
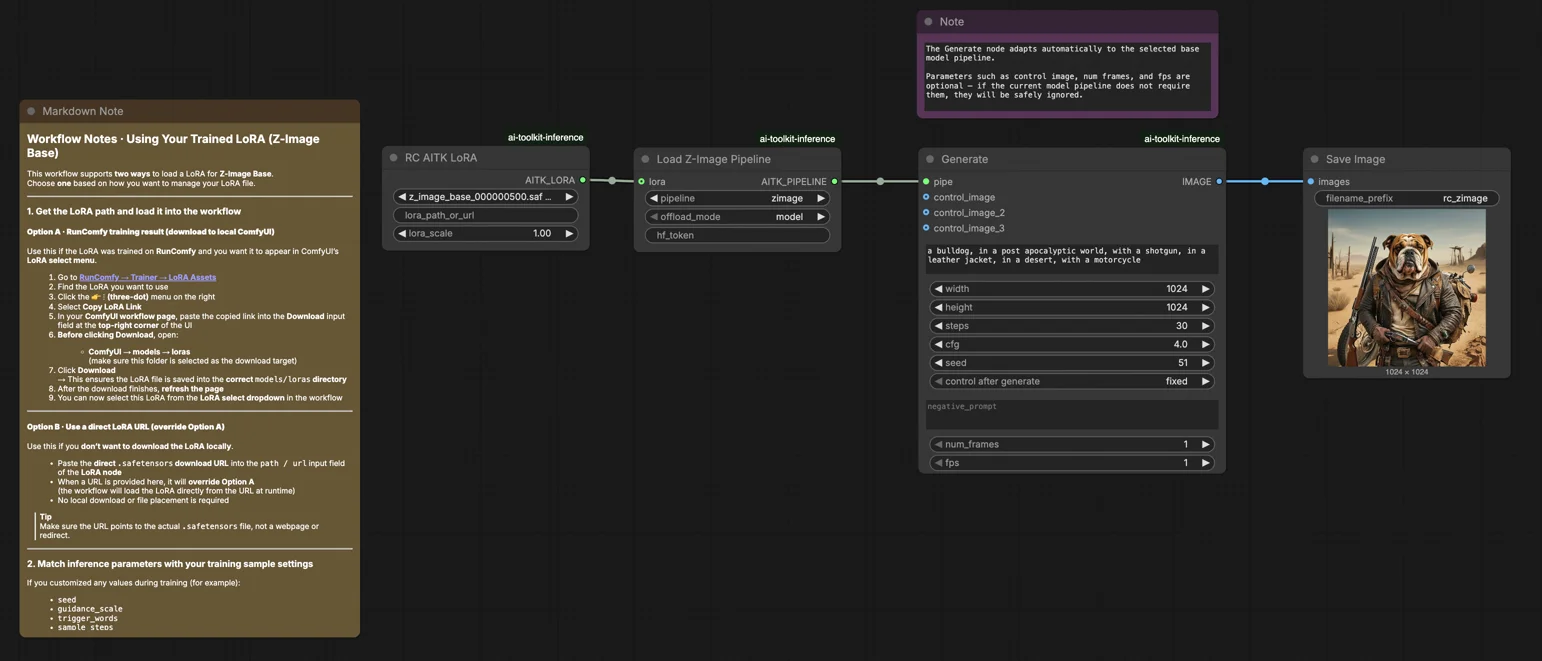
Z-Image ベース LoRA ComfyUI 推論: AI Toolkit LoRA によるトレーニングに一致した生成#
この本番対応の RunComfy ワークフローは、AI Toolkit でトレーニングされた Z-Image LoRA アダプターを ComfyUI で トレーニングに一致した 結果で実行できるようにします。RC Z-Image (RCZimage) を中心に構築されています—これは RunComfy によってオープンソース化されたパイプラインレベルのカスタムノードです(source)。ワークフローは Tongyi-MAI/Z-Image 推論パイプラインをラップしており、一般的なサンプラーグラフに頼ることはありません。アダプターはそのパイプライン内で lora_path と lora_scale を通じて注入され、AI Toolkit がトレーニングプレビューを生成する方法と一致した状態を保ちます。
なぜ Z-Image ベース LoRA ComfyUI 推論が ComfyUI で異なるように見えるのか#
AI Toolkit のトレーニングプレビューはモデル固有の推論パイプラインによってレンダリングされます—スケジューラーの設定、コンディショニングフロー、および LoRA インジェクションはすべてそのパイプライン内で行われます。標準の ComfyUI サンプラーグラフはこれらの要素を異なる方法で組み立てるため、同じプロンプト、シード、ステップ数でも著しく異なる出力が得られることがあります。このギャップは単一の間違ったパラメータによるものではなく、パイプラインレベルの不一致によるものです。RCZimage は Z-Image パイプラインを直接ラップし、LoRA をその中で適用することによってトレーニングに一致した動作を回復します。実装の参照: `src/pipelines/z_image.py`。
Z-Image ベース LoRA ComfyUI 推論ワークフローの使用方法#
ステップ 1: LoRA パスを取得し、ワークフローにロードする(2 つのオプション)#
オプション A — RunComfy トレーニング結果 → ローカル ComfyUI にダウンロード:
- Trainer → LoRA Assets にアクセス
- 使用したい LoRA を見つけます
- 右側の ⋮ (三点) メニュー をクリック → Copy LoRA Link を選択
- ComfyUI ワークフローページで、コピーしたリンクを UI の 右上隅 の Download 入力フィールドに貼り付けます
- Download をクリックする前に、ターゲットフォルダーが ComfyUI → models → loras に設定されていることを確認します(このフォルダーがダウンロードターゲットとして選択されている必要があります)
- Download をクリック — これにより、LoRA ファイルが正しい
models/lorasディレクトリに保存されます - ダウンロードが完了したら、ページをリフレッシュ
- LoRA はワークフローの LoRA 選択ドロップダウン に表示されます — 選択します

オプション B — 直接 LoRA URL(オプション A を上書き):
- 直接
.safetensorsダウンロード URL を LoRA ノード のpath / url入力フィールドに貼り付けます - ここに URL が提供されると、オプション A を上書きします — ワークフローは実行時に URL から直接 LoRA をロードします
- ローカルダウンロードやファイル配置は必要ありません
ヒント: URL は実際の .safetensors ファイルを指している必要があり、ウェブページやリダイレクトではありません。

ステップ 2: 推論パラメータをトレーニングサンプル設定と一致させる#
