
ComfyUI用Wan 2.2 VACEポーズ駆動ビデオ生成#
このComfyUI Wan 2.2 VACEワークフローは、単一の参照画像を元に、ポーズ、リズム、カメラの動きに従うモーションマッチビデオに変換します。Wan 2.2 VACEを使用してアイデンティティを保持しながら、複雑な身体の動きをスムーズでリアルなアニメーションに翻訳します。
ダンス生成、モーショントランスファー、クリエイティブキャラクターアニメーションのために設計されたこのワークフローは、参照画像からスタイルプロンプトを自動化し、ソースビデオからモーションシグナルを抽出し、モーションの一貫性と細部をバランスよく保つ2段階のWan 2.2サンプラーを実行します。
Comfyui Wan 2.2 VACEワークフローの主要モデル#
- Wan 2.2 14B テキストからビデオモデル(高ノイズと低ノイズのバリアント)。デュアルステージは、堅牢なモーションシェーピングのために高ノイズのバックボーンを使用し、その後に詳細の洗練のために低ノイズのバックボーンを使用します。
- Wan 2.1 VAE (bf16)。Wan 2.2 VACEのために潜在ビデオフレームをデコードおよびエンコードします。
- Google UMT5-XXL Encoder。Wan 2.2が条件付けに使用する高容量のテキスト機能を提供します。 Model card
- Microsoft Florence-2 (Flux Large)。参照画像から豊かなキャプションを生成し、プロンプトを起動およびスタイリングします。 Repo
- Depth Anything v2 (ViT-L)。モーションソースビデオからフレームごとの深度マップを生成し、構造と動きをガイドします。 Repo
Comfyui Wan 2.2 VACEワークフローの使用方法#
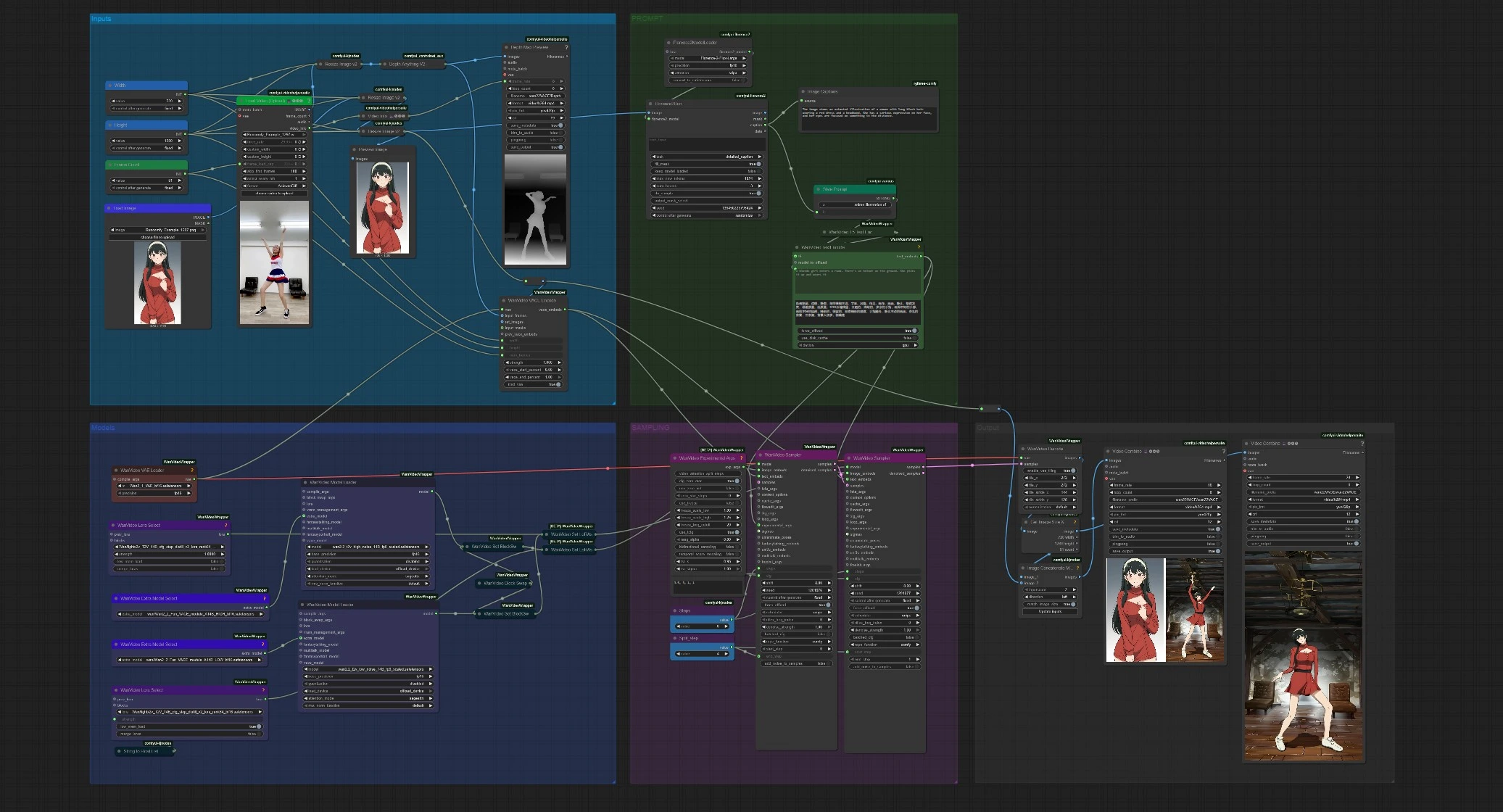
ワークフローは、入力、プロンプト、モデル、サンプリング、および出力の5つのグループ化されたステージで構成されています。1つの参照画像と1つの短いモーションビデオを提供します。その後、グラフはモーションガイダンスを計算し、VACEアイデンティティ機能をエンコードし、2パスのWan 2.2サンプラーを実行し、最終アニメーションとオプションのサイドバイサイドプレビューの両方を保存します。
入力#
VHS_LoadVideo (#141)でモーションソースクリップをロードします。簡単なコントロールでトリミングし、メモリ用にフレームをキャップできます。フレームは一貫性のためにリサイズされ、その後DepthAnythingV2Preprocessor (#135)がポーズ、レイアウト、カメラの動きを捉える密な深度シーケンスを計算します。LoadImage (#113)でアイデンティティ画像をロードします。自動リサイズされ、サンプリング前にフレーミングを確認できるようプレビューされます。
プロンプト#
