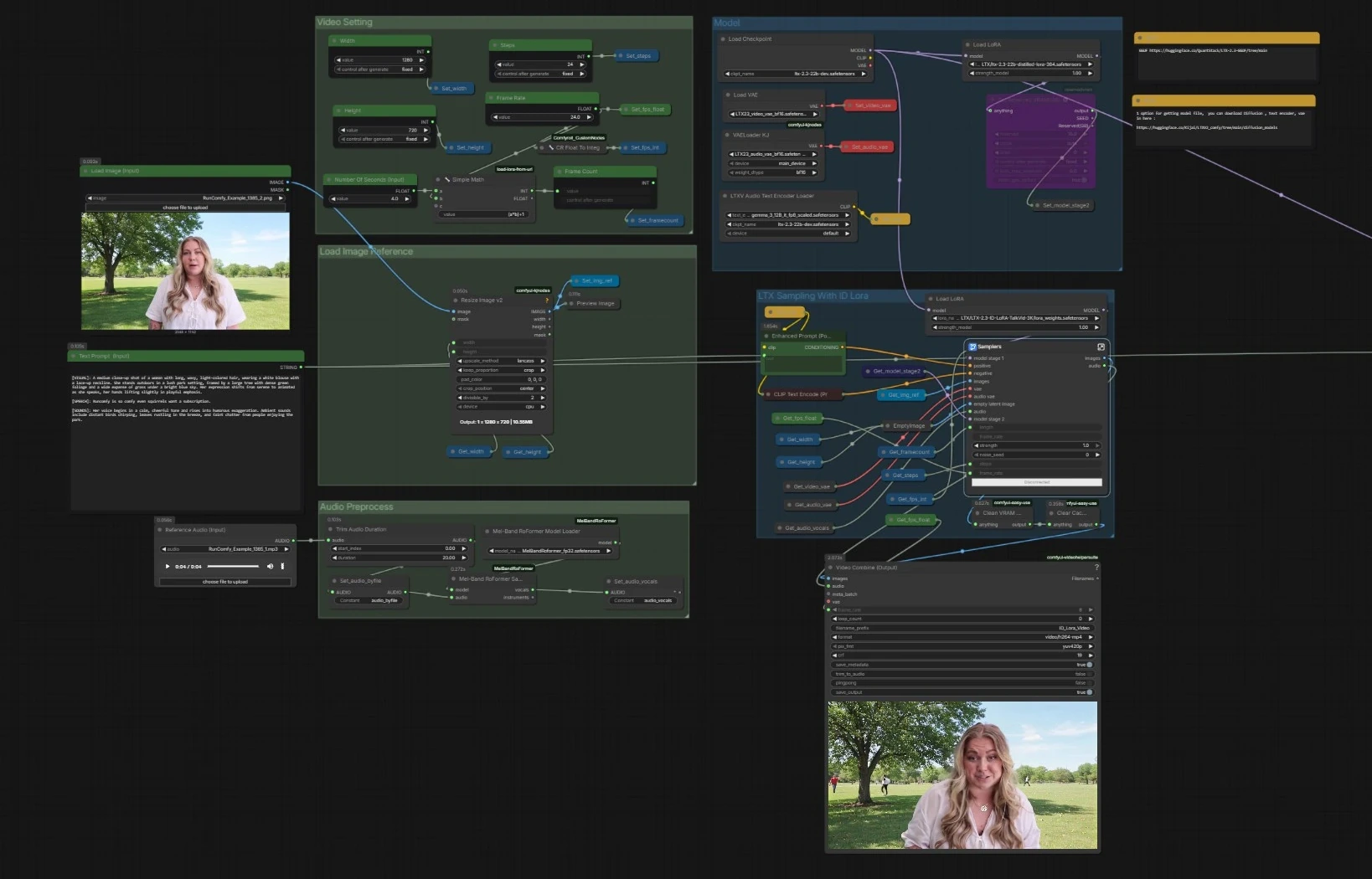
Процесс создания говорящих видео LTX 2.3 ID-LoRA для ComfyUI#
Этот процесс превращает одно изображение лица, короткий голосовой клип и подсказку в полностью синхронизированное говорящие видео. Основанный на LTX-2.3, он объединяет аудио и визуальные эффекты в одном процессе диффузии и добавляет адаптер идентичности In-Context LoRA, чтобы человек на вашем эталонном изображении оставался постоянным на всех кадрах. LTX 2.3 ID-LoRA идеально подходит для аватаров, виртуальных ведущих и любых сценариев, где синхронизация губ, сходство и управление подсказками должны совпадать в одном проходе.
