
LTX 2.3 Sulphur 2 텍스트를 비디오로 전환하는 워크플로우 시네마틱 캐릭터 애니메이션#
이 ComfyUI 파이프라인은 자연어 프롬프트를 짧고 시네마틱하며 캐릭터 중심의 비디오로 변환하며, 선택적 오디오를 포함합니다. Lightricks LTX‑2.3 및 Sulphur 2 구성 요소를 중심으로 구축되었습니다. 저해상도에서 모션 계획을 위해 생성하고, 잠재 시퀀스를 업스케일한 후 고해상도로 정제한 다음 프레임으로 디코딩하고 동기화된 오디오 트랙을 믹싱합니다.
LTX 2.3 Sulphur 2 텍스트를 비디오로 전환하는 워크플로우는 빠른 캐릭터 애니메이션 테스트, D‑Human 스타일 모션 개념 및 정제된 텍스트‑비디오 실험에 이상적입니다. 이미지‑비디오 입력이나 프롬프트 릴레이에 의존하지 않습니다; 모든 것은 텍스트에서 시작하며, LTXV 조건부가 비디오와 오디오 잠재를 엔드 투 엔드로 안내합니다.
Comfyui LTX 2.3 Sulphur 2 텍스트를 비디오로 전환하는 워크플로우의 주요 모델#
- Lightricks LTX‑2.3. 공간적 합성과 다중 모드 AV 잠재를 사용한 핵심 텍스트‑비디오 생성기입니다. 기능 및 제한 사항에 대한 가중치 및 설명은 공식 모델 저장소를 참조하세요. Hugging Face: Lightricks/LTX-2.3
- Lightricks LTX‑2.3 FP8 체크포인트. 메모리 효율성이 높은 LTX‑2.3 변형으로 추론 속도를 높이고 제한된 GPU에서 더 긴 클립이나 더 높은 해상도를 가능하게 합니다. Hugging Face: Lightricks/LTX-2.3-fp8
- Sulphur 2 기본 모델. 이 워크플로우에서 LoRA를 통해 스타일 우선권과 캐릭터 세부 사항을 제공하여 선명한 얼굴과 시네마틱 톤을 달성합니다. Hugging Face: SulphurAI/Sulphur-2-base
- LTX‑2.3 공간 업스케일러 x2 1.1. 고해상도 정제 전 공간 세부 사항을 늘리는 잠재 공간 업스케일러입니다. Hugging Face: Lightricks/LTX-2.3 file ltx-2.3-spatial-upscaler-x2-1.1.safetensors
- LTX 텍스트 인코더 (Gemma 3 12B IT, LTX에 맞춰 패키징). LTX‑2.3 조건부에 맞춰진 텍스트 임베딩 공간을 제공합니다. Hugging Face: Comfy-Org/ltx-2
- LTX 오디오 VAE. 비디오와 함께 생성된 오디오 잠재를 디코딩하여 최종 렌더링에 동기화된 사운드트랙을 포함할 수 있습니다. Hugging Face: Lightricks/LTX-2.3
Comfyui LTX 2.3 Sulphur 2 텍스트를 비디오로 전환하는 워크플로우 사용 방법#
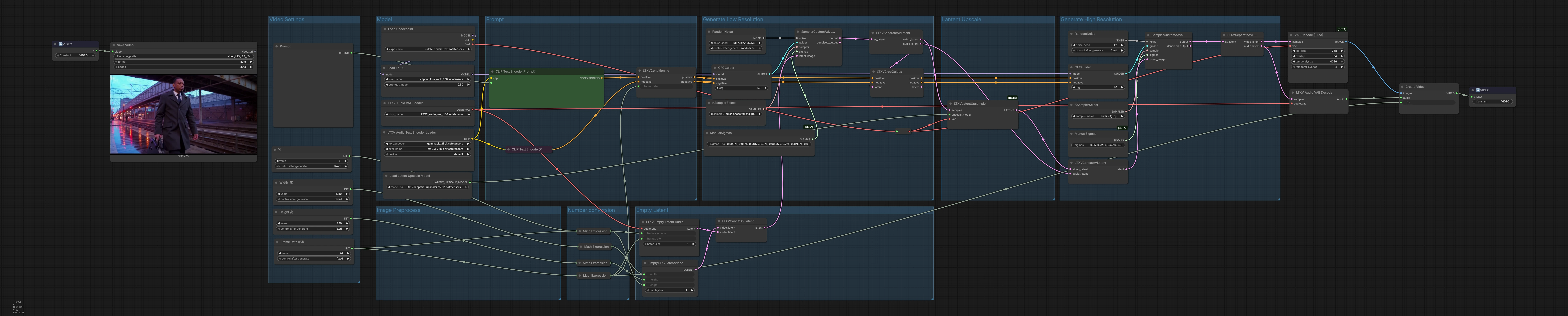
전체 논리 파이프라인은 세 단계로 작동합니다: 모션과 구성을 설정하기 위한 저해상도 생성, 공간 세부 사항을 늘리기 위한 잠재 업스케일링, 최종 오디오도 산출하는 고해상도 정제 단계입니다. 잠재는 프레임과 웨이브폼으로 디코딩된 다음 MP4 컨테이너로 믹싱되어 전달 준비가 됩니다.
