
LTX-2.3 ICLoRA LipDub для ComfyUI#
LTX-2.3 ICLoRA LipDub — это двухпроходный рабочий процесс ComfyUI, управляемый видео и аудио, который дублирует говорящего человека, сохраняя идентичность и движение. Он объединяет текстовое и видео кондиционирование Lightricks LTX-2.3 с LipDub IC-LoRA для точного согласования движения рта с предоставленной речью, а затем уточняет результат в более высоком разрешении для четкости деталей. График подготовлен для RunComfy с стандартизированными именами входных и выходных данных, чтобы вы могли надежно менять медиа и повторять запуски.
Этот рабочий процесс ComfyUI LTX-2.3 ICLoRA LipDub идеально подходит для создателей, которым требуется многоязычное дублирование, перефразирование или исправления, подобные ADR, сохраняя при этом оригинальное исполнение. Предоставьте исходное видео, которое уже включает целевую речь, опишите сцену и что человек должен сказать, и рабочий процесс синтезирует синхронизированные визуальные и аудио материалы в готовый клип.
Основные модели в рабочем процессе ComfyUI LTX-2.3 ICLoRA LipDub#
- LTX-2.3 22B базовая видеомодель. Основная диффузионная модель, которая генерирует видео и управляет тем, как подсказки влияют на внешний вид, движение и стиль.
- LTX-2.3 IC-LoRA LipDub. Специализированная LoRA для дублирования губ, которая настраивает модель на следование предоставленной речи и выравнивание форм рта по фонемам, сохраняя идентичность и движение головы. Модельная карта
- LTX-2.3 Audio VAE. Кодирует входную речь в аудиолатент, который может быть введен в текстовое кондиционирование и затем декодирован обратно в форму волны, обеспечивая сохранение синхронизации с кадрами.
- LTX-2.3 Spatial Upscaler x2. Увеличивает пространственное разрешение видеолатентов перед проходом уточнения в высоком разрешении, улучшая текстуру без изменения движения.
- LTX-2.3 Distilled LoRA (384). Усиливающая LoRA, используемая вместе с базовой контрольной точкой для улучшения деталей и временной стабильности без чрезмерного подгонки к контрольному кадру.
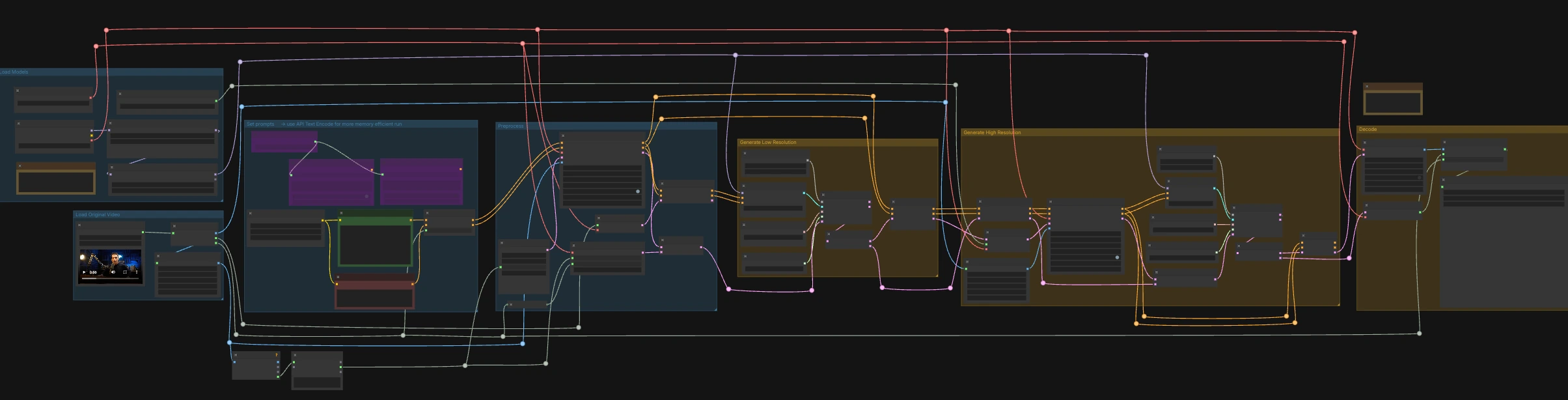
Как использовать рабочий процесс ComfyUI LTX-2.3 ICLoRA LipDub#
Этот рабочий процесс выполняется в двух скоординированных стадиях: проход с низким разрешением для фиксации времени и форм губ по аудио, за которым следует проход с высоким разрешением, который увеличивает и уточняет детали, сохраняя синхронизацию. Начните с загрузки исходного видео, которое уже содержит речь, которую вы хотите, затем напишите текст, который вы хотите, чтобы человек сказал.
