
⚠️ 중요 안내: 이 ComfyUI MultiTalk 구현은 현재 단일 인물 생성만 지원합니다. 다중 인물 대화 기능은 곧 제공될 예정입니다.
1. MultiTalk이란?#
MultiTalk은 MeiGen-AI가 개발한 오디오 기반 다중 인물 대화 영상 생성을 위한 혁신적인 프레임워크입니다. 얼굴 움직임만 애니메이션하는 기존의 토킹 헤드 생성 방법과 달리, MultiTalk 기술은 오디오 입력과 완벽한 립싱크를 유지하면서 사람들이 말하고, 노래하고, 상호작용하는 사실적인 영상을 생성할 수 있습니다. MultiTalk은 정적 사진을 역동적인 말하는 영상으로 변환하여 원하는 대로 말하거나 노래하게 만듭니다.
2. MultiTalk 작동 원리#
MultiTalk은 오디오 신호와 시각 정보를 모두 이해하는 고급 AI 기술을 활용합니다. ComfyUI MultiTalk 구현은 최적의 결과를 위해 MultiTalk + Wan2.1 + Uni3C를 결합합니다:
오디오 분석: MultiTalk은 강력한 오디오 인코더(Wav2Vec)를 사용하여 리듬, 톤, 발음 패턴을 포함한 음성의 미묘한 차이를 이해합니다.
시각적 이해: 강력한 Wan2.1 비디오 확산 모델을 기반으로 구축된 MultiTalk은 인체 해부학, 얼굴 표정 및 신체 움직임을 이해합니다(t2v/i2v 생성을 위한 Wan2.1 워크플로우를 방문하세요).