Вы предоставляете три вещи: эталонное изображение, одно или два предложения аудио и текстовую подсказку, описывающую внешний вид и исполнение. Путь LTX 2.3 ID-LoRA обрабатывает идентичность, а легкий аудиопроцессор улучшает четкость голоса для более сильных подсказок для рта. Результат — это связное видео, сохраняющее идентичность, с синхронизированной речью, которое не требует обучения для каждого субъекта.
Основные модели в процессе LTX 2.3 ID-LoRA для Comfyui#
- Базовая контрольная точка Lightricks LTX-2.3 22B. Совместная аудио-видео модель, которая генерирует синхронизированные кадры и звук из текста, изображения и аудио. Это основной генератор, используемый в этом конвейере ComfyUI. Модельная карта
- Дистиллированный LoRA 384 LTX-2.3. Официальный адаптер LoRA, который применяет дистиллированное руководство к базовой модели для стабилизации и ускорения семплирования без потери качества. Он подключен в качестве второй модели на этом этапе. См. таблицу контрольных точек на странице LTX-2.3. Модельная карта
- Пространственный увеличитель LTX-2.3 x2. Увеличитель в латентном пространстве, используемый внутри подграфа семплера, чтобы повысить пространственную детальность перед декодированием, улучшая верность лица и краев в финальном видео. Модельная карта
- Текстовый энкодер Gemma 3 12B Instruct для LTX-2.3. Обеспечивает текстовое условие, которое определяет стиль, сцену и исполнение. Этот процесс использует энкодер Gemma 3, упакованный для LTX-2 в ComfyUI. Текстовые энкодеры Comfy-Org
- VAE для видео и аудио LTX-2.3. Специально созданные VAE декодируют визуальные и акустические латенты, произведенные моделью, в изображения и звуковую волну. Совместимые сборки bf16 упоминаются в графе. Примеры источников: Видео VAE · Аудио VAE
- Mel-Band RoFormer для разделения вокала. Дополнительный процессор, который извлекает чистый вокал из эталонного аудио, чтобы модель могла более надежно отслеживать слоги и формы рта. Статья · Узел ComfyUI
- LTX 2.3 ID-LoRA (IC-LoRA). In-context LoRA идентичности, обученный для использования в говорящих видео, который склоняет генератор к лицу на вашем эталонном изображении, уважая подсказки и голосовые сигналы. Lightricks документирует использование LoRA и IC-LoRA с LTX-2.3 на странице модели. Модельная карта
Как использовать процесс LTX 2.3 ID-LoRA в Comfyui#
Общий поток. Конвейер загружает базу LTX-2.3 с текстовыми энкодерами и VAE, подготавливает ваше изображение и аудио, затем запускает двухэтапный семплер LTX, который объединяет текст, эталон лица и голосовую дорожку для генерации синхронизированных кадров и речи. Параллельный семплер без ID-LoRA включен для быстрых сравнений. Финальные кадры и аудио объединяются в MP4.
- Модель
- Граф загружает базовую контрольную точку с помощью
CheckpointLoaderSimple(#5493), текстовые энкодеры на основе Gemma черезLTXAVTextEncoderLoader(#5494) и специализированные VAE для видеоVAELoader(#5651) и аудиоVAELoaderKJ(#5649). Затем применяются два адаптера: официальный дистиллированный LoRA для формирования модели второго этапа и LTX 2.3 ID-LoRA для кондиционирования идентичности черезLoraLoaderModelOnly(#5573). - Этот этап обеспечивает, чтобы генератор понимал вашу подсказку, имел правильные стеки декодирования и был настроен как на эффективность, так и на предвзятость идентичности.
