
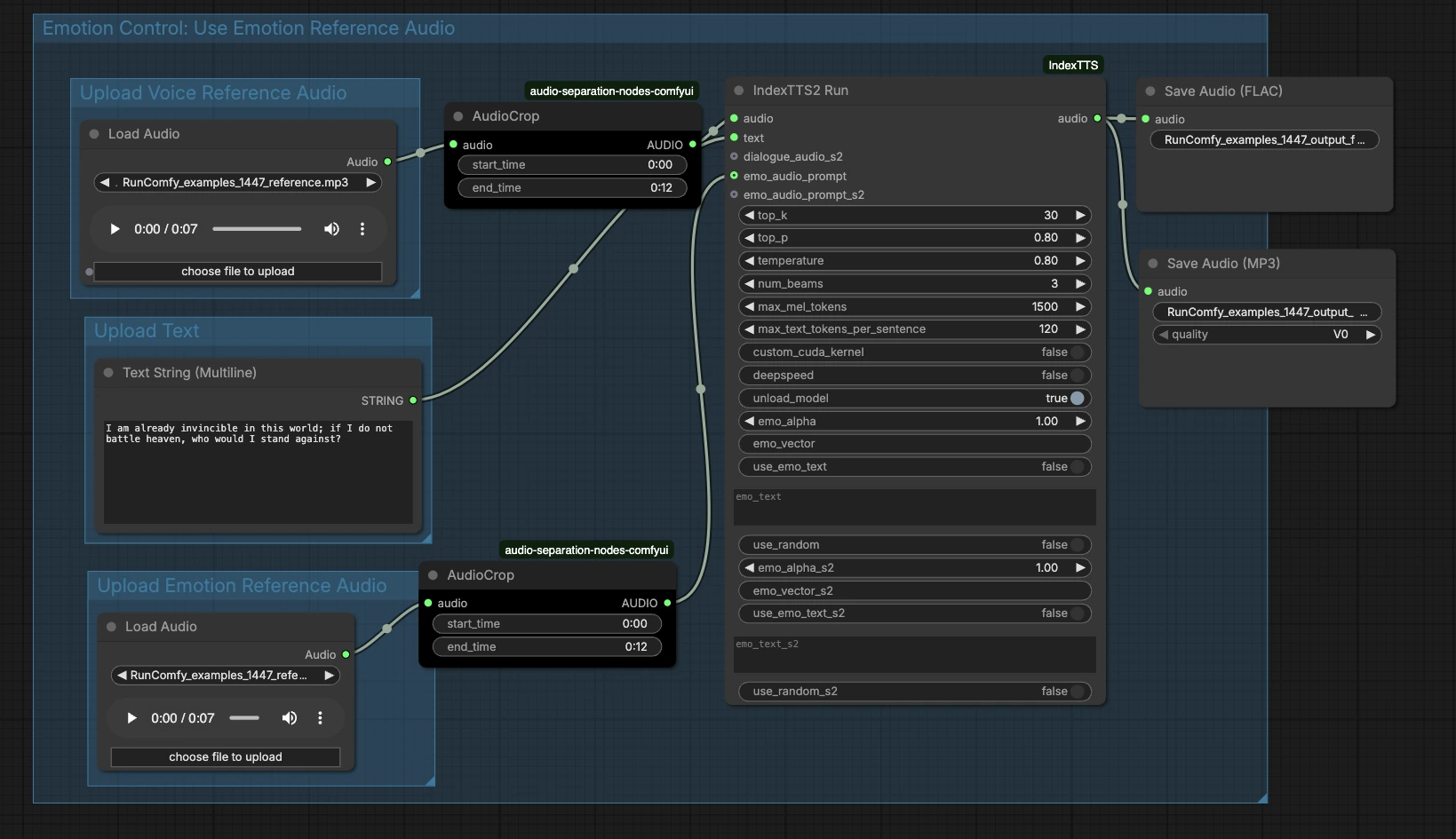
IndexTTS2 ComfyUI 워크플로우: 참조 오디오를 통한 감정 음성 복제#
이 IndexTTS2 ComfyUI 워크플로우는 짧은 참조 클립을 자연스럽고 표현력 있는 음성으로 변환하여 화자의 음색과 스타일을 일치시킵니다. 깨끗한 참조 오디오, 선택적 감정 프롬프트 및 스크립트를 제공하면 그래프가 고품질의 음성 복제를 생성하여 FLAC으로 보관하거나 MP3로 빠르게 공유할 수 있습니다.
