





Omni Kontext image composition workflow for ComfyUI#
This workflow lets you add a subject into a new scene with strong identity and context preservation using Omni Kontext. It combines Flux Omni Kontext model patches with reference-guided conditioning so a provided character or product blends naturally into a target background while respecting your prompt. Two parallel paths are included: a standard Flux path for maximum fidelity and a Nunchaku path for faster, memory-friendly sampling with quantized weights.
Creators who want consistent brand assets, product swaps, or character placements will find this especially useful. You provide a clean subject image, a scene image, and a short prompt, and the graph handles context extraction, guidance, LoRA styling, and decoding to produce a coherent composite.
Key models in Comfyui Omni Kontext workflow#
- FLUX.1 Dev – The diffusion transformer backbone used for generation. It offers strong prompt adherence and modern sampler behavior suitable for context-aware composition. Model card
- Flux text encoders (CLIP-L and T5-XXL) – Paired encoders that tokenize and embed your text into conditioning suitable for FLUX. The workflow loads
clip_l.safetensorsandt5xxlvariants optimized for Flux. Encoders - Omni Kontext nodes – Custom nodes that patch the model and conditioning to inject context from your subject latent into the final guidance stream. Repository
- Nunchaku Flux DiT – Optional loader that supports FP16/BF16 and INT4 quantized FLUX weights for speed and lower VRAM while keeping quality competitive. Repository
- Lumina VAE – A robust VAE used to encode the subject and scene images and decode final outputs. The workflow references
ae.safetensorsfrom Lumina Image 2.0 repackaged. VAE
How to use Comfyui Omni Kontext workflow#
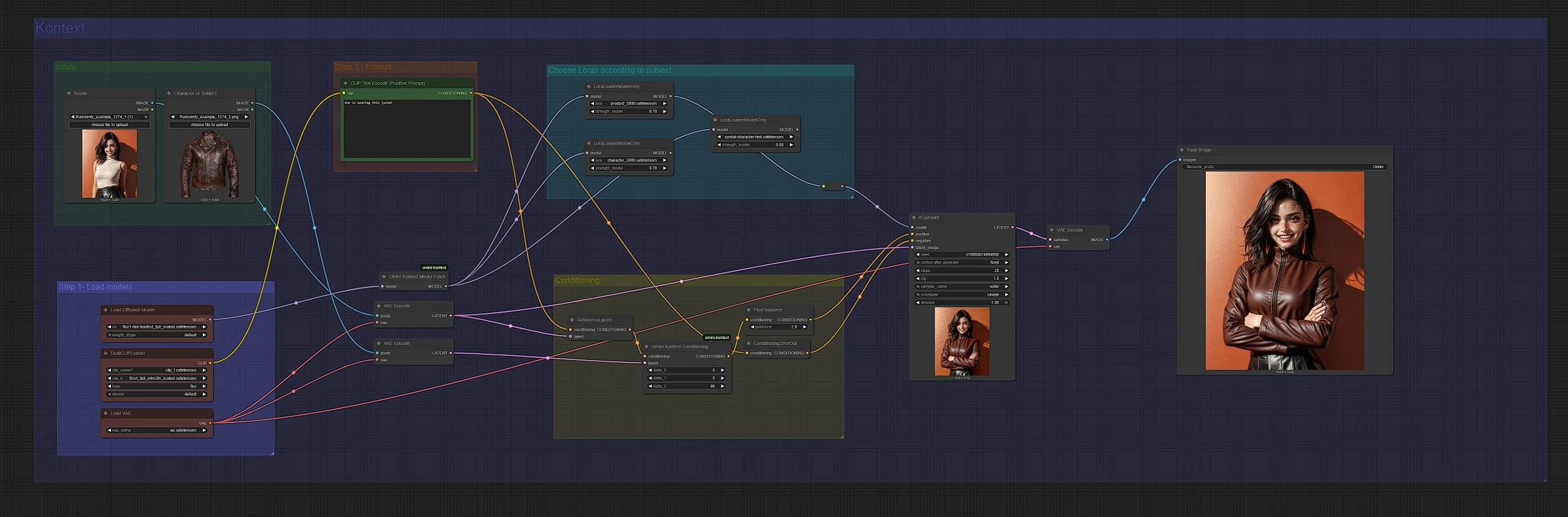
The graph has two mirrored lanes: the upper lane is the standard Flux Omni Kontext path, and the lower lane is the Nunchaku path. Both accept a subject image and a scene image, construct context-aware conditioning, and sample with Flux to produce the composite.
