
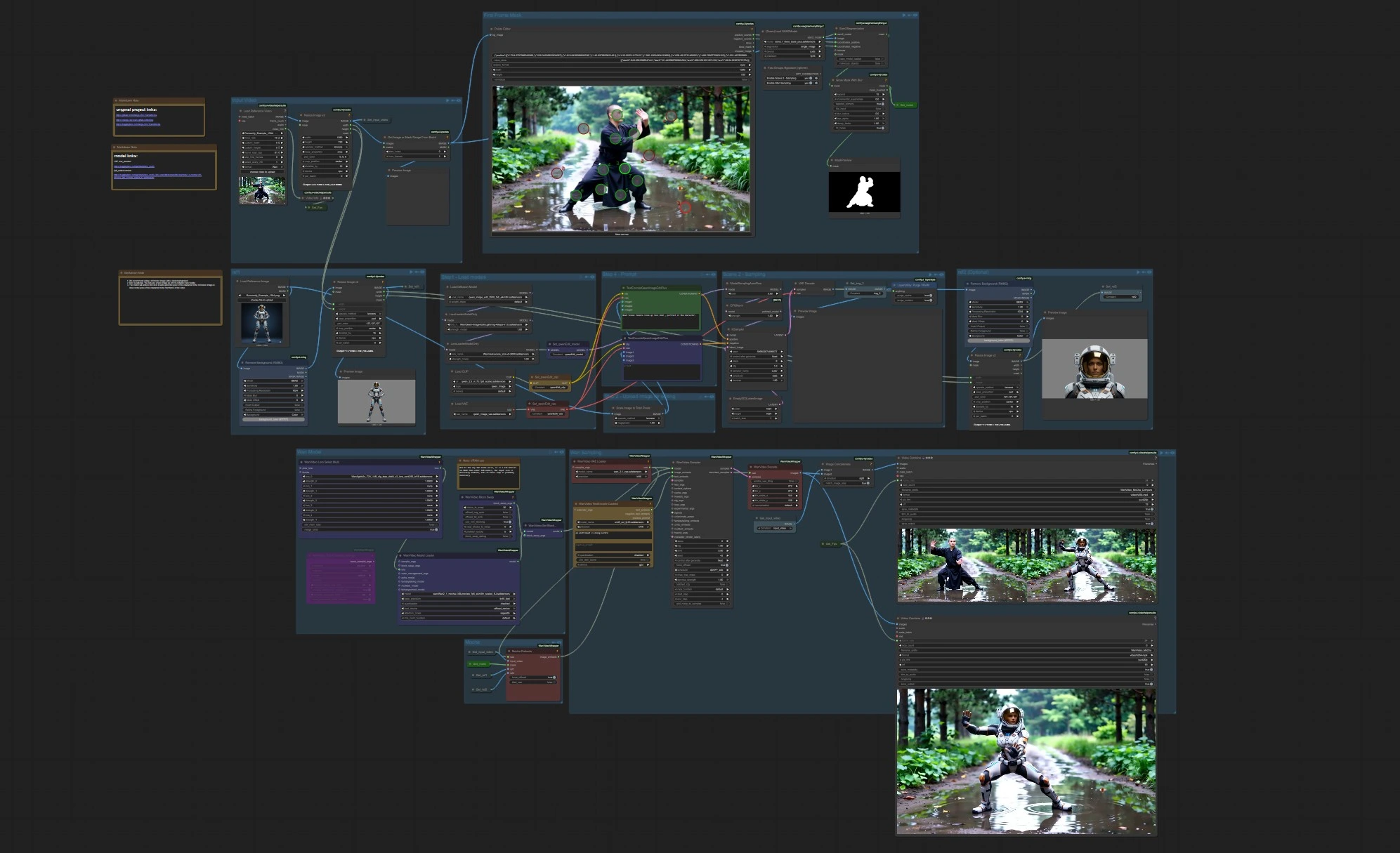
ComfyUI用のビデオキャラクター置換 (MoCha) ワークフロー#
このワークフローは、エンドツーエンドのビデオキャラクター置換 (MoCha) を提供します: リアルなビデオ内のパフォーマーを新しいキャラクターにスワップし、動き、ライティング、カメラ視点、シーンの連続性を保持します。Wan 2.1 MoCha 14B プレビューを中心に構築されており、参照アイデンティティをソースパフォーマンスに合わせ、一貫した編集クリップとオプションのサイドバイサイド比較を合成します。映画制作者、VFXアーティスト、AIクリエイター向けに設計されており、最小限の手動クリーンアップで正確で高品質なキャラクタースワップが可能です。
このパイプラインは、強力な初フレームマスキングとSegment Anything 2 (SAM 2)、MoChaの動きに対応した画像埋め込み、WanVideoのサンプリング/デコーディング、顔の忠実度を向上させるオプションのポートレートアシストを組み合わせます。ソースビデオと1枚または2枚の参照画像を提供すると、完成した置換ビデオとA/B比較が生成され、ビデオキャラクター置換 (MoCha) の反復評価が迅速かつ実用的になります。
ComfyUI用のビデオキャラクター置換 (MoCha) ワークフローの主要モデル#
- Wan 2.1 MoCha 14B プレビュー。キャラクター置換のためのコアビデオジェネレーター; MoChaの画像埋め込みとテキストプロンプトから時間的に一貫した合成を駆動します。モデルの重みはKijaiによってWanVideo Comfy形式で配布され、効率のためにfp8スケールのバリエーションも含まれています。 Hugging Face: Kijai/WanVideo_comfy, Kijai/WanVideo_comfy_fp8_scaled
- MoCha (Orange-3DV-Team)。アイデンティティ/動きの条件付け方法と参照実装で、ここで使用される埋め込みステージにインスピレーションを与えました。参照の選択とポーズの整合性を理解するのに役立ちます。 GitHub, Hugging Face
- Segment Anything 2 (SAM 2)。高品質のポイントガイドによるセグメンテーションで、初フレームの俳優を分離します。クリーンマスクは安定したアーティファクトフリーのスワップに不可欠です。 GitHub: facebookresearch/segment-anything-2
- Qwen-Image-Edit 2509 + Lightning LoRA。オプションのシングルイメージアシストで、クリーンでクローズアップのポートレートを生成し、難しいショットでの顔のアイデンティティ保持を改善します。 Hugging Face: Comfy-Org/Qwen-Image-Edit_ComfyUI, lightx2v/Qwen-Image-Lightning
- Wan 2.1 VAE。Wanサンプラー/デコーダーステージで使用されるビデオVAEで、効率的な潜在処理を行います。 Hugging Face: Kijai/WanVideo_comfy
ComfyUI用のビデオキャラクター置換 (MoCha) ワークフローの使用方法#
全体のロジック
- ワークフローはソースクリップを取り込み、初フレームマスクを準備し、キャラクター参照をMoCha画像埋め込みにエンコードします。Wan 2.1は編集されたフレームをサンプリングし、ビデオにデコードします。同時に、小さな画像編集ブランチがポートレートを生成し、顔の詳細のためにオプションの2番目の参照として機能します。グラフはまた、ビデオキャラクター置換 (MoCha) の結果を迅速に評価するためのサイドバイサイド比較をレンダリングします。
入力ビデオ
- “Input Video”にビデオをロードします。ワークフローはフレームを正規化し(デフォルト1280×720クロップ)、クリップのフレームレートを最終エクスポートのために自動的に保持します。初フレームは検査と下流マスキングのために公開されます。プレビューノードは生の入力フレームを表示し、クロップと露出を確認してから進めることができます。