IndexTTS-2 모델과 ComfyUI IndexTTS 노드를 기반으로 구축된 이 워크플로우는 빠르고 재현 가능한 감정 TTS를 원하는 창작자, 캐릭터 디자이너, 교육자 및 RunComfy 사용자에게 이상적입니다. 모든 작업이 ComfyUI 내에서 이루어지므로 입력을 검사하고 설정을 조정하며 내레이션, 대화 및 음성 예제에 빠르게 반복할 수 있습니다.
Comfyui IndexTTS2 ComfyUI 워크플로우의 주요 모델#
- IndexTeam의 IndexTTS-2. 참조 기반 음성 복제 및 표현력 있는 운율 제어를 수행하는 현대적인 텍스트-음성 변환 시스템입니다. 짧은 화자 예제에 조건을 부여하고 선택적으로 감정 신호에 조건을 부여하여 텍스트에서 자연스러운 음성을 렌더링합니다. Hugging Face의 모델 카드와 동반 논문에서 건축 및 교육 세부 정보에 대해 알아보세요: IndexTTS-2, IndexTTS 프로젝트, IndexTTS-2 논문.
Comfyui IndexTTS2 ComfyUI 워크플로우 사용 방법#
고급 수준에서 그래프는 참조 음색 오디오, 텍스트, 선택적 감정 오디오의 세 가지 입력을 받아 생성 및 결과를 내보냅니다. 아래 그룹은 입력을 추가할 위치와 최종 음성에 연결되는 방법을 보여줍니다.
음성 참조 오디오 업로드#
이 그룹은 화자 정체성을 준비합니다. LoadAudio (#13)에 대상 음성의 깨끗한 샘플을 로드하세요. 이상적으로는 음악이나 효과 없이 명확하게 말하는 단일 화자의 샘플이어야 합니다. AudioCrop (#37)을 사용하여 안정적인 세그먼트를 분리하여 시스템이 일관된 음색을 학습하도록 합니다. 안정적인 피치와 중립적인 전달을 가진 짧은 세그먼트는 가장 신뢰할 수 있는 복제를 생성합니다. 잘라낸 참조는 생성기를 조건화하기 위해 앞으로 전송됩니다.
텍스트 업로드#
PrimitiveStringMultiline (#14)에 스크립트를 입력하세요. 명확한 구두점은 모델이 멈춤과 강조를 추론하는 데 도움이 되므로, 원하는 방식으로 텍스트를 작성하세요. 여러 문장을 읽을 계획이라면 각 문장을 잘 형성하고 이모티콘이나 드문 기호를 피하세요. 텍스트는 렌더링을 위해 합성 노드로 직접 전달됩니다.
감정 참조 오디오 업로드#
원하는 감정이나 전달을 캡처하는 선택적 클립을 제공하세요. 예를 들어, 흥분, 차분함, 또는 침울함 등을 LoadAudio (#15)를 통해 제공합니다. AudioCrop (#38)으로 모방하려는 표현력 있는 부분만 유지하도록 자릅니다. 이는 음색 참조와 별개이며 리듬, 에너지 및 톤에 중점을 둡니다. 이 단계를 건너뛰면 IndexTTS2 ComfyUI 워크플로우는 운율을 위해 텍스트만을 사용합니다.
감정 제어: 감정 참조 오디오 사용#
이 영역은 생성기에 감정 프롬프트를 연결합니다. 잘라낸 감정 클립은 IndexTTS2Run (#12)의 emo_audio_prompt 입력으로 전달되어 대상 음성을 유지하면서 리듬과 강도를 안내합니다. 감정 오디오 예제가 없는 경우 노드의 감정 텍스트 컨트롤을 사용하여 스타일을 미세 조정할 수도 있습니다. 실제로 감정 오디오는 더 강하고 일관된 표현력을 제공하는 경향이 있으며, 감정 텍스트는 더 가벼운 방향성을 제공합니다. 구체적인 예와 텍스트 힌트를 모두 원할 때 함께 사용하세요.
생성 및 내보내기#
IndexTTS2Run (#12)은 텍스트, 음색 참조 및 감정 안내를 사용하여 음성을 합성합니다. 출력은 SaveAudio (#17)로 손실 없는 FLAC으로, SaveAudioMP3 (#39)로 작은 웹 친화적 미리 보기로 라우팅됩니다. 저장 노드의 파일 이름 필드를 사용하여 반복 간에 테이크를 정리하세요. 이 디자인은 동일한 화자 정체성을 유지하면서 다른 텍스트나 감정을 A/B 테스트하기 쉽게 만듭니다.
