
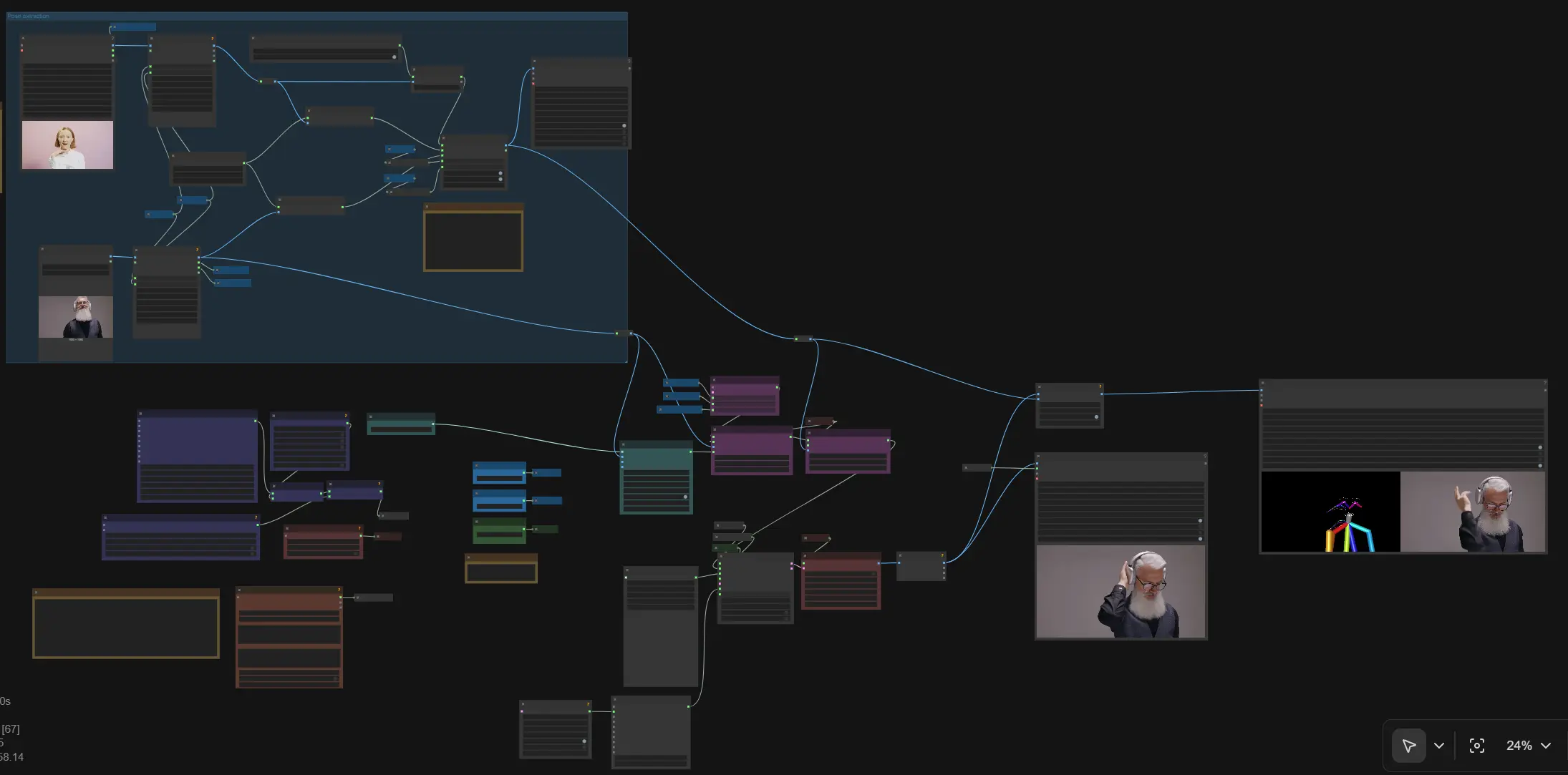
ComfyUIにおけるSCAILポーズ誘導キャラクターアニメーション#
このワークフローは、ポーズ誘導のリファレンスベースのキャラクターアニメーションをComfyUIにSCAILを導入します。単一のリファレンス画像と抽出された人間のポーズを組み合わせることで、SCAILはフレーム間での被写体のアイデンティティ、身体構造、および一貫した動きを維持しつつ、プロンプトでスタイルを制御できます。モーショントランスファーのための入力ビデオ、または振り付けのための画像とレンダリングされたポーズをサポートし、その後、オプションのオーディオパススルーを備えたマルチフレームビデオを出力します。
このSCAILワークフローを使用して、ダンスやアクションのモーショントランスファー、スタイライズドキャラクターアニメーション、および時間的安定性と正確なポーズが重要な一貫したマルチショットシーケンスを作成します。内部では、WanVideoを使用して拡散変換ビデオ生成を実行し、CLIPビジョンを介してアイデンティティを強化し、NLFおよびViTPose/DWPoseポーズ信号で構造を駆動し、効率的な長シーケンスサンプリングに配線されています。
注: 互換性の制限により、現在のComfyUIワークフローでは2XLマシンを使用できません。
ComfyUI SCAILワークフローの主要モデル#
- SCAIL: フルコンテキストのポーズインジェクションと3D一貫性のあるポーズ表現によるスタジオグレードのキャラクターアニメーション。このワークフローのアイデンティティ保持とポーズの忠実性の中核です。 GitHub, arXiv
- Wan 2.x Image-to-Videoバックボーン: SCAIL条件付き生成のサンプラーバックボーンとして使用される大規模なビデオ拡散モデル。高品質なI2Vおよびアニメーションタスクをサポートします。例: Wan-AI/Wan2.1-I2V-14B-480P, Wan-AI/Wan2.2-Animate-14B
- UMT5-XXLテキストエンコーダ: Wanパイプラインによってプロンプトを条件付け埋め込みに変換するために使用される多言語T5バリアント。 Hugging Face
- CLIP ViT-H/14ビジョンエンコーダ: ビデオ合成中にアイデンティティを固定するための堅牢なリファレンス画像特徴を抽出します。 GitHub
- ViTPose (Whole-Body): SCAILの整列および描画ユーティリティによって使用される身体、手、および顔の密なキーポイントを供給する高品質な2D人間ポーズ推定器。 GitHub
- DWPose: 顔/手の詳細およびポーズ整列のために活用される全身キーポイント形式とモデル。 GitHub
- NLF (Neural Localizer Fields): SCAILの3D対応ポーズ画像にレンダリングされる連続的な人間のポーズ/形状キューを予測します。 GitHub
- YOLOv10: 人物のローカリゼーションのためのポーズ前処理チェーンで使用される高速検出器。 GitHub
ComfyUI SCAILワークフローの使用方法#
全体の流れ: リファレンス画像とオプションの駆動ビデオをロードします。ポーズを抽出しレンダリングします。CLIPビジョンでリファレンスをエンコードします。SCAILリファレンスおよびSCAILポーズ埋め込みを追加します。テキスト条件付けを組み立てます。WanVideoでフレームをサンプリングします。ビデオをデコードしエクスポートします。グラフには、幅、高さ、CFG、フレーム数が自動的に伝播するようにパブリックな"Set_"変数が含まれています。
- 入力とサイズ
- リファレンスキャラクター画像、またはモーショントランスファーのためのビデオをロードします。ワークフローはリファレンスを生成サイズにリサイズし、ターゲット寸法が32で割り切れることを保証します。ビデオをロードする場合、そのオーディオは最終エクスポートへのパススルーが可能です。