初フレームマスク
- インタラクティブポイントエディターを使用して、俳優のポジティブポイントと背景のネガティブポイントをクリックします; SAM 2はこれらのクリックを正確なマスクに変換します。小さな成長とぼかしステップでマスクを拡大し、フレーム間のエッジハローと動きを防ぎます。結果として得られるマットはプレビューされ、同じマスクがMoCha埋め込みステージに送信されます。このグループでの良好なマスキングは、ビデオキャラクター置換 (MoCha) の安定性を実質的に向上させます。
ref1
- “ref1”はメインキャラクターのアイデンティティ画像です。ワークフローは背景を削除し、クロップを中央に配置し、ビデオの作業解像度に合わせてサイズを変更します。最良の結果を得るには、クリーンな背景の参照を使用し、初フレームのソース俳優におおよそ一致するポーズを取ることが推奨されます; MoChaエンコーダーは類似の視点とライティングから利益を得ます。
ref2 (オプション)
- “ref2”はオプションですが、顔のために推奨されます。ポートレートを直接提供するか、以下のサンプリングブランチで生成させることができます。画像はref1と同様に背景が削除され、リサイズされます。存在する場合、ref2は顔の特徴を強化し、動き、遮蔽、視点の変化中にアイデンティティが保持されるようにします。
ステップ1 - モデルのロード
- このグループは、Wan 2.1 VAEとWan 2.1 MoCha 14Bプレビューモデル、および蒸留のためのオプションのWanVideo LoRAをロードします。これらのアセットはメインのビデオサンプリングステージを駆動します。ここでのモデルセットはVRAMを多く消費します; 後で大きなシーケンスを適度なGPUに適合させるためのブロックスワップヘルパーが含まれています。
ステップ2 - 編集用画像のアップロード
- ref2を自身のスチルから作成する場合は、ここにドロップします。ブランチは画像をスケールし、Qwenエンコーダーにルーティングして条件付けします。すでに良い顔のポートレートがある場合、このブランチ全体をスキップできます。
ステップ4 - プロンプト
- 意図したクローズアップポートレートを説明する短いテキストキューを提供します(例えば、「次のシーン: カメラクローズアップフェイスショット、キャラクターのポートレート」)。Qwen-Image-Editはこれを使用してクリーンな顔画像を精製または合成し、それがref2になります。説明はシンプルに保ちます; これはアシストであり、完全なリスタイルではありません。
シーン2 - サンプリング
- QwenブランチはLightning LoRAの下で単一のポートレート画像を生成するクイックサンプラーを実行します。その画像はデコードされ、プレビューされ、軽い背景削除の後、ref2として転送されます。このステップは、コアなビデオキャラクター置換 (MoCha) の外観を変えずに顔の忠実度を向上させることが多いです。
Mocha
MochaEmbedsステージは、ソースビデオ、初フレームマスク、および参照画像をMoCha画像埋め込みにエンコードします。埋め込みはアイデンティティ、テクスチャ、局所的な外観の手がかりをキャプチャし、元の動きのパスを尊重します。ref2が存在する場合、それは顔の詳細を強化するために使用されます; そうでない場合、ref1のみがアイデンティティを担います。
Wanモデル
- Wanモデルローダーは、Wan 2.1 MoCha 14Bプレビューをメモリに取り込み、(オプションで)LoRAを適用します。ブロックスワップツールは、必要に応じて速度とメモリを交換できるように配線されています。このモデル選択は、ビデオキャラクター置換 (MoCha) の全体的なキャパシティと一貫性を設定します。
Wanサンプリング
