
Pose Control LipSync with Wan2.2 S2V:表現力豊かなアバターのための音声駆動・ポーズ制御画像-ビデオ変換#
Pose Control LipSync with Wan2.2 S2Vは、1枚の画像、オーディオクリップ、ポーズリファレンスビデオから同期されたトーキングパフォーマンスを生成します。リファレンス画像のキャラクターがリファレンスビデオの体の動きに従い、唇の動きはオーディオに一致します。このComfyUIワークフローは、ポーズ、表情、スピーチタイミングを緻密に制御したいアバター、ストーリーシーン、トレーラー、説明動画、ミュージックビデオに最適です。
Wan 2.2 S2V 14Bモデルファミリーをベースに構築され、テキストプロンプト、クリーンなボーカル特徴、ポーズマップを融合して、安定したアイデンティティでシネマティックなモーションを生成します。操作がシンプルでありながら、見た目、ペーシング、フレーミングの細かい制御をクリエイターに提供するよう設計されています。
ComfyUI Pose Control LipSync with Wan2.2 S2Vワークフローの主要モデル#
- Wan2.2‑S2V‑14B。静止画像とオーディオをビデオに変換するコアのスピーチ・トゥ・ビデオジェネレーター。モーションガイダンスのためのオプションのポーズコンディショニング付き。機能と使用上の注意については公式リポジトリとモデルカードを参照:Wan‑Video/Wan2.2およびWan‑AI/Wan2.2‑S2V‑14B。
- Wan VAE。Wanオートエンコーダーは高忠実度でビデオレイテントをエンコード・デコードし、Wan 2.xパイプライン全体で使用されます。リファレンス実装:Diffusersのドキュメント内のWanパイプライン。
- Google UMT5‑XXLテキストエンコーダー。Wanパイプライン内でハイレベルなシーンインテントとスタイルコントロールのための強力な多言語テキストコンディショニングを提供。モデルカード:google/umt5‑xxl。
- Facebook Wav2Vec2‑Large。リップシンクとマイクロ表情を駆動する堅牢な音声特徴を抽出。モデルカード:facebook/wav2vec2‑large‑960h。
- DWPose with YOLOXディテクター。リファレンスビデオから全身の動きをガイドする人体ポーズキーポイントとポーズマップを生成。リポジトリ:IDEA‑Research/DWPoseおよびMegvii‑BaseDetection/YOLOX。
- LightX2V LoRA for Wan。モーション品質を維持しながら低ステップのimage-to-videoスタイルのデノイジングを加速するための軽量LoRA。WanのDiffusersガイダンス:WanパイプラインでのLoRA使用を参照。
ComfyUI Pose Control LipSync with Wan2.2 S2Vワークフローの使い方#
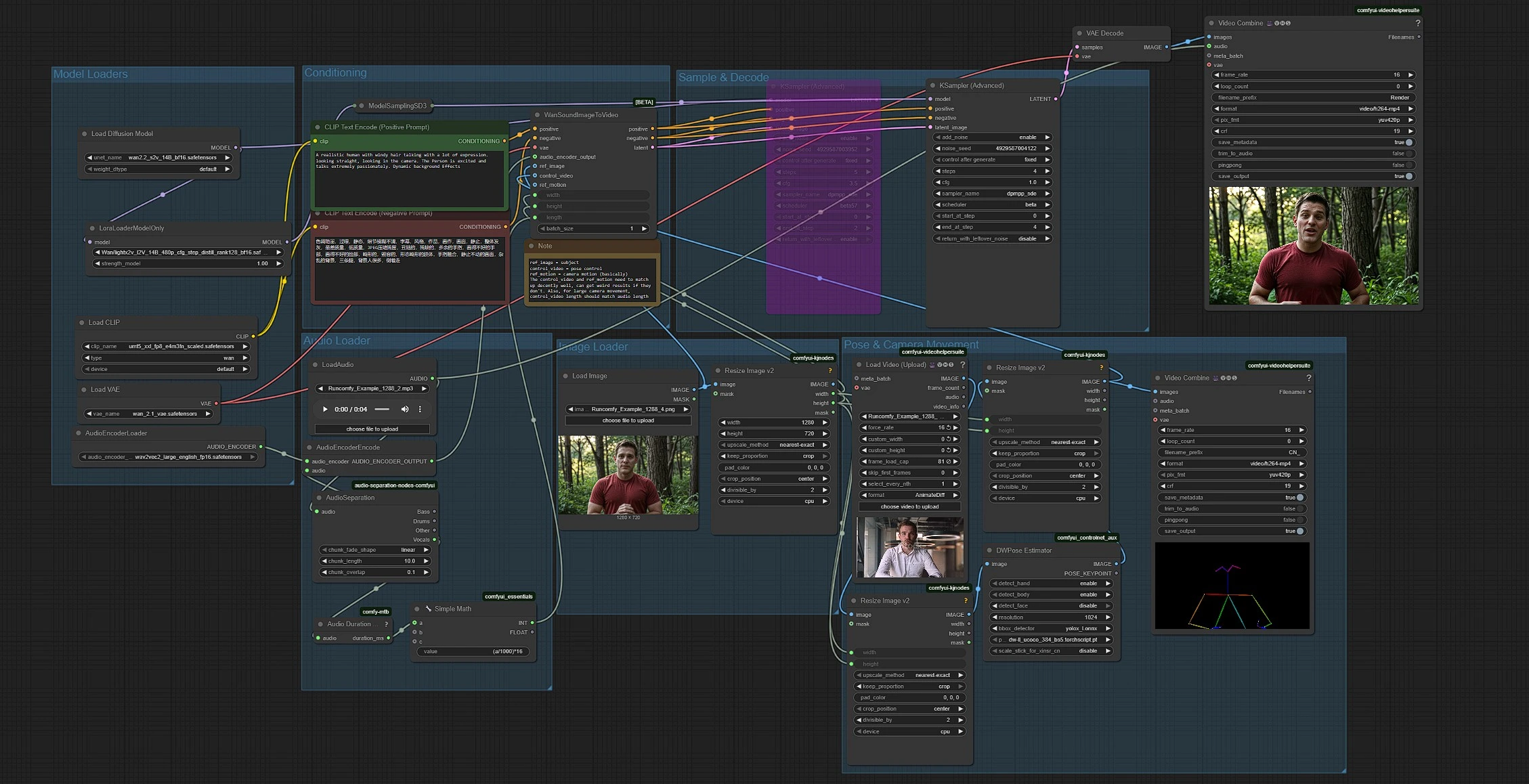
ワークフローは5つのパートを組み合わせます:モデルロード、オーディオ準備、画像とポーズ入力、コンディショニング、生成。グループは左から右のフローで実行され、オーディオの長さが16fpsでクリップのデュレーションを自動設定します。
Model Loaders#
このグループはWan 2.2 S2Vモデル、VAE、UMT5‑XXLテキストエンコーダー、LightX2V LoRAをロードします。ベーストランスフォーマーはUNETLoader (#37)で初期化され、LoraLoaderModelOnly (#61)で高速低ステップサンプリング用に適応されます。Wan VAEはVAELoader (#39)で提供されます。テキストエンコーダーはCLIPLoader (#38)によりWanが参照するUMT5‑XXLウェイトをロードします。モデルファイルを交換しない限り、このグループに触れる必要はほとんどありません。
Audio Loader#