LoRA ノードで lora_scale を設定します — トレーニングプレビューで使用したのと同じ強度から始め、その後必要に応じて調整します。
残りのパラメータは Generate ノードにあります:
prompt— テキストプロンプト; トレーニング中に使用したトリガーワードを含めますnegative_prompt— トレーニング YAML にネガティブが含まれていない限り空白のままにしますwidth/height— 出力解像度; 直接比較のためにプレビューサイズと一致させます(32 の倍数)sample_steps— 推論ステップ数; Z-Image ベースのデフォルトは 30 です(プレビュー設定で使用した同じ数を使用)guidance_scale— CFG 強度; デフォルトは 4.0 です(最初にトレーニングプレビュー値をミラーします)seed— 特定の出力を再現するためにシードを固定します; 変化を探索するために変更しますseed_mode—fixedまたはrandomizeを選択hf_token— Hugging Face トークン; ベースモデルまたは LoRA リポジトリがゲートされている/プライベートである場合にのみ必要です
トレーニングアラインメントのヒント: トレーニング中にカスタマイズしたサンプリング値がある場合、それらを対応するフィールドに正確にコピーします。RunComfy でトレーニングした場合、Trainer → LoRA Assets → Config にアクセスして、解決済みの YAML を確認し、プレビュー/サンプル設定をノードにコピーします。

ステップ 3: Z-Image ベース LoRA ComfyUI 推論を実行#
Queue/Run をクリック — SaveImage ノードが結果を自動的に ComfyUI の出力フォルダーに書き込みます。
クイックチェックリスト:
- ✅ LoRA は次のいずれか:
ComfyUI/models/lorasにダウンロード済み(オプション A)、または直接.safetensorsURL を通じてロード済み(オプション B) - ✅ ローカルダウンロード後にページをリフレッシュ(オプション A のみ)
- ✅ 推論パラメータはトレーニング
sample設定に一致(カスタマイズされている場合)
上記のすべてが正しければ、ここでの推論結果はトレーニングプレビューに非常に近いはずです。
Z-Image ベース LoRA ComfyUI 推論のトラブルシューティング#
Z-Image ベース (Tongyi-MAI/Z-Image) の「トレーニングプレビュー vs ComfyUI 推論」ギャップの多くは、パイプラインレベルの違い(モデルの読み込み方法、使用されるデフォルト/スケジューラー、LoRA の注入場所)が原因です。 AI Toolkit でトレーニングされた Z-Image ベース LoRA の場合、ComfyUI で トレーニングに一致した 行動に戻るための最も信頼できる方法は、生成を RCZimage(RunComfy パイプラインラッパー)を通して実行し、lora_path / lora_scale を通じてそのパイプライン内で LoRA を注入することです。
(1) Z-Image LoRA を ComfyUI で使用する際に「lora key not loaded」というメッセージが表示されます。#
なぜこれが起こるのか これは通常、LoRA が現在の ComfyUI Z-Image ローダーが期待する 異なるモジュール/キーのレイアウト に対してトレーニングされたことを意味します。Z-Image では、「同じモデル名」であっても異なるキーの規則(例: オリジナル/ディフューザーズスタイル vs Comfy 固有の命名)が関与する可能性があり、それが「キーが読み込まれない」トリガーとなります。
推奨する修正方法
- 推論を RCZimage(ワークフローのパイプラインラッパー)を通して実行し、アダプターを
