
Inferência Z-Image De-Turbo LoRA: geração com correspondência de treinamento e etapas mínimas no ComfyUI#
A Inferência Z-Image De-Turbo LoRA é um fluxo de trabalho RunComfy para executar adaptadores LoRA treinados pelo AI Toolkit no Z-Image De-Turbo no ComfyUI com comportamento correspondente ao treinamento. Ele utiliza o RC Z-Image De-Turbo (RCZimageDeturbo)—um nó personalizado de código aberto da RunComfy que alinha a inferência no nível de pipeline (não um gráfico de amostrador genérico) enquanto aplica seu adaptador via lora_path e lora_scale (source).
A maioria dos problemas de “visualização de treinamento vs inferência no ComfyUI” são desajustes de pipeline. RCZimageDeturbo resolve isso roteando o Z-Image De-Turbo através de um pipeline de inferência alinhado com a visualização e aplicando seu único LoRA dentro dele—então, quando você precisar de uma linha de base correspondente ao treinamento, comece com este fluxo de trabalho e espelhe seus valores de amostragem de visualização. Implementação de referência: `src/pipelines/flex1_alpha.py`.
O que o nó personalizado RCZimageDeturbo faz#
RCZimageDeturbo carrega o transformador De-Turbo de ostris/Z-Image-De-Turbo, emparelha-o com o codificador de texto/tokenizador/VAE de Tongyi-MAI/Z-Image-Turbo, e monta o pipeline explicitamente para evitar problemas de troca de meta-tensor—depois aplica seu adaptador via lora_path / lora_scale. Referência: `src/pipelines/flex1_alpha.py`
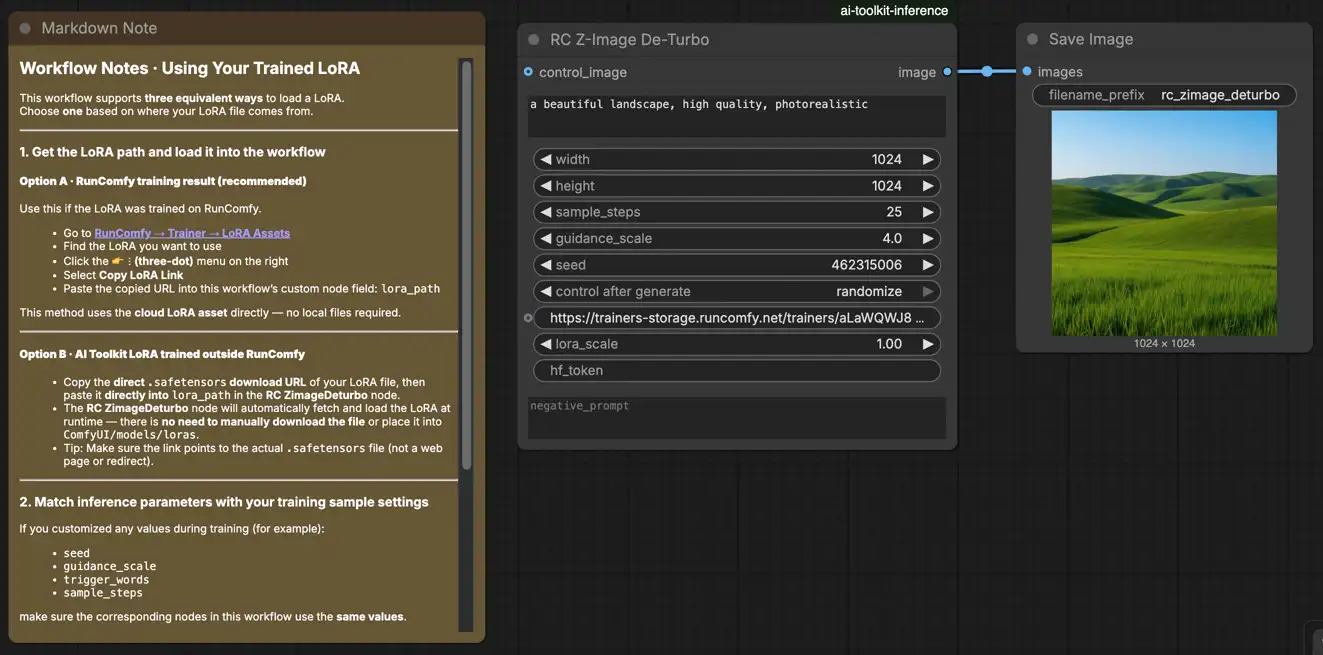
Como usar o fluxo de trabalho de Inferência Z-Image De-Turbo LoRA#
Etapa 1: Importe seu LoRA (2 opções)#
- Opção A (resultado de treinamento RunComfy): RunComfy → Treinador → Ativos LoRA → encontre seu LoRA → ⋮ → Copiar Link LoRA

- Opção B (LoRA do AI Toolkit treinado fora do RunComfy): Copie um link de download direto
.safetensorspara seu LoRA e cole esse URL emlora_path(não é necessário baixar emComfyUI/models/loras).
