
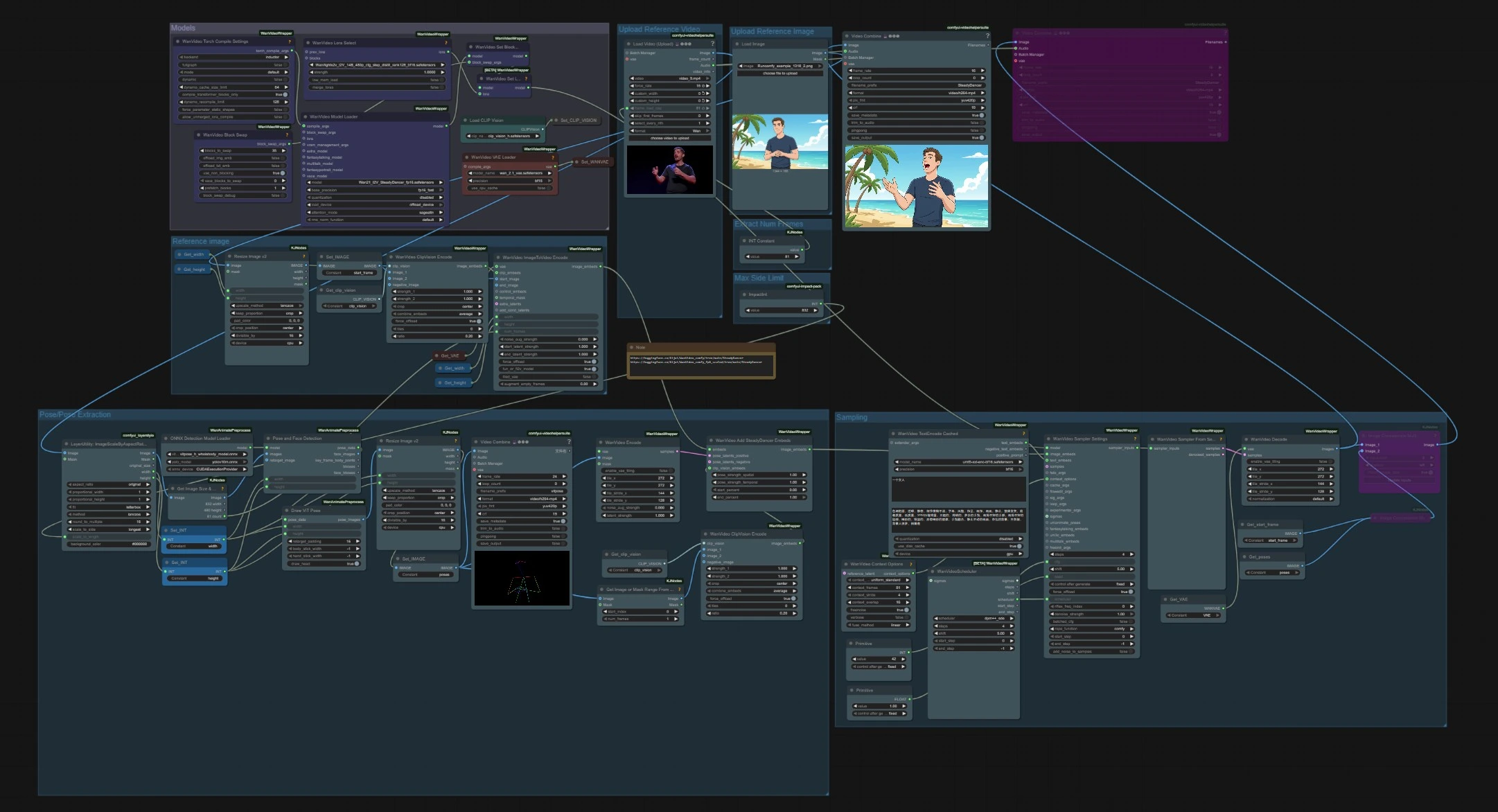
Fluxo de trabalho de animação de pose de imagem para vídeo SteadyDancer#
Este fluxo de trabalho ComfyUI transforma uma única imagem de referência em um vídeo coerente, impulsionado pelo movimento de uma fonte de pose separada. É construído em torno do paradigma de imagem-para-vídeo do SteadyDancer, de modo que o primeiro quadro preserva a identidade e aparência da sua imagem de entrada enquanto o restante da sequência segue o movimento alvo. O gráfico reconcilia pose e aparência através de incorporações específicas do SteadyDancer e um pipeline de pose, produzindo movimento corporal completo suave e realista com forte coerência temporal.
SteadyDancer é ideal para animação humana, geração de dança e dar vida a personagens ou retratos. Forneça uma imagem estática mais um clipe de movimento, e o pipeline ComfyUI lida com extração de pose, incorporação, amostragem e decodificação para entregar um vídeo pronto para compartilhar.