카메라 제어: Uni3C controlnet을 갖춘 MultiTalk은 미세한 카메라 움직임과 장면 제어를 가능하게 하여 영상을 더 역동적이고 전문적으로 만듭니다. 아름다운 카메라 모션 전송을 위한 Uni3C 워크플로우를 확인하세요.
완벽한 동기화: 정교한 어텐션 메커니즘을 통해 MultiTalk은 자연스러운 표정과 바디 랭귀지를 유지하면서 입 움직임을 오디오와 완벽하게 정렬합니다.
지시 따르기: 더 단순한 방법과 달리 MultiTalk은 오디오 동기화를 유지하면서 텍스트 프롬프트를 따라 장면, 포즈, 전체적인 동작을 제어할 수 있습니다.
3. ComfyUI MultiTalk의 장점#
- 고품질 립싱크: MultiTalk은 밀리초 수준의 립싱크 정밀도를 달성하며, 특히 노래 시나리오에서 인상적입니다
- 다양한 콘텐츠 제작: MultiTalk은 만화 캐릭터를 포함한 다양한 캐릭터 유형으로 대화와 노래 생성을 모두 지원합니다
- 유연한 해상도: MultiTalk은 임의의 종횡비로 480P 또는 720P 영상을 생성합니다
- 긴 영상 지원: MultiTalk은 최대 15초 길이의 영상을 생성합니다
- 지시 따르기: MultiTalk은 텍스트 프롬프트를 통해 캐릭터 동작과 장면 설정을 제어합니다
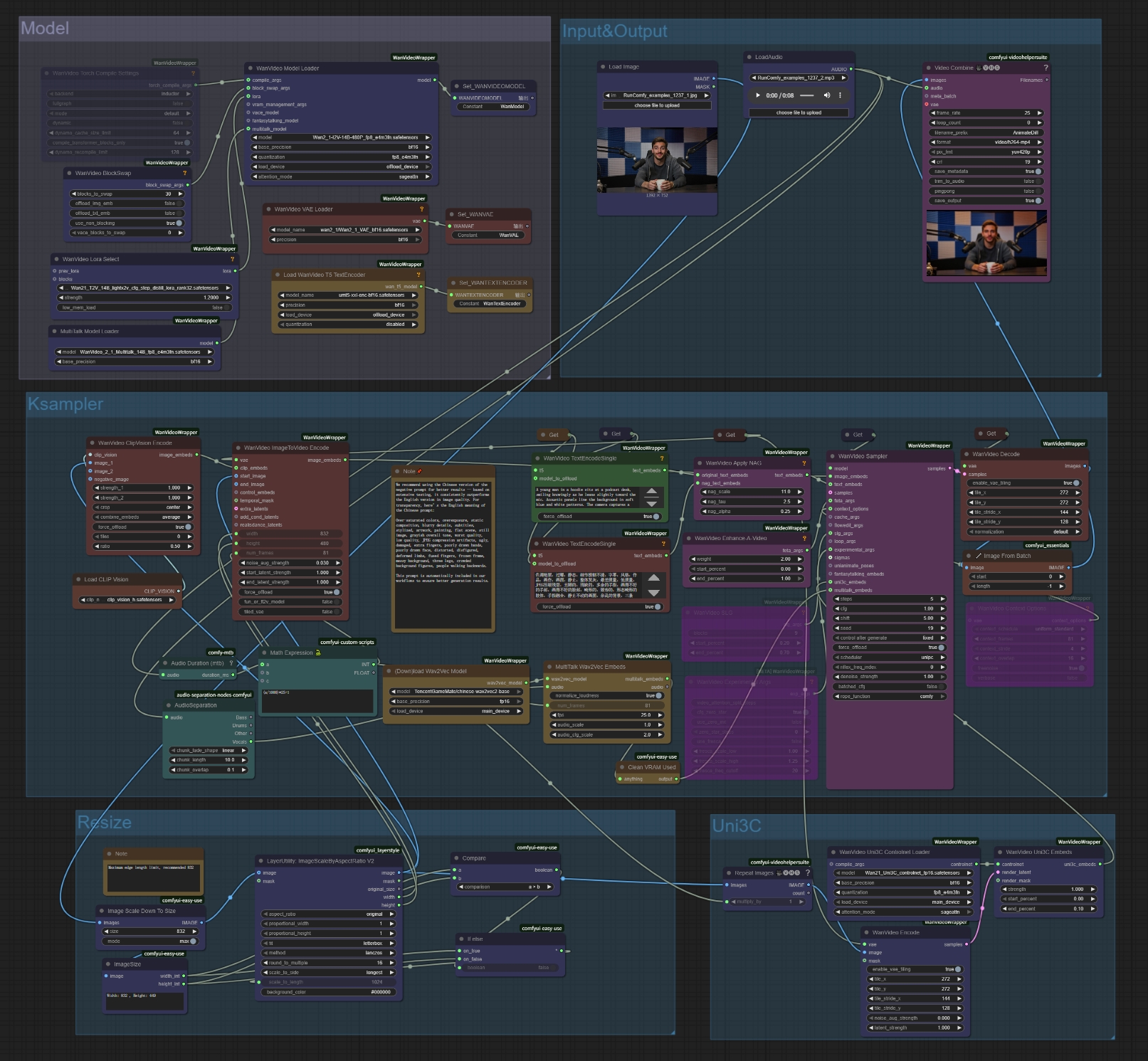
4. ComfyUI MultiTalk 워크플로우 사용 방법#
MultiTalk 단계별 사용 가이드#
단계 1: MultiTalk 입력 준비
- 참조 이미지 업로드: Load Image 노드에서 "choose file to upload" 클릭
