
Hallo2 기술은 Fudan University와 Baidu Inc.의 Jiahao Cui, Hui Li, Yao Yao, Hao Zhu, Hanlin Shang, Kaihui Cheng, Hang Zhou, Siyu Zhu, 그리고 Jingdong Wang에 의해 개발되었습니다. 더 많은 정보는 Hallo2 GitHub에서 확인하세요. ComfyUI_Hallo2 노드와 워크플로우는 smthemex에 의해 개발되었습니다. 더 많은 세부 사항은 ComfyUI_Hallo2 GitHub에서 확인하세요. 모든 공로는 그들의 기여에 있습니다.
1. Hallo2 소개#
Hallo2는 고품질, 장시간, 4K 해상도의 오디오 기반 초상화 애니메이션 비디오를 생성하는 첨단 모델입니다. 원래의 Hallo 모델을 기반으로 몇 가지 주요 개선점을 추가했습니다:
- 최대 수십 분 또는 심지어 몇 시간 길이의 훨씬 더 긴 비디오 생성 지원
- 4K 해상도로 비디오 생성
- 오디오뿐만 아니라 텍스트 프롬프트를 사용하여 표현과 자세 제어 가능
Hallo2는 데이터 증강 같은 고급 기술을 사용하여 긴 기간 동안 일관성을 유지하고, 4K 해상도를 위한 잠재 코드의 벡터 양자화, 그리고 오디오와 텍스트에 의해 안내되는 개선된 노이즈 감소 과정을 통해 이를 달성합니다.
2. Hallo2의 기술적 특징#
Hallo2는 고품질 초상화 비디오를 생성하기 위해 여러 고급 AI 모델과 기술을 결합합니다:
- Diffusion Model: 비디오 프레임을 생성하는 핵심 "엔진"입니다. 무작위 노이즈로 시작하여 오디오와 텍스트 프롬프트에 의해 안내된 원하는 출력에 맞도록 점진적으로 개선합니다.
- 3D U-Net: 확산 과정에서 "조각가" 역할을 하는 신경망 유형입니다. 현재의 노이즈 프레임, 오디오, 텍스트 지침을 보고 노이즈를 최종 초상화처럼 보이게 변경하는 방법을 제안합니다.
- Audio Encoder: Hallo2는 Wav2Vec2라는 모델을 "귀"로 사용하여 오디오를 이해하고, 원시 파형을 톤, 속도, 음성 콘텐츠를 포착하는 압축 표현으로 변환합니다.
- Face Detector: 초상화의 얼굴을 애니메이션하는 데 집중하기 위해 Hallo2는 참조 이미지에서 초상화의 얼굴을 자동으로 찾는 얼굴 인식 모델을 사용합니다. 그런 다음 입술과 표정 움직임을 적용할 위치를 알게 됩니다.
- Image Compressor: 고해상도 4K 이미지를 효율적으로 작업하기 위해 Hallo2는 VQ-VAE라는 특별한 유형의 오토인코더 모델을 사용하여 더 작은 "잠재" 표현으로 압축하고, 마지막에 다시 4K로 디코딩합니다. 이는 JPEG가 이미지 파일 크기를 줄이면서 품질을 보존하는 것과 같습니다.
- Augmentation Tricks: 긴 비디오 동안 품질을 유지하기 위해 Hallo2는 이전에 생성된 프레임에 몇 가지 영리한 "데이터 증강"을 적용하여 다음 프레임에 영향을 줍니다. 여기에는 가끔 무작위 패치를 지우거나 미세한 노이즈를 추가하는 것이 포함됩니다. 이는 시간이 지남에 따라 축적되어 일관성을 해칠 수 있는 누적 오류를 방지하는 데 도움이 됩니다.
요약하자면 - Hallo2는 오디오와 초상화 이미지를 입력으로 받아, AI "에이전트"가 이를 일치시키면서 원래 초상화에 충실하도록 비디오 프레임을 조각하며, 모든 것을 동기화하고 일관되게 유지하기 위한 몇 가지 추가 트릭을 사용합니다. 이러한 모든 부분은 인상적인 결과를 생성하기 위해 다단계 파이프라인에서 함께 작동합니다.