Inputs#
Provide two images: a clean subject shot and a target scene. The subject should be well lit, centered, and unobstructed to maximize identity transfer. The scene should roughly match your intended camera angle and lighting. Load them into the nodes labeled “Character or Subject” and “Scene,” then keep them consistent across runs while you iterate on prompts.
Load models#
The standard lane loads Flux with UNETLoader (#37) and applies the Omni Kontext model patch with OminiKontextModelPatch (#194). The Nunchaku lane loads a quantized Flux model with NunchakuFluxDiTLoader (#217) and applies NunchakuOminiKontextPatch (#216). Both lanes share the same text encoders via DualCLIPLoader (#38) and the same VAE via VAELoader (#39 or #204). If you plan on using LoRA styles or identities, keep them connected in this section so they affect the model weights before sampling.
Prompt#
Write concise prompts that tell the system what to do with the subject. In the upper lane, CLIP Text Encode (Positive Prompt) (#6) drives the insertion or styling, and in the lower lane CLIP Text Encode (Positive Prompt) (#210) plays the same role. Prompts like “add the character to the image” or “she is wearing this jacket” work well. Avoid overly long descriptions; keep it to the essentials you want changed or maintained.
Conditioning#
Each lane encodes the subject and scene to latents with VAEEncode, then fuses those latents with your text via ReferenceLatent and OminiKontextConditioning (#193 in the upper lane, #215 in the lower lane). This is the Omni Kontext step that injects meaningful identity and spatial cues from the reference into the conditioning stream. After that, FluxGuidance (#35 upper, #207 lower) sets how strongly the model follows the composite conditioning. Negative prompts are simplified with ConditioningZeroOut (#135, #202) so you can focus on what you want rather than what to avoid.
Choose Loras according to subject#
If your subject benefits from a LoRA, connect it before sampling. The standard lane uses LoraLoaderModelOnly (#201 and companions) and the Nunchaku lane uses NunchakuFluxLoraLoader (#219, #220, #221). Use subject LoRAs for identity or outfit consistency and style LoRAs for art direction. Keep strengths moderate to preserve the scene’s realism while still enforcing subject traits.
Nunchaku#
Turn to the Nunchaku group when you want faster iterations or have limited VRAM. The NunchakuFluxDiTLoader (#217) supports INT4 settings that cut memory substantially while keeping the “Flux Omni Kontext” behavior via NunchakuOminiKontextPatch (#216). You can still use the same prompts, inputs, and LoRAs, then sample with KSampler (#213) and decode with VAEDecode (#208) to save results.
Key nodes in Comfyui Omni Kontext workflow#
OminiKontextModelPatch (#194)#
Applies the Omni Kontext model modifications to the Flux backbone so reference context is honored during sampling. Leave it enabled whenever you want subject identity and spatial cues to carry into the generation. Pair with a moderate LoRA strength when using character or product LoRAs so the patch and LoRA do not compete.
OminiKontextConditioning (#193, #215)#
Merges your text conditioning with reference latents from subject and scene. If identity drifts, increase the emphasis on the subject reference; if the scene is being overruled, decrease it slightly. This node is the heart of Omni Kontext composition and generally needs only small nudges once your inputs are clean.
FluxGuidance (#35, #207)#
Controls how strictly the model follows the composite conditioning. Higher values push closer to prompt and reference at the cost of spontaneity; lower values allow more variety. If you see overbaked textures or loss of harmony with the scene, try a small reduction here.
NunchakuFluxDiTLoader (#217)#
Loads a quantized Flux DiT variant for speed and lower memory. Choose INT4 for quick looks and FP16 or BF16 for final quality. Combine with NunchakuFluxLoraLoader when you need LoRA support in the Nunchaku lane.
Optional extras#
- Use tight subject crops with clean backgrounds to improve identity capture during VAE encoding.
- Keep prompts short and concrete. Prefer “add the product to the table” over long style lists.
- If the subject looks pasted, lower LoRA strength a bit and reduce guidance slightly to let the scene reassert lighting and perspective.
- For speed rounds, iterate on the Nunchaku lane, then switch back to the standard Flux Omni Kontext lane for final renders.
- Save a few intermediate seeds that worked well so you can reuse them while refining LoRA strength and guidance.
Acknowledgements#
- Omni Kontext by Saquib764. This workflow adapts concepts and components from the project to enable Flux Omni Kontext composition in ComfyUI. Repository