LoadAudio (#58)でオーディオファイルをドロップします。AudioSeparation (#85)がボーカルステムを分離し、唇がバック楽器ではなくクリアな音声や歌に従うようにします。Audio Duration (mtb) (#70)がクリップを計測し、SimpleMath+ (#71)がデュレーションを16fpsのフレーム数に変換して、ビデオの長さがオーディオに一致するようにします。AudioEncoderEncode (#56)がWav2Vec2‑Largeエンコーダーに供給し、Wanが音素を口の形にマッピングして正確なリップシンクを実現します。
Image Loader#
LoadImage (#52)がアイデンティティ、衣装、カメラセットアップを持つ被写体のスチルを提供します。ImageResizeKJv2 (#69)が画像から寸法を読み取り、パイプラインが後続のすべてのステージで一貫してターゲットの幅と高さを導出します。最も忠実な唇の動きのために、口が遮られていない正面を向いたシャープな画像を使用してください。
Pose & Camera Movement#
VHS_LoadVideo (#80)がポーズリファレンスビデオをインポートします。ImageResizeKJv2 (#83)がフレームをターゲットサイズに適応し、DWPreprocessor (#78)がYOLOX検出とDWPoseキーポイントでポーズマップに変換します。最終的なImageResizeKJv2 (#81)が生成解像度にポーズフレームを揃えてからコントロールビデオとして渡されます。ポーズ出力をVHS_VideoCombine (#95)にルーティングしてプレビューでき、リファレンスのフレーミングとタイミングが被写体に合っていることを確認できます。
Conditioning#
CLIP Text Encode (Positive Prompt) (#6)にスタイルとシーンインテントを記述し、CLIP Text Encode (Negative Prompt) (#7)で不要なアーティファクトを抑制します。プロンプトはハイレベルなエステティクスとバックグラウンドモーションを操作し、オーディオが唇の動きを駆動し、ポーズリファレンスが身体のダイナミクスを制御します。ターゲットのカメラアングルとムードに合わせて簡潔なプロンプトを保ちましょう。
Sample & Decode#
WanSoundImageToVideo (#55)がテキスト、オーディオ特徴、リファレンス画像、ポーズコントロールビデオを融合し、レイテントシーケンスを準備します。KSamplerAdvanced (#64)がLightX2Vスタイルの加速に適した低ステップデノイジングを実行し、VAEDecode (#8)がフレームを再構成します。VHS_VideoCombine (#62)がフレームをMP4に組み立て、元のオーディオを添付して、すぐにレビューまたは編集できる出力を提供します。
ComfyUI Pose Control LipSync with Wan2.2 S2Vワークフローの主要ノード#
WanSoundImageToVideo (#55)#
プロンプト、ボーカル、被写体画像、ポーズコントロールビデオでWan2.2‑S2Vをコンディショニングするワークフローの中心部。重要なものだけ調整:width、height、lengthを被写体画像とオーディオの長さに合わせ、モーションコントロール用に前処理されたポーズビデオを接続します。別のカメラトラックを注入する予定がない限り、ref_motionは空のままにしてください。モデルのスピーチ・トゥ・ビデオ動作についてはWan‑AI/Wan2.2‑S2V‑14BおよびWan‑Video/Wan2.2を参照。
DWPreprocessor (#78)#
検出にYOLOX、全身キーポイントにDWPoseを使用してポーズマップを生成します。強いポーズキューはWanが四肢と胴体を追従するのを助け、オーディオが唇と表情を制御します。リファレンスに大きなカメラモーションがある場合は、意図したパフォーマンスに視点とタイミングを合わせたポーズビデオを使用してください。DWPoseとそのバリアントはIDEA‑Research/DWPoseで文書化されています。
