
LTX 2.3 LoRA ComfyUI Инференс: выход LoRA AI Toolkit, соответствующий обучению, с использованием конвейера LTX 2.3#
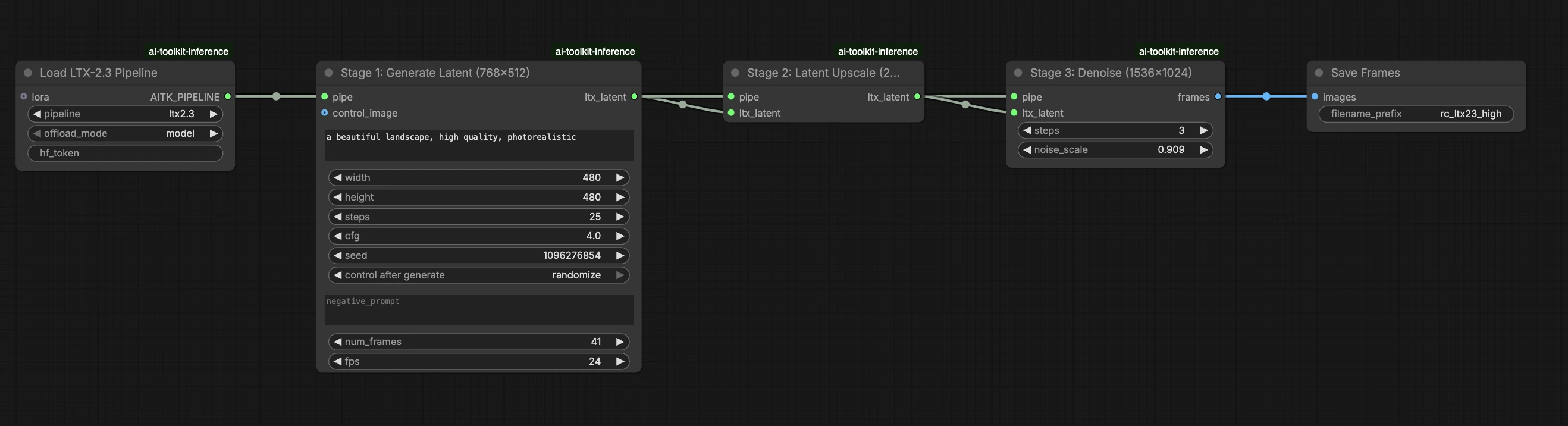
Этот готовый к производству рабочий процесс RunComfy выполняет инференс LTX 2.3 LoRA в ComfyUI через RC LTX 2.3 (LTX2Pipeline) (согласование на уровне конвейера, а не общий граф сэмплера). RunComfy создал и опубликовал этот пользовательский узел — смотрите репозитории runcomfy-com — и вы управляете применением адаптера с помощью lora_path и lora_scale.
Примечание: для выполнения этого рабочего процесса требуется машина не менее 2X Large.
Почему LTX 2.3 LoRA ComfyUI Инференс часто выглядит иначе в ComfyUI#
Предпросмотры обучения AI Toolkit рендерятся через специфический для модели конвейер LTX 2.3, где текстовое кодирование, планирование и внедрение LoRA разработаны для совместной работы. В ComfyUI перестройка LTX 2.3 с другим графом (или другим путем загрузки LoRA) может изменить эти взаимодействия, поэтому копирование одного и того же запроса, шагов, CFG и семени все равно приводит к заметному отклонению. Узлы конвейера RunComfy RC устраняют этот разрыв, выполняя LTX 2.3 от начала до конца в LTX2Pipeline и применяя ваш LoRA внутри этого конвейера, поддерживая инференс в соответствии с поведением предпросмотра. Источник: открытые репозитории RunComfy.
