
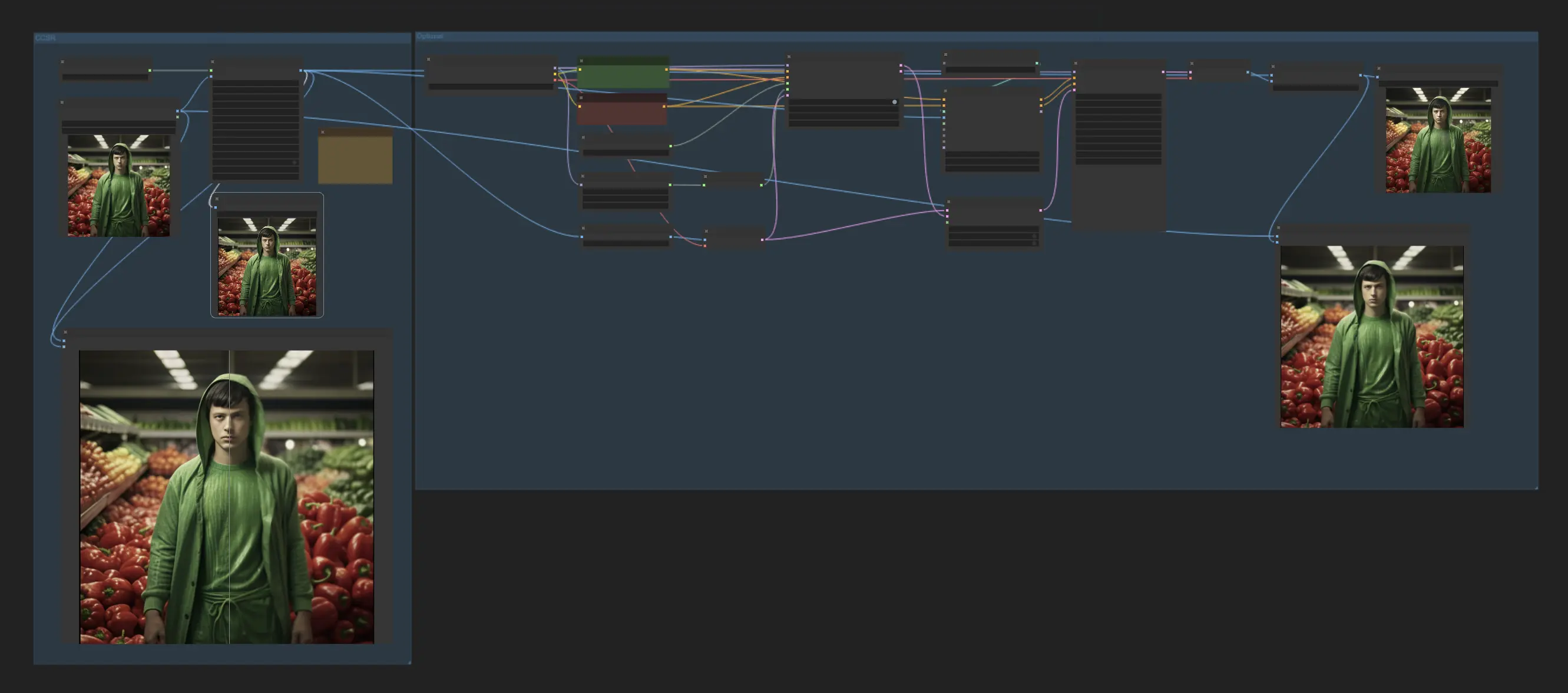
1. ComfyUI CCSR | ComfyUI Upscale Workflow#
This ComfyUI workflow incorporates the CCSR (Content Consistent Super-Resolution) model, designed to enhance content consistency in super-resolution tasks. Following the application of the CCSR model, there's an optional step that involves upscaling once more by adding noise and utilizing the ControlNet recolor model. This is an experimental feature for users to explore.
By default, this workflow is set up for image upscaling. To upscale videos, simply replace “load image” with “load video” and change “save image” to “combine video.”
