
Workflow de vídeo falante de personagem único e duplo DreamID-Omni para ComfyUI#
Este workflow transforma uma única foto de referência e um clipe de áudio em um vídeo falante que preserva a identidade. Alimentado pelo modelo DreamID-Omni, ele combina uma moderna estrutura de vídeo com movimento labial orientado por MMAudio para que o sujeito fale naturalmente enquanto mantém o rosto da sua imagem. Ele também suporta dois personagens, permitindo clipes de conversa lado a lado conduzidos por duas vozes.
Projetado para criadores, equipes de produto e pesquisadores, o workflow DreamID-Omni no ComfyUI é ideal para avatares digitais, anúncios personalizados, introduções de tutoriais e cenas de diálogo em IA. Você fornece fotos e áudio, descreve opcionalmente a cena em um prompt curto, e o gráfico renderiza um vídeo polido pronto para compartilhar.
Modelos principais no workflow DreamID-Omni do ComfyUI#
- DreamID-Omni. O módulo central de identidade que preserva a pessoa na sua imagem de referência através dos quadros enquanto responde ao áudio para movimentos labiais realistas. Veja o repositório oficial e os pesos para detalhes: DreamID-Omni e DreamID-Omni no Hugging Face.
- Wan 2.2 geração de vídeo. Uma estrutura de difusão de vídeo de alta capacidade que sintetiza movimento coerente, iluminação e composição de cena enquanto o DreamID-Omni orienta a identidade facial.
- MMAudio. Um modelo de representação de áudio que condiciona as formas da boca e sutis sinais faciais para alinhar com o discurso fornecido, melhorando o realismo da sincronização labial.
Como usar o workflow DreamID-Omni do ComfyUI#
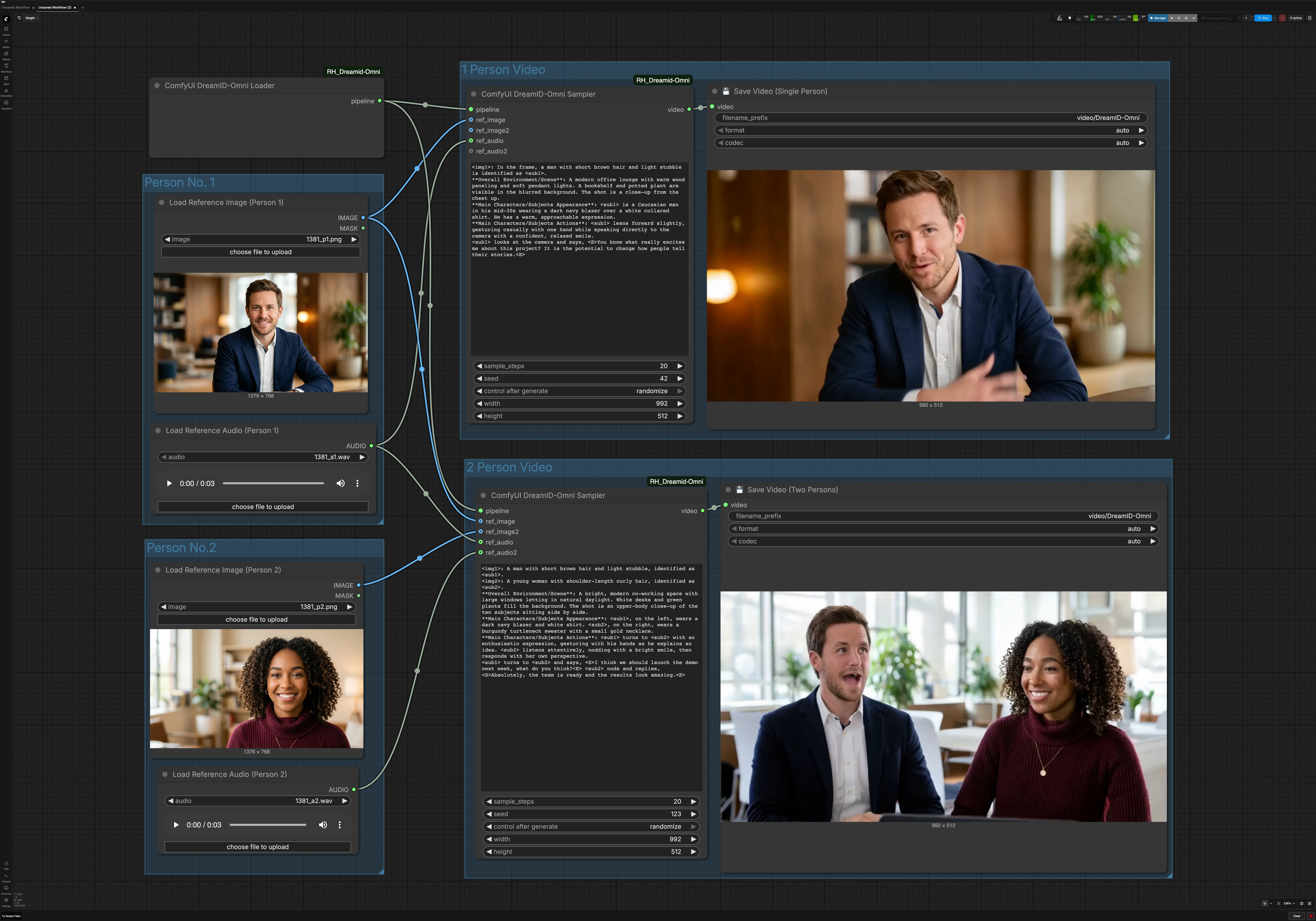
Este gráfico tem dois caminhos paralelos. O caminho de uma pessoa usa uma imagem e um áudio. O caminho de duas pessoas usa duas imagens e dois áudios para produzir um clipe de conversa. Um carregador compartilhado DreamID-Omni inicializa o pipeline para ambos.