Comfyui IndexTTS2 ComfyUI 워크플로우의 주요 노드#
IndexTTS2Run (#12)#
이것은 IndexTTS-2를 래핑하고 샘플링, 빔 검색 및 감정 조건화를 위한 컨트롤을 노출하는 핵심 생성기입니다. 안정성과 다양성의 균형을 맞추기 위해 top_p, top_k 및 temperature를 조정하세요. 낮은 값은 더 일관된 읽기를 제공하고, 높은 값은 자발성을 증가시킵니다. num_beams를 사용하여 노드가 더 많은 후보 읽기를 검색하게 하여 속도와 품질을 맞바꿉니다. 긴 스크립트의 경우, max_mel_tokens와 max_text_tokens_per_sentence를 사용하여 오디오 및 텍스트 청크 크기를 제한하여 오버런을 방지합니다. 감정은 emo_audio_prompt, emo_alpha로 믹스 강도를 조정하거나 use_emo_text와 emo_text를 사용하여 텍스트 신호를 선호할 때 조정할 수 있습니다. 하드웨어에 따라 deepspeed, custom_cuda_kernel 및 unload_model과 같은 성능 보조 도구가 제공됩니다. 노드 구현은 ComfyUI IndexTTS 사용자 정의 노드에 의해 제공되며, 기본 모델은 여기에서 문서화됩니다: IndexTTS-2, IndexTTS 프로젝트.
AudioCrop (#37) — 참조 음색#
이 노드를 사용하여 화자 샘플에서 깨끗하고 안정적인 발췌 부분을 분리하세요. 배경 소음, 웃음 또는 극단적인 감정을 피하세요. 이러한 세부 사항은 복제된 음성으로 유출될 수 있습니다. 일관된 톤으로 자르면 정체성 잠금이 개선되고 원치 않는 아티팩트가 줄어듭니다.
AudioCrop (#38) — 감정 프롬프트#
이 자르기는 전달을 제어하는 표현적 단서를 선택합니다. 원하는 리듬이나 강도를 정확히 가진 부분을 선택하고 신호를 희석하지 않도록 간결하게 유지하세요. 최고의 일관성을 위해 가능하다면 음색 참조와 동일한 화자의 감정 프롬프트를 사용하세요.
선택적 추가 기능#
- 참조 오디오는 건조하고 단일 채널로 유지하세요. 리버브, 배경 음악 및 과도한 압축을 제거하여 더 깨끗한 복제를 만드세요.
- 의도적으로 구두점을 찍으세요. 쉼표, 마침표 및 물음표는 모델이 의도에 맞는 멈춤과 억양을 배치하는 데 도움이 됩니다.
- 재현 가능한 테이크를 위해 노드에서 무작위성을 비활성화하거나 텍스트 및 오디오 선택에 대한 메모를 보관하여 나중에 동일한 출력을 다시 생성할 수 있도록 하세요.
- VRAM이 부족할 경우, 실행 간에 모델 언로드를 활성화하세요. 약간의 시간 비용이 추가될 수 있지만 다른 그래프를 위한 메모리가 해제됩니다.
- 음성 권리를 존중하세요. 참조 녹음을 복제할 권한이 있는 경우에만 사용하고, 필요한 경우 합성 음성을 공개하세요.
감사의 글#
이 워크플로우는 다음 작업 및 리소스를 구현하고 구축합니다. 우리는 워크플로우 참조를 제공한 RunningHub, Cloud Save 워크플로우를 제공한 RunComfy, IndexTTS 및 IndexTTS-2를 제공한 Index Team, IndexTTS2 논문의 저자, ComfyUI IndexTTS 사용자 정의 노드를 제공한 billwuhao에게 감사드립니다. 권위 있는 세부 정보는 아래에 링크된 원본 문서 및 저장소를 참조하세요.
리소스#
- RunningHub/워크플로우 참조
- 문서 / 릴리스 노트: RunningHub post
- RunComfy/Cloud Save 워크플로우
- 문서 / 릴리스 노트: RunComfy workflow
- index-tts/index-tts
- GitHub: index-tts/index-tts
- IndexTeam/IndexTTS-2
- Hugging Face: IndexTeam/IndexTTS-2
- IndexTTS2/논문
- arXiv: 2506.21619
- billwuhao/ComfyUI_IndexTTS
- GitHub: billwuhao/ComfyUI_IndexTTS
참고: 참조된 모델, 데이터 세트 및 코드는 해당 저자 및 유지 관리자가 제공한 라이선스 및 조건이 적용됩니다.