비디오 설정 “비디오 설정” 그룹을 사용하여 너비, 높이, 프레임 속도 및 지속 시간을 정의합니다. 프레임 수는 지속 시간과 fps에서 자동으로 계산되어 타이밍과 리듬이 일관되게 유지됩니다. 이러한 값은 잠재 할당 및 디코딩을 구동하므로 대상 종횡비와 실행 시간을 맞추기 위해 먼저 설정합니다. 여기에서 fps를 조정하면 모션 부드러움과 오디오 정렬이 동일한 클록을 사용하도록 조건이 지정됩니다.
프롬프트 “프롬프트”에서 LTXAVTextEncoderLoader (#316)로 LTX 텍스트 인코더를 로드한 후 CLIPTextEncode (#303)에서 긍정적인 설명을 작성하고 CLIPTextEncode (#312)에서 원하지 않는 특성을 작성합니다. 노드 LTXVConditioning (#304)은 긍정적 및 부정적 조건을 병합하고 선택한 프레임 속도를 추가하여 시간적 안내가 fps와 일치하도록 합니다. 긍정적 프롬프트를 샷 브리프처럼 취급하세요: 주제, 카메라, 조명, 분위기 및 스타일 큐. 부정적 목록은 자주 보이는 아티팩트 제거에 중점을 둡니다.
모델 “모델” 그룹은 CheckpointLoaderSimple (#315)을 통해 주요 체크포인트를 로드하고 LoraLoaderModelOnly (#285)를 사용하여 Sulphur 2 LoRA를 적용하여 시네마틱 질감과 캐릭터 충실도를 주입합니다. 여기서 체크포인트나 LoRA를 교체하여 전체적인 외관과 모션 우선권을 변경할 수 있습니다. 모델 출력은 초기 및 정제 안내자 모두에 라우팅되어 스타일과 정체성이 패스 전반에 걸쳐 일관성을 유지합니다. LTX‑2.3과 Sulphur 2를 조합하면 강렬한 대비와 모션에서 잘 읽히는 세부적인 얼굴을 얻을 수 있습니다.
숫자 변환 유틸리티 표현식은 fps와 초를 다운스트림에서 사용되는 정수 프레임 수로 변환합니다. 이는 오디오와 비디오 타임라인을 수동 수학 없이 정렬된 상태로 유지합니다. 나중에 fps나 지속 시간을 수정하면 그래프가 종속 노드를 자동으로 업데이트합니다.
빈 잠재 “빈 잠재”는 생성용 정렬된 컨테이너를 만듭니다: EmptyLTXVLatentVideo (#295)는 비디오 잠재의 공간 크기와 길이를 정의하고, LTXVEmptyLatentAudio (#305)는 동일한 프레임 속도의 오디오 잠재를 할당하며, LTXVConcatAVLatent (#321)는 이를 단일 AV 잠재로 병합합니다. 빈 잠재로 시작하면 확산 패스가 기존 콘텐츠가 아닌 프롬프트와 조건을 완전히 반영하게 됩니다.