- 幅、高さ、フレーム数を一度設定します。これらの値はサンプラー、デコーダ、エクスポーターに共有ゲッターおよびセッターを通じてフィードされます。リファレンスと出力のアスペクト比を一貫させ、歪みアーティファクトを最小限に抑えます。
- ポーズ抽出 (グループ: ポーズ抽出)
- 入力ビデオフレームまたは画像は分析のためにリサイズされ、NLFポーズ予測器とViTPose検出器にフィードされます。ViTPoseの出力は、オプションの顔/手の詳細およびリファレンス被写体へのグローバルポーズの整列のためにDWPose形式に変換されます。
- 内部的に生成解像度の半分の効率で生成されるSCAILポーズ画像をレンダリングし、ターゲットサイズに合成して、深度キューとオクルージョンを保持します。顔/手の描画は整列を使用しながら切り替えることができ、整列を無効にしたい場合はDWPoseを切断します。
- リファレンスアイデンティティエンコード
- リファレンス画像はCLIP ViT-H/14でエンコードされ、WanVideo画像埋め込みに変換されます。これらの埋め込みは色、テクスチャ、および局所構造をキャプチャし、SCAILが挑戦的な動きの中でキャラクターを一貫して保つことができます。
- 長いまたはスタイライズされたショットでアイデンティティがずれる場合は、クリーンで正面を向いたリファレンスを保持し、重いクロップを避けます。これにより、下流で使用されるCLIP信号が強化されます。
- SCAILポーズ条件付け
- SCAILポーズレンダリングは追加の画像埋め込みとして注入されます。これらはフレーム間での四肢の配置、深度の順序、シルエットの安定性を強制する強力な構造的ガイダンスとして機能します。
- この段階で駆動ソースを交換できます: ビデオから抽出されたポーズをモーショントランスファーに使用するか、ドライバーなしでシーケンスを振り付けるために事前にレンダリングされたSCAILポーズ画像を供給します。
- テキストプロンプト条件付け
- プロンプトはスタイル、衣装、照明、環境をバイアスするテキスト埋め込みにエンコードされます。リファレンス画像を補完する簡潔な説明を使用してください。ネガティブテキストは過飽和、アーティファクト、または混雑を減少させることができます。
- プロンプトは、SCAIL制御の下でリファレンスルックに忠実に出力をフォローしたい場合にオプションです。
- サンプリングとスケジューリング
- WanVideoサンプラーは、モデル、スケジューラー、画像埋め込み(リファレンス + SCAILポーズ)、テキスト埋め込み、およびCFGガイダンスを使用して拡散変換を実行します。コンテキストオプションノードは、長いシーケンスをメモリフレンドリーな生成のためにウィンドウ化しつつ、時間的連続性を保持します。
- フリッカーやソフトエッジが目立つ場合は、より遅いスケジューラーまたはわずかに強いCFGを検討してください。動きが過度に制約されていると感じた場合は、ガイダンスを全体的に減らして、SCAILの構造と外観のキューが自然にバランスをとるようにします。
- デコードとエクスポート
- ラテントはWan VAEを使用してフレームにデコードされ、選択したフレームレートとファイル名プレフィックスでビデオが書き出されます。ワークフローは、A/Bスライスのためにビジュアルを連結し、接続されている場合はオーディオを通過させることができます。
- 出力を確認します。急速なターン中に腕や脚がクリップされている場合は、ポーズ抽出の品質や整列入力を再確認し、同じシードで再キューして制御された反復を行います。
Comfyui SCAILワークフローの主要ノード#
WanVideoAddSCAILReferenceEmbeds(#350)- リファレンス画像からのアイデンティティと外観の条件付けを画像埋め込みストリームに追加します。キャラクターの顔や衣装がずれる場合はその影響を増やし、大きな体の回転や劇的な照明にモデルが適応しない場合は減らします。