- Вы обычно не изменяете здесь ничего, кроме замены контрольных точек или LoRA, если у вас есть альтернативы.
- Граф загружает базовую контрольную точку с помощью
- Настройка видео
- Управляет выходными размерами, частотой кадров, шагами и длиной.
Width(#5284),Height(#5286) иFrame Rate(#5289) подают небольшую утилиту, которая вычисляет общее количество кадров из секунд, поддерживая согласованность времени между аудио и видео. - Настройки хранятся один раз и читаются всеми нижестоящими узлами, чтобы два семплера и мюксер оставались согласованными.
- Измените эти значения в первую очередь, когда хотите изменить аспект, плавность или продолжительность.
- Управляет выходными размерами, частотой кадров, шагами и длиной.
- Загрузка эталонного изображения
- Предоставьте одно четкое изображение лица через
Load Image (Input)(#5525). Изображение изменяется с помощьюImageResizeKJv2(#5280), чтобы соответствовать выбранному выходу. - Это предварительно обработанное изображение становится якорем для идентичности на этапе LTX 2.3 ID-LoRA, направляя сходство и композицию кадра.
- Используйте хорошо освещенную, фронтальную фотографию с минимальным размытием движения для лучших результатов.
- Предоставьте одно четкое изображение лица через
- Предобработка аудио
- Вставьте короткий WAV или MP3, используя
Reference Audio (Input)(#5652). Клип при необходимости обрезается, а затем передается вMelBandRoFormerSampler(#5473) для изоляции вокала. - Чистый вокал помогает модели предполагать фонемы и время для точных движений губ и ритма речи.
- Если ваше аудио уже только голосовое, вы можете пропустить разделение и подать его напрямую.
- Вставьте короткий WAV или MP3, используя
- Семплирование LTX с ID LoRA
- Это основной путь. Подграф семплера (
Samplers(#5278)) объединяет вашу положительную подсказку изEnhanced Prompt (Positive)(#5174), отрицательный список, эталон лица и голосовую дорожку через латентный конвейер LTX-2.3 AV. LTXVReferenceAudioсинхронизирует движение с речью, в то время какLTXVImgToVideoInplaceвводит изображение лица в латент как пространственный якорь. Адаптер LTX 2.3 ID-LoRA направляет генератор к идентичности вашего субъекта.- Этап включает внутренний латентный увеличитель для повышения детализации перед декодированием. Он выводит кадры плюс синхронизированный аудиопоток.
- Это основной путь. Подграф семплера (
- Семплирование LTX без ID LoRA
- Зеркальный семплер (
Samplers(#5643)) выполняет то же кондиционирование, но без адаптера ID-LoRA. Используйте это для A/B проверок или когда хотите больше свободы от эталонной идентичности. - Всё остальное остается идентичным, поэтому различия, которые вы замечаете, обусловлены только кондиционированием идентичности.
- Этот путь может быть полезен для быстрых черновиков или творческих отступлений.
- Зеркальный семплер (
- Объединение видео и вывод
- Кадры и сгенерированное аудио объединяются в MP4 с помощью
Video Combine (Output)(#5218). Частота кадров берется из вашего глобального настроения, так что движение и синхронизация губ совпадают с временем семплера. - Вторичный
Video Combine(#5645) предварительно просматривает ветвь без ID-LoRA, если вы её включили, что полезно для сравнений. - Процесс очищает кеш между запусками, чтобы поддерживать стабильность VRAM на длинных сеансах.