lora_pathを通じて RCAITKLoRA / RCZimage パス にロードし、別の一般的な Z-Image LoRA ローダーを通じて注入しないでください。 - ワークフローを 形式一貫性 に保つ: AI Toolkit でトレーニングされた Z-Image ベース LoRA → AI Toolkit に一致した RCZimage パイプラインで推論を行い、ComfyUI 側のキーの再マッピング/コンバータに依存しないようにします。
(2) ZIMAGE LORA ローダー(モデルのみ)を使用した際に VAE フェーズでエラーが発生しました。#
なぜこれが起こるのか 一部のユーザーは、ZIMAGE LoRA ローダー(モデルのみ)を追加すると、デフォルトの Z-Image ワークフローが問題なく動作する場合でも、最終的な VAE デコードステージでの大幅な遅延や後の失敗を引き起こす可能性があると報告しています。
ユーザー確認済みの修正方法
- ZIMAGE LORA ローダー(モデルのみ)を削除し、デフォルトの Z-Image ワークフローパスを再実行します。
- この RunComfy ワークフローでは、同等の「安全なベースライン」は次のとおりです: RCZimage +
lora_path/lora_scaleを使用して、LoRA 適用を パイプライン内 に保持し、「モデルのみの LoRA ローダー」パスを回避します。
(3) Z-Image Comfy フォーマットがオリジナルコードと一致しない#
なぜこれが起こるのか ComfyUI での Z-Image は、Comfy 固有のフォーマット(「オリジナル」規則からのキー命名の違いを含む)を含む場合があります。もし AI Toolkit でトレーニングされた LoRA が一つの命名/レイアウトの規則であり、それを ComfyUI で別の規則を期待して適用しようとすると、部分的/失敗した適用や「実行されるが見た目が間違っている」動作が見られます。
推奨する修正方法
- トレーニングプレビューに一致させようとする際には形式を混ぜないでください。RCZimage を使用して推論を行い、AI Toolkit プレビューが使用する「ファミリー」で Z-Image パイプラインを実行し、
lora_path/lora_scaleを通じてその中で LoRA を注入します。 - Comfy フォーマットの Z-Image スタックを使用する必要がある場合は、そのスタックが期待する 同じ フォーマットで LoRA があることを確認してください(そうでない場合、キーは一致しません)。
(4) Z-Image oom using lora#
なぜこれが起こるのか Z-Image + LoRA は、精度/量子化、解像度、およびローダーパスによって VRAM を限界まで押し上げる可能性があります。いくつかの報告では、12GB VRAM セットアップで低精度モードと LoRA を組み合わせた際に OOM が発生することが指摘されています。
安全なベースラインの修正方法
- まずベースラインを検証します: ターゲット解像度で LoRA なしの Z-Image ベースを実行します。
- その後、RCZimage (
lora_path/lora_scale) を通じて LoRA を追加し、比較を制御します(同じwidth/height、sample_steps、guidance_scale、seed)。 - それでも OOM が発生する場合は、まず解像度を下げます(Z-Image はピクセル数に敏感です)、次に
sample_stepsを削減し、その後安定性が確認された後に高い設定を再導入します。RunComfy では、より大きなマシンに切り替えることもできます。
今すぐ Z-Image ベース LoRA ComfyUI 推論を実行#
RunComfy の Z-Image ベース LoRA ComfyUI 推論 ワークフローを開き、lora_path を設定し、RCZimage が ComfyUI の出力を AI Toolkit トレーニングプレビューと一致させ続けます。