Как использовать рабочий процесс LTX 2.3 LoRA ComfyUI Инференс#
Шаг 1: Получите путь LoRA и загрузите его в рабочий процесс (2 варианта)#
Вариант A — Результат обучения RunComfy → загрузка в локальный ComfyUI:
- Перейдите на Тренер → Активы LoRA
- Найдите LoRA, который вы хотите использовать
- Нажмите на ⋮ (три точки) в меню справа → выберите Копировать ссылку LoRA
- На странице рабочего процесса ComfyUI, вставьте скопированную ссылку в поле ввода Загрузить в правом верхнем углу интерфейса
- Перед нажатием Загрузить, убедитесь, что целевая папка установлена на ComfyUI > models > loras (эта папка должна быть выбрана как цель загрузки)
- Нажмите Загрузить — это гарантирует, что файл LoRA сохранен в правильный каталог
models/loras - После завершения загрузки, обновите страницу
- LoRA теперь появляется в выпадающем списке выбора LoRA в рабочем процессе — выберите его
Вариант B — Прямой URL LoRA (заменяет Вариант A):
- Вставьте прямой URL загрузки
.safetensorsв поле вводаpath / urlузла LoRA - Когда здесь указан URL, он заменяет Вариант A — рабочий процесс загружает LoRA непосредственно из URL во время выполнения
- Локальная загрузка или размещение файла не требуется
Совет: подтвердите, что URL ведет к фактическому файлу .safetensors (не на целевую страницу или перенаправление).
Шаг 2: Сопоставьте параметры инференса с настройками вашего обучающего образца#
В узле LoRA выберите ваш адаптер в lora_path (Вариант A), или вставьте прямую ссылку .safetensors в path / url (Вариант B заменяет выпадающий список). Затем установите lora_scale на ту же силу, которую вы использовали во время предпросмотров обучения, и регулируйте оттуда.
Оставшиеся параметры находятся на узле Generate (и, в зависимости от графа, узле Load Pipeline):
prompt: ваш текстовый запрос (включите триггерные слова, если вы обучали с ними)width/height: разрешение выхода; соответствуйте размеру предпросмотра обучения для наиболее чистого сравнения (рекомендуются кратные 32 для LTX 2.3)num_frames: количество кадров выходного видеоsample_steps: количество шагов инференса (30 — это обычное значение по умолчанию)guidance_scale: значение CFG/руководства (5.5 — это обычное значение по умолчанию; не превышайте 7)seed: фиксированное семя для воспроизведения; измените его, чтобы исследовать вариацииseed_mode(только если присутствует): выберитеfixedилиrandomizeframe_rate: выходные FPS; поддерживайте согласованность с настройками обучения для согласования движения
Совет по согласованию обучения: если вы настроили значения сэмплирования во время обучения (seed, guidance_scale, sample_steps, триггерные слова, разрешение), отразите эти значения здесь. Если вы обучались на RunComfy, откройте Тренер → Активы LoRA > Конфигурация, чтобы просмотреть разрешенный YAML и скопировать настройки предпросмотра/образца в узлы рабочего процесса.
Шаг 3: Запустите LTX 2.3 LoRA ComfyUI Инференс#
Нажмите Queue/Run — узел SaveVideo записывает результаты в вашу выходную папку ComfyUI.
Быстрый чек-лист:
- ✓ LoRA либо: загружен в
ComfyUI/models/loras(Вариант A), либо загружен через прямой URL.safetensors(Вариант B) - ✓ Страница обновлена после локальной загрузки (только Вариант A)
- ✓ Параметры инференса соответствуют конфигурации обучающего
sample(если настроены)
Если все вышеперечисленное верно, результаты инференса здесь должны быть близки к вашим предпросмотрам обучения.
Устранение неполадок LTX 2.3 LoRA ComfyUI Инференс#
Большинство расхождений между "предпросмотром обучения и инференсом в ComfyUI" LTX 2.3 связано с различиями на уровне конвейера (как модель загружается, планируется и как LoRA объединяется), а не с одной неправильной настройкой. Этот рабочий процесс RunComfy восстанавливает наиболее близкую "базовую линию, соответствующую обучению" путем выполнения инференса через RC LTX 2.3 (LTX2Pipeline) от начала до конца и применения вашего LoRA внутри этого конвейера через lora_path / lora_scale (вместо наложения общих узлов загрузчика/сэмплера).