Etapa 2: Configure o nó personalizado RCZimageDeturbo para Inferência Z-Image De-Turbo LoRA#
Configure o restante das configurações para Inferência Z-Image De-Turbo LoRA (tudo na interface do nó):
prompt: seu prompt de texto (inclua os tokens de gatilho que você usou durante o treinamento, se houver)negative_prompt: opcional; mantenha vazio se sua amostragem de visualização não usou negativoswidth/height: resolução de saída (para comparações limpas, corresponda ao seu tamanho de visualização; múltiplos de 32 são recomendados)sample_steps: etapas de inferência (De-Turbo geralmente precisa de mais etapas do que gráficos no estilo “Turbo”; comece com a mesma contagem de etapas que você visualizou durante o treinamento)guidance_scale: força de orientação/CFG (corresponda ao seu valor de visualização primeiro, depois ajuste em pequenos incrementos)seed: defina uma semente fixa para reproduzir; mude para explorar variaçõeslora_scale: força do LoRA (comece perto da força de visualização, depois ajuste)
Dica de alinhamento de treinamento: espelhe os valores de amostragem do YAML de treinamento do AI Toolkit que você usou para visualizações—especialmente width, height, sample_steps, guidance_scale, seed. Se você treinou no RunComfy, abra Treinador → Ativos LoRA → Config e copie as configurações de visualização no nó.

Etapa 3: Execute a Inferência Z-Image De-Turbo LoRA#
- Clique em Queue/Run → SaveImage grava os resultados automaticamente na pasta de saída do ComfyUI
Solucionando Problemas de Inferência Z-Image De-Turbo LoRA#
A maioria dos problemas que as pessoas enfrentam após treinar um Z-Image De‑Turbo LoRA no AI Toolkit vem de desajustes de pipeline—o amostrador de visualização do AI Toolkit não é o mesmo que um gráfico de amostrador genérico do ComfyUI.
O nó personalizado RC Z-Image De‑Turbo (RCZimageDeturbo) da RunComfy é construído para manter a inferência alinhada ao pipeline com a amostragem de visualização no estilo AI Toolkit (wrapper específico do modelo + injeção de LoRA consistente). Ao solucionar problemas, teste seu LoRA através do RCZimageDeturbo primeiro, depois ajuste os parâmetros.
(1)Por que a visualização de amostra no aitoolkit parece ótima, mas as mesmas palavras do prompt parecem muito piores no ComfyUI? Como posso reproduzir isso no ComfyUI?#
Por que isso acontece
Mesmo se você copiar o mesmo prompt / etapas / orientação / semente, a saída pode desviar quando o ComfyUI está executando um pipeline diferente do pipeline de visualização do AI Toolkit (diferentes padrões, comportamento de condicionamento e caminho de injeção de LoRA).
Como corrigir (abordagem correspondente ao treinamento)
- Execute a inferência através do RCZimageDeturbo para que o modelo execute um pipeline de inferência específico para Z‑Image De‑Turbo e aplique seu LoRA via
lora_path/lora_scaledentro desse pipeline. - Espelhe os valores de amostragem de visualização que você usou durante a amostragem do AI Toolkit ao comparar:
width,height,sample_steps,guidance_scale,seed. - Mantenha o mesmo formato de prompt e tokens de gatilho com os quais você treinou.
(2)Ao usar Z-Image LoRA com ComfyUI, a mensagem "lora key not loaded" aparece.#
Por que isso acontece
Isso geralmente significa que o LoRA está sendo injetado através de um caminho que não corresponde aos módulos Z‑Image (De‑Turbo) contra os quais você treinou—mais comumente porque:
- a variante do modelo base não corresponde ao que o LoRA espera, ou
- o formato / mapeamento de chave do LoRA não corresponde ao carregador/pipeline que você está usando.
Como corrigir (opções confiáveis)
- Use a injeção de LoRA em nível de pipeline: carregue o adaptador apenas via
lora_pathno RCZimageDeturbo (evite empilhar um caminho de carregador LoRA extra em cima dele). - Prefira ativos no formato Diffusers para inferência em pipeline: se você estiver misturando formatos, experimente primeiro a versão Diffusers para uso em treinamento/pipeline.
- Se os formatos não corresponderem, converta os pesos do LoRA: use uma rota de conversão conhecida para pesos LoRA de Z‑Image para que eles correspondam ao formato esperado pela sua pilha de inferência (Diffusers/pipeline vs carregador nativo do Comfy).
(3)Não é possível carregar a configuração para ‘"XXXXX"#
Por que isso acontece
Isso é comumente causado por downloads de modelo incompletos (você frequentemente verá blobs .incomplete no cache do Hugging Face) ou um sistema de arquivos/runtime que impede o cache adequado, o que faz com que o transformer/config falhe ao carregar.
Como corrigir (download verificado pelo usuário + construção de pasta) Uma abordagem funcional relatada por usuários é baixar um Turbo base limpo + o transformador De‑Turbo, depois montar uma pasta completa localmente:
- Baixe ambos os repositórios com
huggingface-cli download ... --local-dir-use-symlinks False - Substitua
Z-Image-Turbo/transformerpela pastaZ-Image-De-Turbo/transformer - Aponte seu caminho de modelo (ou o ambiente que carrega a base) para o diretório completo resultante
Após a base carregar corretamente, execute a inferência através do RCZimageDeturbo e corresponda os valores de amostragem de visualização para comparar com as visualizações do AI Toolkit.
Execute a Inferência Z-Image De-Turbo LoRA agora#
Abra o fluxo de trabalho Z-Image De-Turbo LoRA Inference da RunComfy, defina lora_path, e execute RCZimageDeturbo para manter os resultados do ComfyUI alinhados com suas visualizações de treinamento do AI Toolkit.