Florence2Run (#137)は参照画像を分析し、詳細なキャプションを返します。Style Prompt (#138)はそのキャプションを短いスタイルフレーズと連結し、WanVideoTextEncode (#16)はUMT5-XXLを使用して最終的なポジティブおよびネガティブプロンプトをエンコードします。スタイルフレーズを自由に編集したり、ポジティブプロンプトを完全に置き換えたりして、より強力なクリエイティブディレクションを提供できます。このプロンプト埋め込みは、両方のサンプラーステージを条件付けし、生成されたビデオが参照に忠実であることを保証します。
モデル#
WanVideoVAELoader (#38)は、エンコード/デコード全体で使用されるWan VAEをロードします。2つのWanVideoModelLoaderノードは、Wan 2.2 14Bモデルを準備します:1つは高ノイズ、もう1つは低ノイズで、各ノードはWanVideoExtraModelSelect (#99, #107)で選択されたVACEモジュールを追加しています。オプションのリファインメントLoRAはWanVideoLoraSelect (#56, #97)を通じてアタッチされ、ベースモデルを変更せずにシャープネスやスタイルを調整できます。この構成は、VACEウェイト、LoRA、またはノイズバリアントを交換してもグラフの他の部分に触れずに済むように設計されています。
サンプリング#
WanVideoVACEEncode (#100)は、モーションシーケンス(深度フレーム)、参照画像、およびターゲットビデオジオメトリをVACE埋め込みに融合します。最初のWanVideoSampler (#27)は、高ノイズモデルを使用して、スプリットステップまでモーション、視点、グローバルスタイルを確立します。2番目のWanVideoSampler (#90)は、その潜在から再開し、低ノイズモデルでテクスチャ、エッジ、小さなディテールを回復しながら、モーションをソースに固定します。短いCFGスケジュールとステップスプリットは、各ステージが結果にどれだけ影響を与えるかを制御します。
出力#
WanVideoDecode (#28)は、最終的な潜在をフレームに戻します。2つの保存されたビデオ:クリーンレンダーと、生成されたフレームを参照の横に配置するサイドバイサイドコンカットが得られます。別の「深度マッププレビュー」は、推測された深度シーケンスを示し、一目でモーションガイダンスを診断できます。フレームレートとファイル名の設定は、VHS_VideoCombineの出力 (#139, #60, #144)で利用可能です。
Comfyui Wan 2.2 VACEワークフローの主要ノード#
WanVideoVACEEncode (#100)#
両方のサンプラーで使用されるVACEアイデンティティとジオメトリの埋め込みを作成します。モーションフレームと参照画像を供給します。ノードは幅、高さ、フレーム数を処理します。期間やアスペクトを変更する場合、このノードを同期させて、埋め込みがターゲットビデオのレイアウトと一致するようにします。