Загрузить оригинальное видео#
Узел LoadVideo (#5002) импортирует ваш исходный клип с встроенным аудио. GetVideoComponents (#5010) извлекает кадры, аудио и частоту кадров; частота кадров разделяется по всему графику, чтобы видео и аудио оставались синхронизированными. Два ресайзера, Resize Image/Mask (s1 size) (#5009) и Resize Image/Mask (s2 size) (#5003), подготавливают рабочие потоки изображений для проходов с низким и высоким разрешением. Количество кадров измеряется и округляется для удобной длины для самплера, чтобы декодирование оставалось стабильным.
Загрузить модели#
CheckpointLoaderSimple (#5017) загружает базовую модель LTX-2.3 22B и VAE, используемые по всему графику. Два загрузчика, LoraLoaderModelOnly (#5018) и LTXICLoRALoaderModelOnly (#5012), добавляют дистиллированную LoRA и IC-LoRA LipDub поверх базы, чтобы генератор следовал речи, сохраняя идентичность. LTXVAudioVAELoader (#4010) предоставляет аудио VAE для кодирования/декодирования саундтрека. Выход latent_downscale_factor загрузчика IC-LoRA здесь намеренно не используется, поскольку обучение LipDub предполагает полноразмерные контрольные кадры, соответствующие включенной заметке.
Установить подсказки#
Напишите описание сцены и точную произнесенную реплику в CLIP Text Encode (Positive Prompt) (#2483). Используйте CLIP Text Encode (Negative Prompt) (#2612) для минимизации нежелательных черт или артефактов. Эти данные поступают в LTXVConditioning (#1241), которое адаптирует кондиционирование к видео домену и переносит контекст частоты кадров дальше. Для запусков с низким VRAM график также включает API-базированные энкодеры (🅛🅣🅧 Gemma API Text Encode - POSITIVE (#4980) и ... - NEGATIVE (#4981)), управляемые строкой LTX API KEY (#4979); по умолчанию используется локальные энкодеры.
Предварительная обработка#
LTXVAudioVAEEncode (#5005) преобразует исходную речь в аудиолатент, а LTXVSetAudioRefTokens (#5006) вводит этот латент в текстовое кондиционирование, чтобы генератор "слышал" время и фонемы. EmptyLTXVLatentVideo (#3059) подготавливает видео латент с правильным пространственным размером и количеством кадров, выровненным по входу. LTXAddVideoICLoRAGuide (#5004) прикрепляет руководство IC-LoRA с использованием кадров s1, устанавливая идентичность и внимание к области рта перед выборкой.
Генерация в низком разрешении#
Стандартный диффузионный цикл формируется с помощью CFGGuider (#4828), KSamplerSelect (#4831), ManualSigmas (#4984) и SamplerCustomAdvanced (#4829). Самплер работает на аудио+видео латенте, составленном LTXVConcatAVLatent (#4528), обеспечивая участие аудиокондиционирования на каждом шаге. После выборки LTXVSeparateAVLatent (#4845) разделяет латент, чтобы LTXVSetAudioRefTokens (#5013) мог зафиксировать то же представление речи для прохода с высоким разрешением. Этот этап фиксирует формы губ по речи и устанавливает базовую линию движения на размер s1.
Генерация в высоком разрешении#
LTXVLatentUpsampler (#4975) поднимает видео латент с использованием Spatial Upscaler x2, сохраняя движение, добавляя возможность для пространственных деталей. LTXAddVideoICLoRAGuide (#5014) повторно применяет IC-LoRA на размере s2 с использованием кадров более высокого разрешения, чтобы идентичность, область рта и мелкие особенности были усилены. Второй диффузионный цикл (CFGGuider (#4964), KSamplerSelect (#4976), ManualSigmas (#4985), SamplerCustomAdvanced (#4971)) уточняет увеличенный латент, в то время как LTXVConcatAVLatent (#4969) поддерживает замороженный аудиолатент в синхронизации. LTXVCropGuides (#5011, #5015) управляет безопасными обрезками и руководствами по регионам, чтобы лицо оставалось правильно кадрированным на протяжении обоих проходов.
Декодирование#
LTXVTiledVAEDecode (#4995) преобразует конечный видео латент в изображения с использованием тайлов для эффективности VRAM, а LTXVAudioVAEDecode (#4848) возвращает синхронизированное аудио. CreateVideo (#4849) собирает кадры и аудио с оригинальной частотой кадров, а SaveVideo (#4852) записывает файл с предзаполненным именем RunComfy; измените это значение, чтобы брендировать свои выходные данные. Результат — полностью синхронизированный клип LTX-2.3 ICLoRA LipDub, готовый для просмотра или доставки.