- サンプラーは、Wanモデル、MoCha画像埋め込み、および任意のテキスト埋め込みを消費して編集された潜在フレームを生成し、それを画像にデコードします。2つの出力が生成されます: 最終的なスワップビデオと元のフレームとのサイドバイサイド比較です。フレームレートはローダーから渡されるため、動きのペースはソースと自動的に一致します。
ComfyUI用のビデオキャラクター置換 (MoCha) ワークフローの主要ノード#
MochaEmbeds(#302)。ソースクリップ、初フレームマスク、参照画像をMoCha画像埋め込みにエンコードし、アイデンティティと外観を操作します。ref1のポーズは初フレームに一致させ、ドリフトが見られる場合はref2を含めます。エッジがちらつく場合、埋め込み前にマスクを少し拡大して背景の漏れを防ぎます。Sam2Segmentation(#326)。ポジティブ/ネガティブクリックを初フレームマスクに変換します。髪や肩の周りのクリーンなエッジを優先し、近くの小道具を除外するためにいくつかのネガティブポイントを追加します。セグメンテーション後にマスクを少し拡大することで、俳優が動く際の安定性が向上します。WanVideoSampler(#314)。ビデオキャラクター置換 (MoCha) の重作業を担い、潜在をフレームにデノイズします。ステップ数を増やすことで詳細と時間的安定性が向上します; ステップを減らすことで反復速度が向上します。参照やマスクの変更を比較する際にはスケジューラーを一貫して保ちます。WanVideoSetBlockSwap(#344)。VRAMが不足している場合、より深いブロックスワッピングを有効にしてWan 2.1 MoCha 14Bパスを小さなGPUに適合させます。速度の損失が予想されます; その代わりに解像度とシーケンス長を保持できます。VHS_VideoCombine(#355)。最終的なMP4を書き込み、ワークフローメタデータを埋め込みます。ソースと同じフレームレートを使用し(すでに配線済み)、幅広いプレーヤー互換性のためにyuv420p出力を使用します。
オプションの追加機能#
- クリーンスワップのためのヒント
- プレーンな背景と初フレームに近いポーズのref1を使用します。
- アイデンティティを安定させるために、シャープで正面からの顔ポートレートとしてref2を保持します。
- エッジハローが見られる場合、初フレームマスクを拡大し、軽くぼかしてから再埋め込みします。
- 重いシーンではブロックスワップヘルパーが役立ちます; それ以外の場合は速度のためにオフにしておきます。
- ワークフローはA/B比較ビデオをレンダリングします; 変更を迅速に判断するために使用します。
- 便利な参照
- Orange-3DV-TeamによるMoCha: GitHub, Hugging Face
- Wan 2.1 MoCha 14B (Comfy形式): Kijai/WanVideo_comfy, Kijai/WanVideo_comfy_fp8_scaled
- Segment Anything 2: facebookresearch/segment-anything-2
- Qwen Image Edit + Lightning LoRA: Comfy-Org/Qwen-Image-Edit_ComfyUI, lightx2v/Qwen-Image-Lightning
謝辞#
このワークフローは、以下の作品とリソースを実装および構築しています。私たちは、Video Character Replacement (MoCha) のための“Video Character Replacement (MoCha)”のBenji’s AI Playgroundの貢献とメンテナンスに感謝します。権威ある詳細については、以下にリンクされた元のドキュメントとリポジトリを参照してください。
リソース#
- “Video Character Replacement (MoCha)”/Video Character Replacement (MoCha)の著者
- Docs / Release Notes @Benji’s AI Playground: YouTube video
注: 参照されたモデル、データセット、およびコードの使用json