Pessoa Nº 1#
Use Load Reference Image (Person 1) (#6) para selecionar um retrato claro e de frente com iluminação uniforme e mínima oclusão. Use Load Reference Audio (Person 1) (#7) para fornecer o discurso que você deseja que o personagem diga. Áudio mais limpo produz melhor sincronização labial, então prefira discursos sem música ou ruídos de fundo fortes. Este par alimenta tanto o modo de uma pessoa quanto, quando habilitado, o sujeito esquerdo ou primeiro no modo de duas pessoas.
Pessoa Nº 2#
Use Load Reference Image (Person 2) (#9) e Load Reference Audio (Person 2) (#11) ao criar um diálogo. Escolha uma foto que corresponda ao enquadramento da Pessoa 1 para manter a composição equilibrada. Certifique-se de que o segundo áudio seja semelhante em volume ao primeiro para evitar mudanças perceptuais abruptas. Se você estiver fazendo apenas um clipe de uma pessoa, pode ignorar este grupo.
Vídeo de 1 Pessoa#
O caminho do orador único é conduzido por ComfyUI DreamID-Omni Sampler (#21). Ele funde o pipeline DreamID-Omni com a foto e o áudio da Pessoa 1, então renderiza uma cena consistente com a descrição breve da cena no campo de prompt do nó. Mantenha seu prompt conciso e prático, por exemplo, descrevendo o fundo, distância da câmera e comportamento. O resultado é escrito por 💾 Save Video (Single Person) (#4), que nomeia e exporta o arquivo para você.
Vídeo de 2 Pessoas#
O caminho do diálogo usa ComfyUI DreamID-Omni Sampler (#22) para compor duas identidades em um quadro e conduzir cada boca com seu áudio emparelhado. Forneça um breve prompt para definir o ambiente e o estilo de interação, como um espaço de co-working, tom casual ou quem fala primeiro. Isso ajuda a estabilizar o posicionamento da câmera e os gestos enquanto DreamID-Omni e MMAudio mantêm identidade e alinhamento labial. O clipe é exportado por 💾 Save Video (Two Persons) (#5).