Основные узлы в рабочем процессе ComfyUI LTX-2.3 ICLoRA LipDub#
LTXICLoRALoaderModelOnly (#5012)#
Загружает LipDub IC-LoRA и прикрепляет его к базовой модели, чтобы движение губ следовало входной речи без замещения идентичности. Если вам нужно более сильное или более слабое управление губами, отрегулируйте вес LoRA здесь; держите его скоординированным с любой дополнительной LoRA, которую вы применяете в стеке, чтобы избежать чрезмерного кондиционирования.
LTXAddVideoICLoRAGuide (#5004)#
Применяет руководство IC-LoRA на стадии низкого разрешения с использованием уменьшенных контрольных кадров. Здесь рабочий процесс сначала фиксирует идентичность и внимание к области рта; используйте его для A/B тестирования, включая/выключая руководство, чтобы увидеть эффект контрольного руководства на время и артикуляцию.
LTXAddVideoICLoRAGuide (#5014)#
Повторно применяет руководство IC-LoRA с высоким разрешением с кадрами s2, чтобы уточненный проход сохранял ту же идентичность говорящего и точные формы губ. Если вы измените размер кадра с высоким разрешением, пересмотрите этот узел, чтобы сохранить руководство в соответствии с вашим целевым выходом.
LTXVSetAudioRefTokens (#5006)#
Привязывает закодированную речь к текстовому кондиционированию, чтобы самплер выравнивал виземы с фонемами. Используйте тот же аудиолатент для обоих проходов для стабильных результатов; этот график обрабатывает это автоматически, но если вы меняете аудио в середине запуска, вам следует обновить как кондиционирование, так и объединенный латент.
LTXVLatentUpsampler (#4975)#
Увеличивает видео латент с помощью LTX-2.3 Spatial Upscaler x2, чтобы сделать место для мелких деталей перед самплером с высоким разрешением. Если VRAM ограничен, сочетайте это с меньшими размерами s2 или более легким тайлингом в декодере, чтобы сбалансировать качество и производительность.
LTXVTiledVAEDecode (#4995)#
Декодирует конечный латент в кадры с использованием тайлинга, чтобы вместить большие выходы на ограниченных GPU. Настройте количество тайлов и перекрытие здесь, чтобы обменять скорость на память; меньшее количество тайлов быстрее, но требует больше VRAM, в то время как больше тайлов уменьшает VRAM за счет времени.
Дополнительные возможности#
- Подсказки для дублирования: включите точные слова, которые вы хотите, чтобы были произнесены; модель не переводит автоматически. Используйте родной скрипт целевого языка, придерживайтесь одного говорящего и стремитесь к аналогичной длине оригинальной реплики, чтобы темп оставался естественным.
- Советы по производительности: если вы достигли пределов VRAM, уменьшите размер s2 в
Resize Image/Mask (s2 size)(#5003) и увеличьте тайлинг вLTXVTiledVAEDecode(#4995). Для повторяемости держите семенаRandomNoiseфиксированными в обоих проходах. - Настройки по умолчанию рабочего процесса: примерное имя входного файла предзаполнено в
LoadVideo(#5002), а сохраняющий устанавливает согласованное имя выхода. Замените оба, чтобы выполнять несколько запусков LTX-2.3 ICLoRA LipDub без перезаписи результатов. - Кадрирование: если лицо дрейфует к краям, отрегулируйте
LTXVCropGuides(#5011, #5015), чтобы область рта оставалась в стабильном кадре на протяжении обоих проходов.
Благодарности#
Этот рабочий процесс реализует и основывается на следующих работах и ресурсах. Мы благодарно признаем Lightricks за модель LTX-2.3-22b-IC-LoRA-LipDub и RunComfy за общий рабочий процесс ComfyUI (источник Cloud Save) за их вклад и поддержку. Для получения авторитетных деталей, пожалуйста, обратитесь к оригинальной документации и репозиториям, связанным ниже.
Ресурсы#
- Lightricks/LTX-2.3-22b-IC-LoRA-LipDub
- GitHub: Lightricks/LTX-2
- Hugging Face: Lightricks/LTX-2.3-22b-IC-LoRA-LipDub
- arXiv: arXiv:2601.22143
- RunComfy/Cloud Save source
- Документы / Примечания к выпуску: RunComfy shared workflow
Примечание: использование упомянутых моделей, наборов данных и кода подлежит соответствующим лицензиям и условиям, предоставленным их авторами и поддерживающими.