저해상도 생성 첫 샘플링 단계는 낮은 비용으로 모션과 구성을 설정합니다. CFGGuider (#313), KSamplerSelect (#291), ManualSigmas (#306)는 프롬프트가 생성과 노이즈 스케줄을 얼마나 강력하게 조정하는지를 통제합니다. SamplerCustomAdvanced (#283)는 AV 잠재를 일관된 클립으로 디노이즈합니다. 결과는 LTXVSeparateAVLatent (#307)로 분리되고, LTXVCropGuides (#284)는 공간적 주의력을 정제하여 나중에 업스케일링할 때 원하는 주제 프레이밍이 유지되도록 합니다.
잠재 업스케일 LTXVLatentUpsampler (#287)는 LTX‑2.3 x2 업스케일러를 사용하여 공간 세부 사항을 늘리면서 속도와 안정성을 위해 잠재 공간에 머무릅니다. 업스케일된 비디오 잠재를 앞으로 전달하여 고해상도 정제 전에 질감과 가독성을 향상시킵니다. 첫 번째 패스에서 좋아했던 모션을 보존하면서 더 선명한 가장자리와 풍부한 소재를 위한 여유 공간을 엽니다.
고해상도 생성 업스케일된 비디오 잠재는 LTXVConcatAVLatent (#278)에서 오디오 잠재와 다시 결합되어 최종 품질을 안내합니다. CFGGuider (#282), KSamplerSelect (#280), ManualSigmas (#281)는 프롬프트 강도, 세부 사항 및 시간적 일관성에 대한 최종 판단을 내리며, SamplerCustomAdvanced (#308)는 정제된 AV 잠재를 생성합니다. LTXVSeparateAVLatent (#309)는 비디오를 VAEDecodeTiled (#314)에 전달하여 메모리 친화적인 프레임 디코딩을 수행하고, 오디오는 LTXVAudioVAEDecode (#297)에 전달하여 웨이브폼을 복원합니다. CreateVideo (#310)는 프레임과 오디오를 대상 fps로 믹싱하고, SaveVideo (#75)는 MP4/H.264 파일로 저장합니다.
이미지 전처리 이 영역은 기본 VAE와 업스케일러 모델을 라우팅하여 타일링과 잠재 업스케일링이 VRAM 예산 내에서 작동하도록 합니다. 메모리 압박이 발생하면 FP8 LTX‑2.3 가중치를 선호하고 타일 디코딩을 활성화하여 처리량과 품질을 유지하십시오.
Comfyui LTX 2.3 Sulphur 2 텍스트를 비디오로 전환하는 워크플로우의 주요 노드#
LTXVConditioning (#304) 긍정적 및 부정적 텍스트 조건을 병합하고 작업 프레임 속도를 첨부하여 시간적 안내가 렌더와 일치하도록 합니다. 강력하고 구체적인 장면 언어는 샷 구조를 개선하며, 간결한 부정적 요소는 아티팩트를 감소시킵니다. LTX‑2.3 모델 카드에서 조건부 노트를 참조하세요. Hugging Face: Lightricks/LTX-2.3
LTXVCropGuides (#284) 구성을 부드럽게 조정하여 주요 주제가 의도한 대로 프레임에 유지되도록 합니다. 업스케일링과 정제 전에 얼굴 크기, 수평선 배치 또는 중심 주제를 보호하는 데 사용합니다. 대화 스타일 샷과 중간 클로즈업에 특히 유용합니다.
CFGGuider (#313, #282) 프롬프트가 확산 궤적에 얼마나 공격적으로 영향을 미치는지를 제어합니다. 첫 번째 안내자는 모션과 스테이징을 고정하는 데 사용하고, 두 번째 안내자는 선명함을 추가하여 설정된 샷에서 벗어나지 않도록 합니다.