(1) Несоответствия формы LoRA или предупреждения "ключ не загружен"#
Почему это происходит LoRA обучен для другой семейства моделей или другого варианта LTX. Вы увидите много строк lora key not loaded и, возможно, ошибки несоответствия формы.
Как исправить (рекомендуется)
- Убедитесь, что LoRA обучен специально для LTX 2.3 с AI Toolkit (LoRA для LTX 2.0 / 2.1 / 2.2 не взаимозаменяемы).
- Держите граф "однопутевым" для LoRA: загружайте адаптер только через вход
lora_pathрабочего процесса и позвольте LTX2Pipeline выполнять объединение. Не накладывайте дополнительный общий загрузчик LoRA параллельно. - Если вы уже столкнулись с несоответствием и ComfyUI начинает выдавать несвязанные ошибки CUDA/OOM после этого, перезапустите процесс ComfyUI, чтобы полностью сбросить состояние GPU + модели, затем повторите попытку с совместимым LoRA.
(2) Результаты инференса не соответствуют предпросмотрам обучения#
Почему это происходит Даже когда LoRA загружается, результаты могут все равно отклоняться, если ваш граф ComfyUI не соответствует конвейеру предпросмотра обучения (различные значения по умолчанию, различные пути внедрения LoRA, различное планирование).
Как исправить (рекомендуется)
- Используйте этот рабочий процесс и вставьте вашу прямую ссылку
.safetensorsвlora_path. - Скопируйте значения сэмплирования из конфигурации обучения AI Toolkit (или RunComfy Тренер → Активы LoRA Конфигурация):
width,height,num_frames,sample_steps,guidance_scale,seed,frame_rate. - Исключите "дополнительные скорости", если вы не обучали/сэмплировали с ними.
(3) Использование LoRA значительно увеличивает время инференса#
Почему это происходит LoRA может значительно замедлить LTX 2.3, когда путь LoRA вызывает дополнительную работу по патчированию/деквантизации или применяет веса в более медленном коде, чем базовая модель одна.
Как исправить (рекомендуется)
- Используйте путь RC LTX 2.3 (LTX2Pipeline) этого рабочего процесса и передайте ваш адаптер через
lora_path/lora_scale. В этой настройке LoRA объединяется один раз во время загрузки конвейера (в стиле AI Toolkit), так что стоимость сэмплирования на шаг остается близкой к базовой модели. - Если вы стремитесь к поведению, соответствующему предпросмотру, избегайте наложения нескольких загрузчиков LoRA или смешивания путей загрузчиков. Держитесь одного
lora_path+ одногоlora_scale, пока базовая линия не совпадет.
(4) Ошибки OOM на больших разрешениях или длинных видео#
Почему это происходит LTX 2.3 — это модель с 22B параметрами, и генерация видео требует много VRAM. Высокие разрешения или множество кадров могут превышать память GPU, особенно с накладными расходами LoRA.
Как исправить (рекомендуется)
- Используйте машину 2X Large (80 GB VRAM) или больше. Этот рабочий процесс не совместим с машинами Medium, Large или X Large.
- Уменьшите разрешение или количество кадров, если вам нужно быстро итератировать, затем увеличьте для окончательных рендеров.
- Включите VAE тайлинг, если доступно — это может сэкономить ~3 GB VRAM с минимальной потерей качества.
Запустите LTX 2.3 LoRA ComfyUI Инференс сейчас#
Откройте рабочий процесс, установите lora_path, и нажмите Queue/Run, чтобы получить результаты LTX 2.3 LoRA, которые остаются близки к вашим предпросмотрам обучения AI Toolkit.