2. Introduction to CCSR#
Pre-trained latent diffusion models have been recognized for their potential in improving the perceptual quality of image super-resolution (SR) outcomes. However, these models often produce variable results for identical low-resolution images under different noise conditions. This variability, though advantageous for text-to-image generation, poses challenges for SR tasks, which demand consistency in content preservation.
To enhance the reliability of diffusion prior-based SR, CCSR (Content Consistent Super-Resolution) uses a strategy that combines diffusion models for refining image structures with generative adversarial networks (GANs) for improving fine details. It introduces a non-uniform timestep learning strategy to train a compact diffusion network. This network efficiently and stably reconstructs the main structures of an image, while the pre-trained decoder of a variational auto-encoder (VAE) is fine-tuned through adversarial training for detail enhancement. This approach helps CCSR to notably reduce the stochasticity associated with diffusion prior-based SR methods, thereby enhancing content consistency in SR outputs and accelerating the image generation process.
3. How to Use ComfyUI CCSR for image Upscaling#
3.1. CCSR Models#
real-world_ccsr.ckpt: CCSR model for real-world image restoration.
bicubic_ccsr.ckpt: CCSR model for bicubic image restoration.
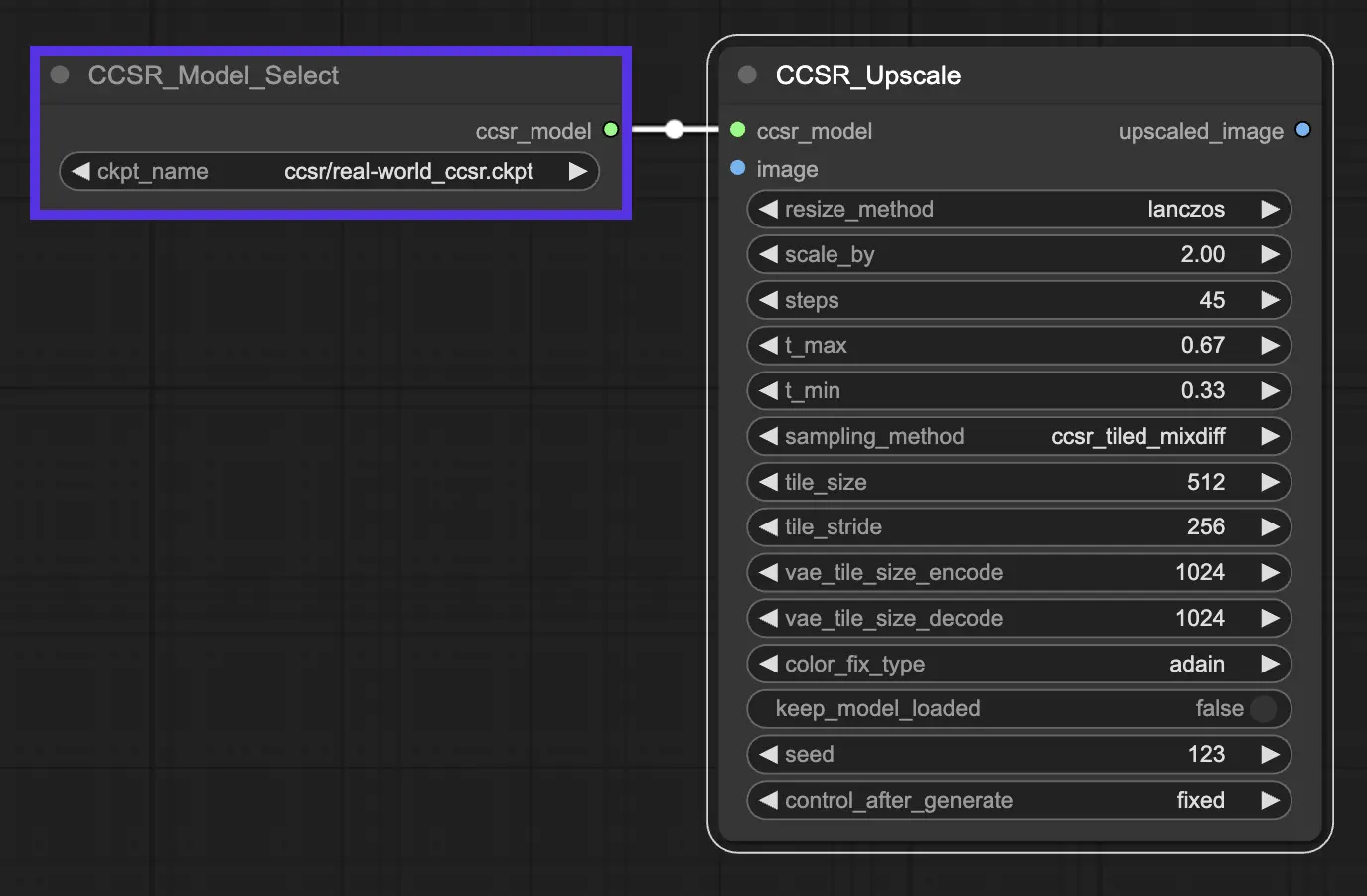
3.2. Key Parameters in CCSR#
-scale_by: This parameter specifies the super-resolution scale, determining how much the input images or videos are enlarged.