- 최상의 MultiTalk 결과를 위해 선명한 정면 사진 사용
- 이미지는 자동으로 최적 크기로 조정됩니다 (832px 권장)
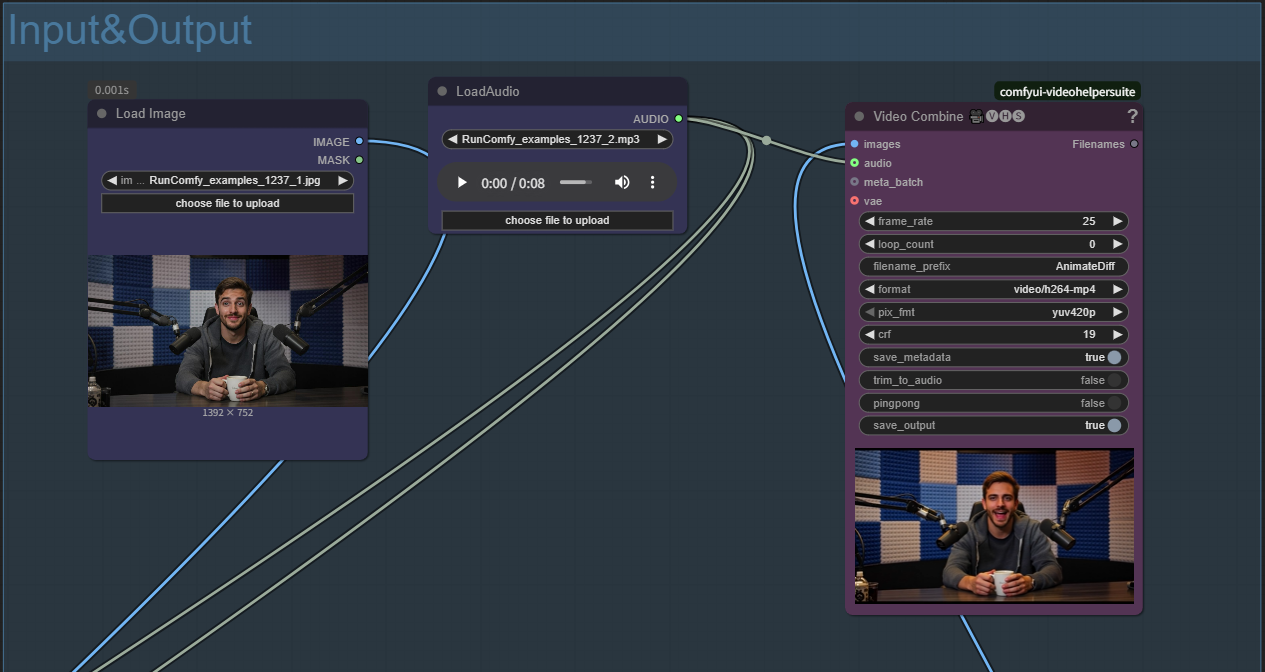
- 오디오 파일 업로드: LoadAudio 노드에서 "choose file to upload" 클릭
- MultiTalk은 다양한 오디오 형식(WAV, MP3 등)을 지원합니다
- 선명한 음성/노래가 MultiTalk에서 가장 좋은 결과를 냅니다
- 커스텀 노래 제작에는 동기화된 가사와 함께 고품질 음악을 생성하는 Ace-Step 음악 생성 워크플로우 사용을 고려하세요.
- 텍스트 프롬프트 작성: MultiTalk 생성을 위한 텍스트 인코드 노드에 원하는 장면을 설명하세요
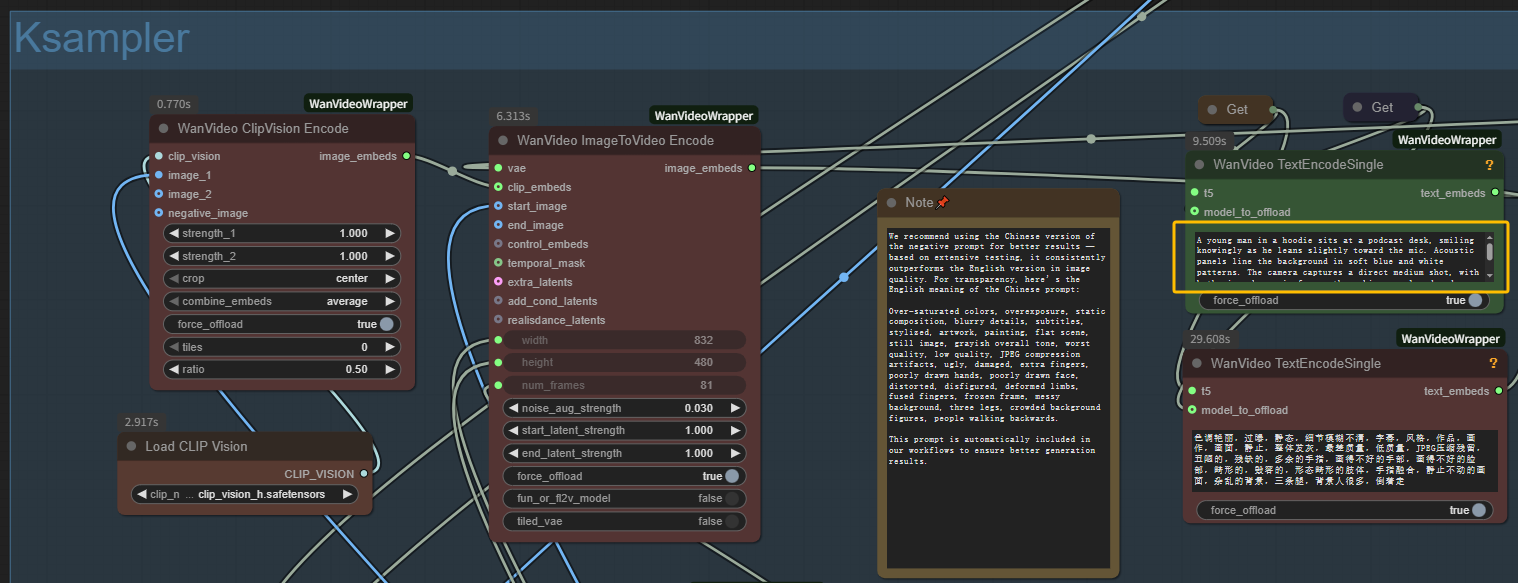
단계 2: MultiTalk 생성 설정 구성
- 샘플링 단계: 20-40 단계 (높을수록 = 더 좋은 MultiTalk 품질, 느린 생성)
- 오디오 스케일: 최적의 MultiTalk 립싱크를 위해 1.0 유지
- Embed Cond Scale: 균형 잡힌 MultiTalk 오디오 컨디셔닝을 위해 2.0
- 카메라 제어: 미세한 움직임을 위해 Uni3C 활성화, 또는 정적 MultiTalk 샷을 위해 비활성화
단계 3: 선택적 MultiTalk 향상
- LoRA 가속: 최소한의 품질 손실로 더 빠른 MultiTalk 생성을 위해 활성화