ManualSigmas (#306, #281) 노이즈 스케줄을 정의합니다. 더 많은 노이즈를 전면에 배치하면 더 큰 모션 탐색을 장려하고, 부드러운 스케줄은 시간적 일관성을 강조합니다. 저해상도 및 고해상도 스케줄은 상호 보완적이어야 하며 동일하지 않아야 합니다.
LTXVLatentUpsampler (#287) 공식 LTX 업스케일러를 사용하여 x2 잠재 업스케일링을 수행하여 정제 샘플러 전에 세부 사항을 얻습니다. 다른 LTX‑2.3 업스케일러 변형으로 교체하면 약간의 선명도와 입자가 변경될 수 있습니다. Hugging Face: Lightricks/LTX-2.3
VAEDecodeTiled (#314) 긴 클립이나 큰 클립을 관리 가능한 타일로 디코딩하여 VRAM 급증을 방지합니다. 공간 크기나 클립 길이를 변경하면 메모리 여유 공간과 디코드 속도의 균형을 맞추기 위해 타일링을 조정합니다.
LoraLoaderModelOnly (#285) 기본 모델 경로에 Sulphur 2 LoRA를 적용하여 캐릭터 충실도와 스타일 큐가 두 샘플링 단계에 전송됩니다. 동일한 LTX‑2.3 백본을 유지하면서 빠르게 외관을 전환하는 데 사용합니다. Hugging Face: SulphurAI/Sulphur-2-base
선택적 추가 항목#
- 시드 제어: 두
RandomNoise노드에서 고정 값을 설정하여 테이크를 재현 가능하게 하고, 하나의 시드를 변경하여 대안을 탐색합니다. - 프롬프트 작성: 프롬프트를 샷 지침(주제, 카메라, 조명, 분위기)으로 작성합니다. 부정적 목록은 집중적이고 짧게 유지합니다.
- 성능: VRAM이 제한된 경우 FP8 LTX‑2.3 가중치를 선호하고 타일 디코딩을 활성화 상태로 유지합니다.
- 출력: 그래프는 MP4/H.264를 작성합니다;
SaveVideo에서 컨테이너나 코덱을 변경하여 ProRes 프록시 워크플로우가 필요할 경우 조정합니다.
이 LTX 2.3 Sulphur 2 텍스트를 비디오로 전환하는 워크플로우는 프롬프트에서 동기화된 오디오와 정제된 비디오로의 깨끗한 엔드 투 엔드 경로를 제공하며, 시네마틱 캐릭터 애니메이션에 대한 빠른 반복을 위해 구축되었습니다.
감사#
이 워크플로우는 다음의 작업 및 리소스를 구현하고 구축합니다. Sulphur2 기본 워크플로우를 위한 RunningHub, Sulphur-2-base 모델을 위한 SulphurAI, LTX-2.3 및 LTX-2.3-fp8 모델을 위한 Lightricks, LTX-2 텍스트 인코더를 위한 Comfy-Org의 기여와 유지보수에 감사를 드립니다. 권위 있는 세부 사항은 아래에 링크된 원본 문서 및 저장소를 참조하십시오.
리소스#
- RunningHub/Sulphur2 기본 워크플로우를 위한 비디오 제작
- 문서 / 릴리즈 노트: Sulphur2 기본 워크플로우를 위한 비디오 제작
- SulphurAI/Sulphur-2-base
- Hugging Face: SulphurAI/Sulphur-2-base
- Lightricks/LTX-2.3
- GitHub: Lightricks/LTX-2
- Hugging Face: Lightricks/LTX-2.3
- arXiv: LTX-2: Efficient Joint Audio-Visual Foundation Model (2601.03233)
- Lightricks/LTX-2.3-fp8
- GitHub: [Lightricksjson
/LTX-2](https://github.com/Lightricks/LTX-2)
- Hugging Face: Lightricks/LTX-2.3-fp8
- arXiv: LTX-2: Efficient Joint Audio-Visual Foundation Model (2601.03233)
- Comfy-Org/ltx-2
- Hugging Face: Comfy-Org/ltx-2
Note: Use of the referenced models, datasets, and code is subject to the respective licenses and terms provided by their authors and maintainers.