KSamplerAdvanced (#64)#
レイテントシーケンスのデノイジングを実行します。LightX2V LoRAをロードすると、モーションの一貫性を保ちながら高速プレビューのためにステップを低く保てます。最大限のディテールを目指す場合はステップを増やしてください。スケジューラーの選択はモーションの滑らかさとシャープさに影響し、LoRA使用と一緒にDiffusersのドキュメントで概説されているように調整すべきです。
VHS_LoadVideo (#80)#
ポーズリファレンスをインポートしてスクラブします。ノード内のフレーム選択ツールを使用して、オーディオセグメントに一致する正確なセグメントを選択してください。フレーミングと被写体サイズをリファレンス画像と一致させるとモーション転送が安定します。このノードはVideoHelperSuiteの一部です:ComfyUI‑VideoHelperSuite。
VHS_VideoCombine (#62)#
生成されたフレームとオーディオをMP4に結合し、ワークフローメタデータを保存します。このワークフローでオーディオデュレーションから計算されたフレーム数に合わせて、出力フレームレートを16fpsに設定してください。アセット管理のニーズに応じて、メタデータの保存を有効または無効にしてください。VideoHelperSuiteのドキュメントはComfyUI‑VideoHelperSuiteを参照。
AudioSeparation (#85)#
ボーカルを分離して、Wav2Vec2の特徴が楽器やエフェクトの干渉なしに口の形を駆動するようにします。入力が既にクリーンなスピーチの場合は分離をバイパスできます。最良の結果のために、オーディオレベルを一定に保ち、リバーブを最小限にしてください。
オプションの追加機能#
- 最良のリップシンクのために、クリーンなスピーチまたはアカペラボーカルを推奨します。Wav2Vec2は16kHzで動作し、ほとんどのパイプラインは自動的にリサンプリングしますが、16kHzファイルを提供すると役立ちます。
- 歯と唇が見える、明るい照明の正面向き被写体画像を使用してください。遮蔽は精度を低下させます。
- ポーズリファレンスのフレーミングと動きを被写体に合わせてください。大きなカメラの動きは、ポーズビデオの長さがオーディオセグメントに一致する場合に最も効果的です。
- クイックイテレーションには480pで開始し、最終品質には720pに移行してください。Wan 2.2はS2Vで両方の解像度をサポートしています。
- プロンプトは短く、画像とポーズリファレンスのカメラセットアップと一致させて、競合を避けてください。
- LoRAを実験する場合は、Wan 2.2デノイザーと互換性があることを確認してください。Wan DiffusersのドキュメントのLoRAに関する注記を参照。
このPose Control LipSync with Wan2.2 S2Vワークフローは、オーディオと静止画像から、まとまりがあり表現力豊かに感じる制御可能なオンビートパフォーマンスへの高速パスを提供します。
謝辞#
このワークフローは以下の作品とリソースを実装・構築しています。Pose Control LipSync with Wan2.2 S2VDemoの@ArtOfficialLabsの貢献とメンテナンスに感謝いたします。正式な詳細については、以下にリンクされた元のドキュメントとリポジトリを参照してください。
リソース#
- YouTube/Pose Control LipSync with Wan2.2 S2VDemo
- @ArtOfficialLabsによるドキュメント/リリースノート:Pose Control LipSync with Wan2.2 S2VDemo
注意:参照されたモデル、データセット、コードの使用は、それぞれの著者およびメンテナーが提供する各ライセンスと利用規約に従います。