- 영상 향상: MultiTalk 후처리 개선을 위한 향상 노드 사용
- 네거티브 프롬프트: MultiTalk 출력에서 피하고 싶은 요소 추가 (흐릿함, 왜곡 등)
단계 4: MultiTalk으로 생성
- 프롬프트를 대기열에 넣고 MultiTalk 생성을 기다립니다
- VRAM 사용량 모니터링 (MultiTalk에 48GB 권장)
- MultiTalk 생성 시간: 설정과 하드웨어에 따라 7-15분
5. 감사의 말#
원본 연구: MultiTalk은 이 분야의 선도적인 연구자들과의 협력으로 MeiGen-AI가 개발했습니다. 원본 논문 "Let Them Talk: Audio-Driven Multi-Person Conversational Video Generation"은 이 기술의 획기적인 연구를 제시합니다.
ComfyUI 통합: ComfyUI 구현은 ComfyUI-WanVideoWrapper 저장소를 통해 Kijai가 제공하며, 이 고급 기술을 더 넓은 크리에이티브 커뮤니티에 접근 가능하게 합니다.
기반 기술: Wan2.1 비디오 확산 모델을 기반으로 구축되었으며 Wav2Vec의 오디오 처리 기술을 통합하여 최첨단 AI 연구의 종합을 나타냅니다.
6. 링크 및 리소스#
- 원본 연구: MeiGen-AI MultiTalk Repository
- 프로젝트 페이지: https://meigen-ai.github.io/multi-talk/
- ComfyUI 통합: ComfyUI-WanVideoWrapper