3. ComfyUI Hallo2 워크플로우 사용법#
Hallo2는 여러 전문 노드를 가진 사용자 정의 워크플로우를 통해 ComfyUI에 통합되었습니다. 사용 방법은 다음과 같습니다:
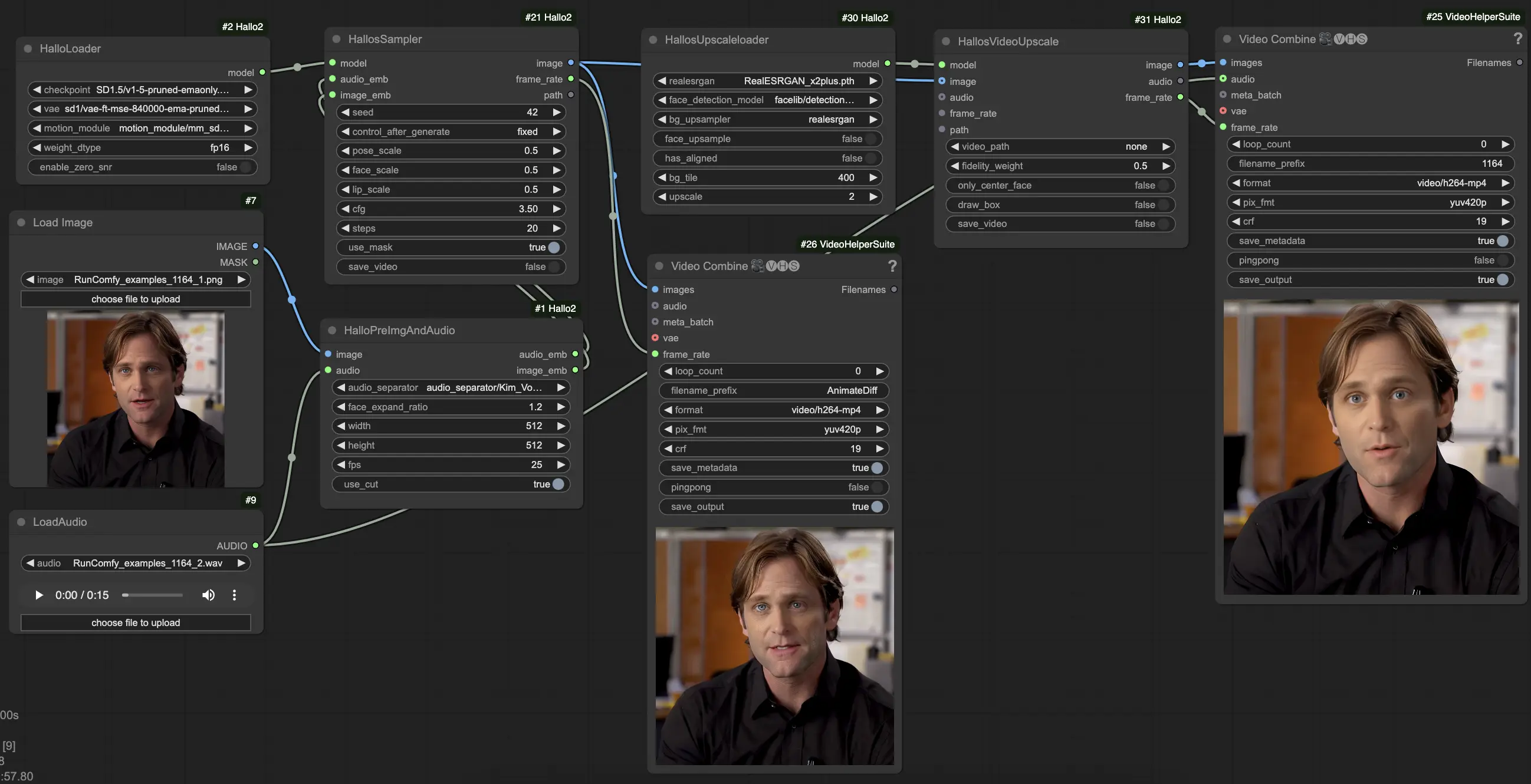
LoadImage노드를 사용하여 참조 초상화 이미지를 로드합니다. 이는 명확한 정면 초상화여야 합니다. (팁: 참조 초상화가 잘 구성되고 조명이 잘 맞을수록 결과가 좋아집니다. 측면 프로필, 차폐, 복잡한 배경 등을 피하세요.)LoadAudio노드를 사용하여 구동 오디오를 로드합니다. 초상화가 표현하고자 하는 분위기에 맞아야 합니다.- 이미지를 오디오와 함께
HalloPreImgAndAudio노드에 연결합니다. 이는 이미지와 오디오를 임베딩으로 전처리합니다. 주요 매개변수:audio_separator: 배경 소음에서 음성을 분리하는 모델입니다. 일반적으로 기본값으로 두십시오.face_expand_ratio: 감지된 얼굴 영역을 얼마나 확장할지. 더 높은 값은 더 많은 머리/배경을 포함합니다.width/height: 생성 해상도. 더 높은 값은 더 느리지만 더 상세합니다. 512-1024 정사각형이 좋은 균형입니다.fps: 대상 비디오 FPS. 25가 좋은 기본값입니다.
HalloLoader노드를 사용하여 핵심 Hallo2 모델을 로드합니다. Hallo2 체크포인트, VAE, 모션 모듈 파일을 가리킵니다.- 전처리된 이미지와 오디오 임베딩을 로드된 모델과 함께
HalloSampler노드에 연결합니다. 실제 비디오 생성을 수행합니다. 주요 매개변수:seed: 세부 사항을 결정하는 무작위 시드. 첫 결과가 마음에 들지 않으면 변경하세요.pose_scale/face_scale/lip_scale: 포즈, 얼굴 표정, 입술 움직임의 강도를 얼마나 확장할지. 1.0 = 전체 강도, 0.0 = 고정.cfg: 분류기 없는 가이드 스케일. 높을수록 조건을 더 정확히 따르지만 다양성은 줄어듭니다.steps: 노이즈 감소 단계 수. 더 많은 단계 = 더 나은 품질이지만 더 느립니다.
- 이 시점에서 생성된 비디오를 볼 수 있습니다. 슈퍼 해상도로 품질을 더 향상시키려면, 체인의 끝에
HallosUpscaleloader와HallosVideoUpscale노드를 추가하세요. 업스케일 로더는 미리 학습된 업스케일링 모델을 읽고, 업스케일러 노드는 실제로 4K로 업스케일링을 수행합니다.