Modelos principais no fluxo de trabalho SteadyDancer do ComfyUI#
- SteadyDancer. Modelo de pesquisa para preservação de identidade de imagem-para-vídeo com um Mecanismo de Reconciliação de Condição e Modulação Sinergística de Pose. Usado aqui como o método I2V principal. GitHub
- Pesos Wan 2.1 I2V SteadyDancer. Checkpoints portados para ComfyUI que implementam SteadyDancer na pilha Wan 2.1. Hugging Face: Kijai/WanVideo_comfy (SteadyDancer) e Kijai/WanVideo_comfy_fp8_scaled (SteadyDancer)
- Wan 2.1 VAE. VAE de vídeo usado para codificação e decodificação latente dentro do pipeline. Incluído com o port WanVideo no Hugging Face acima.
- OpenCLIP CLIP ViT‑H/14. Codificador de visão que extrai incorporações robustas de aparência da imagem de referência. Hugging Face
- ViTPose‑H WholeBody (ONNX). Modelo de ponto chave de alta qualidade para corpo, mãos e rosto usado para derivar a sequência de pose motriz. GitHub
- YOLOv10 (ONNX). Detector que melhora a localização de pessoas antes da estimativa de pose em vídeos diversos. GitHub
- Codificador umT5‑XXL. Codificador de texto opcional para orientação de estilo ou cena juntamente com a imagem de referência. Hugging Face
Como usar o fluxo de trabalho SteadyDancer do ComfyUI#
O fluxo de trabalho tem duas entradas independentes que se encontram na amostragem: uma imagem de referência para identidade e um vídeo motriz para movimento. Os modelos são carregados uma vez no início, a pose é extraída do clipe motriz, e as incorporações SteadyDancer misturam pose e aparência antes da geração e decodificação.
Modelos#
Este grupo carrega os pesos principais usados ao longo do gráfico. WanVideoModelLoader (#22) seleciona o checkpoint Wan 2.1 I2V SteadyDancer e lida com configurações de atenção e precisão. WanVideoVAELoader (#38) fornece o VAE de vídeo, e CLIPVisionLoader (#59) prepara a base de visão CLIP ViT‑H. Um nó de seleção LoRA e opções BlockSwap estão presentes para usuários avançados que desejam alterar o comportamento de memória ou anexar pesos adicionais.
Carregar Vídeo de Referência#
Importe a fonte de movimento usando VHS_LoadVideo (#75). O nó lê quadros e áudio, permitindo que você defina uma taxa de quadros alvo ou limite o número de quadros. O clipe pode ser qualquer movimento humano, como uma dança ou movimento esportivo. O fluxo de vídeo então passa para a escala de proporção de aspecto e extração de pose.
Extrair Número de Quadros#
Uma constante simples controla quantos quadros são carregados do vídeo motriz. Isso limita tanto a extração de pose quanto o comprimento da saída SteadyDancer gerada. Aumente para sequências mais longas ou reduza para iterar mais rapidamente.
Limite Máximo de Lado#
LayerUtility: ImageScaleByAspectRatio V2 (#146) escala quadros enquanto preserva a proporção de aspecto para que se ajustem à margem de manobra e orçamento de memória do modelo. Defina um limite de lado longo apropriado para sua GPU e o nível de detalhe desejado. Os quadros escalados são usados pelos nós de detecção a jusante e como referência para o tamanho de saída.
Pose/Extração de Pose#
Detecção de pessoas e estimativa de pose são executadas nos quadros escalados. PoseAndFaceDetection (#89) usa YOLOv10 e ViTPose‑H para encontrar pessoas e pontos-chave de forma robusta. DrawViTPose (#88) renderiza uma representação limpa de figura de palito do movimento, e ImageResizeKJv2 (#77) dimensiona as imagens de pose resultantes para corresponder à tela de geração. WanVideoEncode (#72) converte as imagens de pose em latentes para que o SteadyDancer possa modular o movimento sem lutar contra o sinal de aparência.
Carregar Imagem de Referência#
Carregue a imagem de identidade que você deseja que o SteadyDancer anime. A imagem deve mostrar claramente o sujeito que você pretende mover. Use uma pose e ângulo de câmera que correspondam amplamente ao vídeo motriz para a transferência mais fiel. O quadro é encaminhado para o grupo de imagem de referência para incorporação.
Imagem de Referência#
A imagem estática é redimensionada com ImageResizeKJv2 (#68) e registrada como o quadro inicial via Set_IMAGE (#96). WanVideoClipVisionEncode (#65) extrai incorporações CLIP ViT‑H que preservam identidade, roupas e layout grosseiro. WanVideoImageToVideoEncode (#63) embala largura, altura e contagem de quadros com o quadro inicial para preparar o condicionamento I2V do SteadyDancer.