Pipeline compartilhado DreamID-Omni#
ComfyUI DreamID-Omni Loader (#23) inicializa os componentes DreamID-Omni usados por ambos os caminhos. Normalmente, você não precisa ajustar nada aqui. Desde que os pesos e o nó ComfyUI estejam disponíveis, o carregador prepara o pipeline para que os amostradores possam renderizar.
Nós principais no workflow DreamID-Omni do ComfyUI#
ComfyUI DreamID-Omni Loader (#23)#
Inicializa o pipeline DreamID-Omni e disponibiliza seus pesos para amostradores a jusante. Não há entradas típicas do usuário aqui. Se você mantiver várias variantes do modelo, confirme que os pesos corretos estão instalados antes de enfileirar renderizações.
ComfyUI DreamID-Omni Sampler (#21)#
Renderização de uma pessoa. Este nó combina o pipeline do carregador com a primeira imagem e áudio de referência para sintetizar uma cabeça falante que preserva a identidade. O campo de prompt é onde você define a cena e o comportamento; a semente controla a repetibilidade; a resolução determina o enquadramento e o detalhe facial; e os passos trocam velocidade por fidelidade. Para resultados consistentes em várias tomadas, reutilize a mesma semente e mantenha as mudanças de prompt mínimas.
ComfyUI DreamID-Omni Sampler (#22)#
Renderização de duas pessoas. Esta instância aceita duas fotos e dois áudios, emparelhando cada voz com seu sujeito para movimento labial sincronizado. O prompt pode encenar a conversa e o layout da câmera. Ajuste a semente e a resolução como faria no modo de uma pessoa, e certifique-se de que ambos os áudios estejam ajustados ao tempo desejado antes de renderizar.
💾 Save Video (Single Person) (#4)#
Grava a saída de um orador no disco. Defina a pasta ou nome base para manter as versões organizadas. Se disponível, deixe as opções de codec e taxa de quadros no automático quando não tiver certeza.
💾 Save Video (Two Persons) (#5)#
Grava a saída do diálogo no disco. Use um nome base distinto para que clipes de uma e duas pessoas sejam fáceis de distinguir. Mantenha as configurações de exportação automáticas para confiabilidade, a menos que você tenha um requisito específico de entrega.
Extras opcionais#
- Mantenha os rostos grandes o suficiente nas imagens de referência para ocupar uma parte significativa do quadro para um bloqueio de identidade mais forte.
- Use áudio de fala limpo e bem nivelado. Corte silêncios no início para evitar lábios congelados inicialmente.
- Para um visual mais estável, reutilize a mesma semente ao iterar sobre prompts ou roupas.
- Se o espaçamento de duas pessoas parecer apertado, reformule o prompt para alargar a câmera ou aumentar o espaço para os ombros em vez de cortar rostos.
- Para ativos e atualizações, veja o modelo e nó oficial: DreamID-Omni, ComfyUI_RH_Dreamid-Omni, e DreamID-Omni weights.
Agradecimentos#
Este workflow implementa e se baseia nos seguintes trabalhos e recursos. Agradecemos a Guoxu1233 pelo modelo/workflow DreamID-Omni, HM-RunningHub pelo nó DreamID-Omni ComfyUI, e XuGuo699 pelos pesos do modelo DreamID-Omni por suas contribuições e manutenção. Para detalhes autoritativos, consulte a documentação e os repositórios originais vinculados abaixo.
Recursos#
- Repositório Oficial DreamID-Omni - https://github.com/Guoxu1233/DreamID-Omni
- GitHub: Guoxu1233/DreamID-Omni
- Nó ComfyUI DreamID-Omni (RunningHub) - https://github.com/HM-RunningHub/ComfyUI_RH_Dreamid-Omni
- Pesos do Modelo DreamID-Omni (Hugging Face) - https://huggingface.co/XuGuo699/DreamID-Omni
- Hugging Face: XuGuo699/DreamID-Omni
Nota: O uso dos modelos, conjuntos de dados e código referenciados está sujeito às respectivas licenças e termos fornecidos por seus autores e mantenedores.