WanVideoAddSCAILPoseEmbeds(#324)- レンダリングされたSCAILポーズ画像を構造的ガイダンスとして注入します。四肢の配置とシルエットの安定性を厳しくするためにその影響を高め、動きが硬すぎる場合やスタイルプロンプトがポーズをわずかに曲げる自由を望む場合は低くします。
RenderNLFPoses(#362)- 連続的なNLF予測をSCAILスタイルのポーズ画像にレンダリングし、オプションでDWPoseの顔/手をオーバーレイし、ポーズからリファレンスへの整列を行います。内部ポーズレンダリングをSCAILのデザインに合わせてターゲット解像度の半分に保ち、エイリアシングを避けます。整列を削除するにはDWPoseを切断します。
WanVideoSamplerv2(#348)- モデル、画像/テキスト埋め込み、スケジューラー、追加引数、および
cfgを使用して主な拡散サンプリングを駆動します。時間的な揺れが見られる場合は、より安定したスケジューラーまたはより多くのステップを使用します。リファレンスを超える詳細がある場合は、cfgを下げてSCAILのアイデンティティキューがリードするようにします。
- モデル、画像/テキスト埋め込み、スケジューラー、追加引数、および
WanVideoSchedulerv2(#349)- デノイズスケジュールの挙動を制御します。詳細と安定性のバランスをとるスケジュールを選択します。遅いスケジュールは、広範な動きや長いシーケンスの時間的一貫性を改善することがよくあります。
WanVideoClipVisionEncode(#327)- ViT-H/14でリファレンス画像をエンコードし、アイデンティティのためのCLIP画像埋め込みを出力します。高品質で良好に照らされたリファレンスを使用してください。正面または3/4ビューは顔と髪をよりよく固定する傾向があります。
オプションの追加#
- 寸法は32で割り切れる必要があります。リファレンスと出力のアスペクト比を一致させて歪みを避けます。
- SCAILは生成解像度の半分でのポーズレンダリングを期待します。このワークフローはそれを自動計算するので、手動で管理する必要はありません。
- 手や表情を正確にするために、DWPoseを接続して顔/手のキューを有効にします。整列のみを無効にするには、DWPoseリンクを切断しますが、レンダリングされたポーズ画像は保持します。
- 長いシーケンス: コンテキストオプションノードを使用して生成をウィンドウ化し、メモリ効率を向上させながらスムーズなトランジションのために重複を保持します。
- ComfyUIのために再パッケージ化されたSCAILプレビューウェイトを使用する場合、必要に応じてコミュニティ配布から取得します。例のプレビューパック: Kijai/WanVideo_comfy SCAILおよびKijai/WanVideo_comfy_fp8_scaled SCAIL。
謝辞#
このワークフローは、以下の作業とリソースを実装し、それに基づいて構築されています。SCAIL(公式実装)およびSCAILプロジェクトページのための貢献とメンテナンスに対して、Ai Verse Z.ai (zai-org) およびteal024に心より感謝します。詳細については、以下のリンクされたオリジナルのドキュメントおよびリポジトリを参照してください。
リソース#
- zai-org/SCAIL
- GitHub: zai-org/SCAIL
- Hugging Face: zai-org/SCAIL-Preview json
- arXiv: arXiv:2512.05905
- teal024/SCAIL Project Page
- Docs / Release Notes: Project Page
- GitHub: zai-org/SCAIL
- Hugging Face: zai-org/SCAIL-Preview
- arXiv: arXiv:2512.05905
注: 参照されているモデル、データセット、およびコードの使用は、それぞれの著者およびメンテナーによって提供されるライセンスおよび条件に従います。