WanVideoSampler (#27)#
高ノイズのWan 2.2モデルを使用する第一段階のサンプラー。steps、短いcfgスケジュール、およびend_stepスプリットを調整して、軌道のどれだけがモーションシェーピングに割り当てられるかを決定します。大きなモーションやカメラの変更は、やや遅めのスプリットが有益です。
WanVideoSampler (#90)#
低ノイズのWan 2.2モデルを使用する第二段階のサンプラー。start_stepを同じスプリット値に設定し、ステージ1からシームレスに続きます。テクスチャの過剰なシャープ化やドリフトが見られる場合は、後のcfg値を減らすか、LoRAの強度を下げます。
DepthAnythingV2Preprocessor (#135)#
ソースビデオから安定した深度シーケンスを抽出します。深度をモーションガイダンスとして使用することで、Wan 2.2 VACEはシーンレイアウト、手のポーズ、オクルージョンを保持します。高速反復のために、入力フレームを小さくリサイズできます。最終レンダーのためには、より高解像度のフレームを供給して構造の忠実度を向上させます。
WanVideoTextEncode (#16)#
UMT5-XXLでポジティブおよびネガティブプロンプトをエンコードします。プロンプトはFlorence2Runから自動生成されますが、アートディレクションのために上書きすることができます。プロンプトは簡潔に保ちます。VACEアイデンティティガイダンスがあるため、キーワードが少ない方がクリーンで制約の少ないモーショントランスファーを生むことが多いです。
オプションの追加#
- 明確な被写体の分離と一貫した照明のあるモーションクリップを選択して、最も安定したWan 2.2 VACE転送を行います。
- サイドバイサイド出力を使用して、顔の整列と衣装の連続性を検証し、最終パスをレンダリングする前に確認します。
- モーションが硬すぎる場合は、低ノイズステージがより多くの空間を持つようにスプリットを少し早めに移動します。
- アイデンティティが漂流している場合は、LoRAの影響を少し増やすか、プロンプトを簡素化します。
- 深度プレビューはあなたの友です:深度がノイズの場合、別のソースクリップを試すか、入力リサイズを調整してアーティファクトを減らします。
謝辞#
このワークフローは、以下の作品とリソースを実装し、構築しています。ComfyUIコミュニティによるWan 2.2 VACE Sourceのワークフローへの貢献とメンテナンスに感謝いたします。権威ある詳細については、以下にリンクされた元のドキュメントおよびリポジトリを参照してください。
リソース#
- Wan 2.2 VACE Source/Wan 2.2 VACE Source
- ドキュメント/リリースノート: Wan 2.2 VACE @ComfyUI
注意:参照されたモデル、データセット、およびコードの使用は、それぞれの著者およびメンテナーが提供するライセンスおよび条件に従います。