-steps: Refers to the number of steps in the diffusion process. It controls how many iterations the model goes through to refine the image details and structures.
-t_max and -t_min: These parameters set the maximum and minimum thresholds for the non-uniform timestep learning strategy used in the CCSR model.
-sampling_method:
CCSR (Normal, Untiled):This approach utilizes a normal, untiled sampling method. It's straightforward and does not divide the image into tiles for processing. While this can be effective for ensuring content consistency across the entire image, it's also heavy on VRAM usage. This method is best suited for scenarios where VRAM is plentiful, and the highest possible consistency across the image is required.CCSR_Tiled_MixDiff:This tiled approach processes each tile of the image separately, which helps manage VRAM usage more efficiently by not requiring the entire image to be in memory at once. However, a notable drawback is the potential for visible seams where tiles meet, as each tile is processed independently, leading to possible inconsistencies at the tile borders.CCSR_Tiled_VAE_Gaussian_Weights: This method aims to fix the seam issue seen in the CCSR_Tiled_MixDiff approach by using Gaussian weights to blend the tiles more smoothly. This can significantly reduce the visibility of seams, providing a more consistent appearance across tile borders. However, this blending can sometimes be less accurate and might introduce extra noise into the super-resolved image, affecting the overall image quality.
-tile_size, and -tile_stride: These parameters are part of the tiled diffusion feature, which is integrated into CCSR to save GPU memory during inference. Tiling refers to processing the image in patches rather than whole, which can be more memory-efficient. -tile_size specifies the size of each tile, and -tile_diffusion_stride controls the stride or overlap between tiles.
-color_fix_type: This parameter indicate the method used for color correction or adjustment in the super-resolution process. adain is one of the methods employed for color correction to ensure that the colors in the super-resolved image match the original image as closely as possible.
4. More Details about CCSR#
Image super-resolution, aimed at recovering high-resolution (HR) images from low-resolution (LR) counterparts, addresses the challenge posed by quality degradation during image capture. While existing deep learning-based SR techniques have primarily focused on neural network architecture optimization against simple, known degradations, they fall short in handling the complex degradations encountered in real-world scenarios. Recent advancements have included the development of datasets and methods simulating more complex image degradations to approximate these real-world challenges.
The study also highlights the limitations of traditional loss functions, such as ℓ1 and MSE, which tend to produce overly smooth details in SR outputs. Although SSIM loss and perceptual loss mitigate this issue to some extent, achieving realistic image detail remains challenging. GANs have emerged as a successful approach for enhancing image details, but their application to natural images often results in visual artifacts due to the diverse nature of natural scenes.
Denoising Diffusion Probabilistic Models (DDPMs) and their variants have shown significant promise, outperforming GANs in generating diverse and high-quality priors for image restoration, including SR. These models, however, have struggled to adapt to the complex and varied degradations present in real-world applications.
The CCSR approach seeks to address these challenges by ensuring stable and consistent super-resolution outcomes. It leverages diffusion priors for generating coherent structures and employs generative adversarial training for detail and texture enhancement. By adopting a non-uniform timestep sampling strategy and fine-tuning a pre-trained VAE decoder, CCSR achieves stable, content-consistent SR results more efficiently than existing diffusion prior-based SR methods.