- Кадры и сгенерированное аудио объединяются в MP4 с помощью
Ключевые узлы в процессе LTX 2.3 ID-LoRA для Comfyui#
LoraLoaderModelOnly(#5573)- Загружает LTX 2.3 ID-LoRA, который сохраняет идентичность лица. Уменьшите его вес, если хотите больше творческой вариативности, или увеличьте, чтобы более строго закрепить сходство. Подбирайте его тщательно с силой подсказки, чтобы идентичность и стиль не конкурировали. Справка: использование LTX-2.3 LoRA на странице модели. Модельная карта
LTXVReferenceAudio(#5589)- Преобразует ваше эталонное аудио в кондиционирование для времени слогов, просодии и форм рта. Подайте чистую речь для лучшего согласования. Если вы слышите пульсацию или не в такт артикуляцию, укоротите или упростите клип, а не увеличивайте силу.
LTXVImgToVideoInplace(#5245, также используется позже)- Внедряет изображение лица в латентный видеопоток как пространственный приоритет. Контроль силы изображения балансирует соблюдение фотографии против свободы движения. Для сильной идентичности с естественным движением держите силу изображения умеренной и позвольте ID-LoRA нести сходство.
LTXVConditioning(#5621)- Упаковывает текстовое кондиционирование и временные подсказки для семплеров LTX. Убедитесь, что его входная частота кадров совпадает с вашей выходной частотой кадров, чтобы поля движения и время фонем оставались согласованными.
VHS_VideoCombine(#5218)- Объединяет кадры и аудио в финальный файл. Если ваше аудио немного длиннее кадров, включите обрезку здесь, чтобы предотвратить появление черного хвоста. Для совместимости с платформами сохраняйте настройки H.264 по умолчанию, если у вас нет причин их изменять. Ссылка на узел: ComfyUI-VideoHelperSuite
MelBandRoFormerSampler(#5473)- Разделяет вокал от музыки, используя трансформер Mel-band, чтобы генератор фиксировался на речи. Если шипящие звуки размазываются или взрывные звуки выпячиваются, попробуйте другой файл модели из той же семьи или уменьшите входную громкость. Фоновое чтение: arXiv
Дополнительные возможности#
- Для наиболее стабильных генераций с LTX-2.3 используйте ширину и высоту, делимые на 32, и выбирайте количество кадров 8n + 1, как задокументировано Lightricks. Модельная карта
- Сохраняйте эталонное изображение согласованным с вашей подсказкой. Если вы описываете уличное освещение, но предоставляете фотографию в помещении, идентичность может сохраниться, в то время как цвет и освещение будут бороться с подсказкой.
- Дайте аудио от 2 до 8 секунд с естественным темпом. Слишком сжатые или реверберирующие клипы снижают точность синхронизации губ, даже после разделения вокала.
- Когда лица смещаются, слегка уменьшите силу изображения и полагайтесь больше на LTX 2.3 ID-LoRA. Когда лица слишком сильно блуждают, поступайте наоборот.
- Для более длительных дублей создавайте в сегментах, которые используют одно и то же зерно и глобальные настройки, затем объединяйте клипы в видеоредактировании, если необходимо.
Ссылки и полезные репозитории#
- Открытые веса и заметки LTX-2.3: Страница модели на Hugging Face
- Официальные узлы ComfyUI для видео LTX: Lightricks/ComfyUI-LTXVideo
- Кодовая база LTX-2 и статья: Lightricks/LTX-Video · arXiv
- Текстовые энкодеры Gemma 3 12B IT для LTX в ComfyUI: Comfy-Org/ltx-2 text_encoders
- Фон Mel-Band RoFormer: arXiv
Благодарности#
Этот процесс реализует и опирается на следующие работы и ресурсы. Мы с благодарностью признаем создателей LTX 2.3 ID-LoRA Source за процесс LTX 2.3 ID-LoRA Source за их вклад и поддержку. Для авторитетных деталей, пожалуйста, обратитесь к оригинальной документации и репозиториям, указанным ниже.
Ресурсы#
- LTX 2.3 ID-LoRA Source
- Документы / Примечания к выпуску: YouTube @Benji's AI Playground
Примечание: Использование указанных моделей, наборов данных и кода подлежит соответствующим лицензиям и условиям, предоставленным их авторами и поддерживающими.