Amostragem#
É aqui que aparência e movimento se encontram para gerar vídeo. WanVideoAddSteadyDancerEmbeds (#71) recebe o condicionamento de imagem de WanVideoImageToVideoEncode e o aumenta com latentes de pose mais uma referência CLIP‑vision, permitindo a reconciliação de condição do SteadyDancer. Janelas de contexto e sobreposição são definidas em WanVideoContextOptions (#87) para consistência temporal. Opcionalmente, WanVideoTextEncodeCached (#92) adiciona orientação de texto umT5 para ajustes de estilo. WanVideoSamplerSettings (#119) e WanVideoSamplerFromSettings (#129) executam as etapas reais de remoção de ruído no modelo Wan 2.1, após o que WanVideoDecode (#28) converte latentes de volta para quadros RGB. Os vídeos finais são salvos com VHS_VideoCombine (#141, #83).
Nós principais no fluxo de trabalho SteadyDancer do ComfyUI#
WanVideoAddSteadyDancerEmbeds (#71)#
Este nó é o coração do SteadyDancer no gráfico. Ele funde o condicionamento de imagem com latentes de pose e dicas CLIP‑vision para que o primeiro quadro trave a identidade enquanto o movimento se desenrola naturalmente. Ajuste pose_strength_spatial para controlar quão rigidamente os membros seguem o esqueleto detectado e pose_strength_temporal para regular a suavidade do movimento ao longo do tempo. Use start_percent e end_percent para limitar onde o controle de pose se aplica dentro da sequência para introduções e conclusões mais naturais.
PoseAndFaceDetection (#89)#
Executa detecção YOLOv10 e estimativa de ponto-chave ViTPose‑H no vídeo motriz. Se as poses perderem pequenos membros ou rostos, aumente a resolução de entrada a montante ou escolha filmagens com menos oclusões e iluminação mais limpa. Quando várias pessoas estão presentes, mantenha o sujeito alvo maior em quadro para que o detector e a cabeça de pose permaneçam estáveis.
VHS_LoadVideo (#75)#
Controla qual porção da fonte de movimento você usa. Aumente o limite de quadros para saídas mais longas ou diminua para prototipar rapidamente. A entrada force_rate alinha o espaçamento de pose com a taxa de geração e pode ajudar a reduzir tremores quando o FPS do clipe original é incomum.
LayerUtility: ImageScaleByAspectRatio V2 (#146)#
Mantém os quadros dentro de um limite de lado longo escolhido enquanto mantém a proporção de aspecto e encaixando em um tamanho divisível. Combine a escala aqui com a tela de geração para que o SteadyDancer não precise ampliar ou cortar de forma agressiva. Se você perceber resultados suaves ou artefatos de borda, aproxime o lado longo da escala de treinamento nativa do modelo para uma decodificação mais limpa.
WanVideoSamplerSettings (#119)#
Define o plano de remoção de ruído para o sampler Wan 2.1. O scheduler e steps definem a qualidade geral versus velocidade, enquanto cfg equilibra a adesão à imagem mais o prompt contra a diversidade. seed trava a reprodutibilidade, e denoise_strength pode ser reduzido quando você quiser se aproximar ainda mais da aparência da imagem de referência.
WanVideoModelLoader (#22)#
Carrega o checkpoint Wan 2.1 I2V SteadyDancer e lida com a implementação de precisão, atenção e colocação de dispositivo. Deixe-os como configurados para estabilidade. Usuários avançados podem anexar um I2V LoRA para alterar o comportamento de movimento ou reduzir o custo computacional ao experimentar.
Extras opcionais#
- Escolha uma imagem de referência clara e bem iluminada. Vistas frontais ou ligeiramente anguladas que se assemelham à câmera do vídeo motriz fazem o SteadyDancer preservar a identidade de forma mais confiável.
- Prefira clipes de movimento com um único sujeito proeminente e mínima oclusão. Planos de fundo ocupados ou cortes rápidos reduzem a estabilidade de pose.
- Se mãos e pés tremerem, aumente ligeiramente a força temporal da pose em
WanVideoAddSteadyDancerEmbedsou aumente o FPS do vídeo para densificar poses. - Para cenas mais longas, processe em segmentos com contexto sobreposto e costure as saídas. Isso mantém o uso de memória razoável e mantém a continuidade temporal.
- Use os mosaicos de pré-visualização integrados para comparar os quadros gerados com o quadro inicial e a sequência de poses enquanto você ajusta as configurações.
Este fluxo de trabalho SteadyDancer oferece um caminho prático e completo de uma única imagem estática para um vídeo fiel, orientado por pose, com identidade preservada desde o primeiro quadro.
Agradecimentos#
Este fluxo de trabalho implementa e expande os seguintes trabalhos e recursos. Agradecemos imensamente ao MCG-NJU pelo SteadyDancer por suas contribuições e manutenção. Para detalhes autoritativos, consulte a documentação e repositórios originais vinculados abaixo.
Recursos#
- MCG-NJU/SteadyDancer
- GitHub: MCG-NJU/SteadyDancer
- Hugging Face: MCG-NJU/SteadyDancer-14B
- arXiv: arXiv:2511.19320
Nota: O uso dos modelos, conjuntos de dados e código referenciados está sujeito às respectivas licenças e termos fornecidos por seus autores e mantenedores.

