
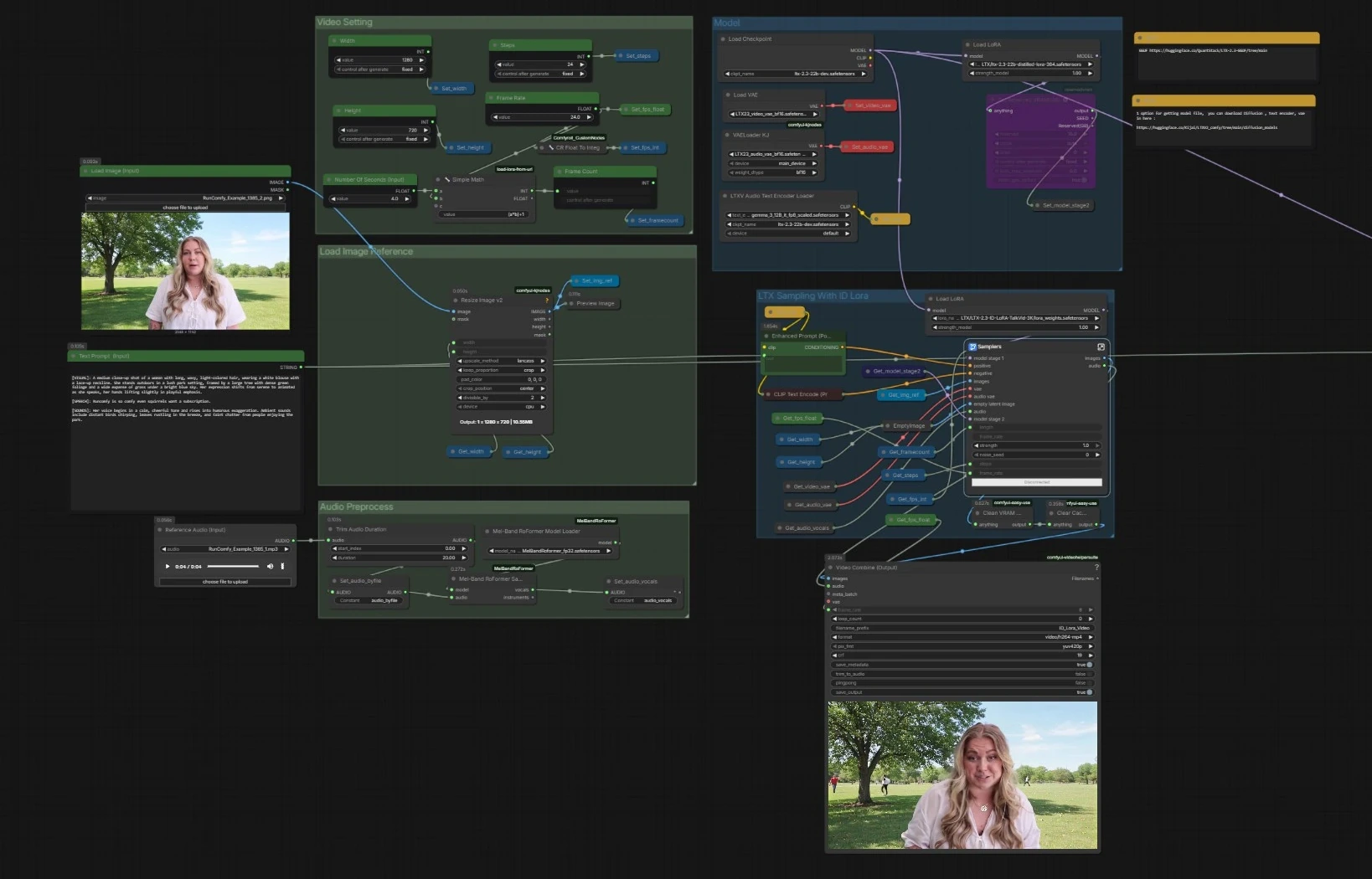
LTX 2.3 ID-LoRAトーキングビデオワークフロー for ComfyUI#
このワークフローは、1枚の顔画像、短い音声クリップ、プロンプトを完全に同期されたトーキングビデオに変換します。LTX-2.3に基づいて、音声とビジュアルを1つの拡散プロセスで融合させ、In-Context LoRAアイデンティティアダプターを追加して、参照画像の人物がすべてのフレームで一貫するようにします。LTX 2.3 ID-LoRAは、アバター、バーチャルホスト、およびリップシンク、類似性、プロンプト制御が1回で一致する必要がある任意のシナリオに最適です。
あなたが提供するのは3つ: 参照画像、1~2文の音声、ルックやパフォーマンスを説明するテキストプロンプト。LTX 2.3 ID-LoRAパスはアイデンティティを処理し、軽量な音声プリプロセッサが音声の明瞭さを強化して口の動きを強調します。結果は、アイデンティティを保持した一貫性のあるビデオで、同期されたスピーチがあり、被写体ごとのトレーニングを必要としません。
Comfyui LTX 2.3 ID-LoRAワークフローの主要モデル#
- Lightricks LTX-2.3 22Bベースチェックポイント。テキスト、画像、音声コンディショニングから同期されたフレームと音を生成するジョイント音声ビデオ基盤モデルです。このComfyUIパイプラインで使用されるコアジェネレーターです。Model card
- LTX-2.3蒸留LoRA 384。ベースモデルに蒸留されたガイダンスを適用して、サンプリングを安定化し速度を向上させる公式LoRAアダプターです。このワークフローの第2段階モデルとしてプラグインされます。LTX-2.3ページのチェックポイントテーブルを参照してください。Model card
- LTX-2.3空間アップスケーラーx2。サンプラーサブグラフ内で使用される潜在空間アップスケーラーで、デコード前に空間詳細を向上させ、最終ビデオの顔とエッジの忠実度を向上させます。Model card
- Gemma 3 12B指示テキストエンコーダー for LTX-2.3。スタイル、シーン、パフォーマンスを駆動するテキストコンディショニングを提供します。このワークフローは、ComfyUIでLTX-2用にパッケージされたGemma 3エンコーダーを使用しています。Comfy-Orgテキストエンコーダー
- LTX-2.3 VAE for ビデオと音声。モデルによって生成されたビジュアルおよび音響潜在を画像と波形にデコードするために設計されたVAEです。互換性のあるbf16ビルドはグラフ内で参照されています。例のソース: Video VAE · Audio VAE
- Mel-Band RoFormer for ボーカル分離。参照音声からクリーンなボーカルを抽出するオプションのプリプロセッサで、モデルが音節と口の形をより確実に追跡できるようにします。Paper · ComfyUI node
- LTX 2.3 ID-LoRA (IC-LoRA)。トーキングビデオ用に訓練されたインコンテキストアイデンティティLoRAで、参照画像の顔にジェネレーターをバイアスさせながらプロンプトと音声のキューを尊重します。Lightricksは、LTX-2.3でのLoRAおよびIC-LoRAの使用法をモデルページに記載しています。Model card
Comfyui LTX 2.3 ID-LoRAワークフローの使用方法#
全体の流れ。このパイプラインは、LTX-2.3ベースにテキストエンコーダーとVAEをロードし、画像と音声を準備した後、テキスト、顔参照、およびボーカルトラックを組み合わせて同期されたフレームとスピーチを生成する2段階のLTXサンプラーを実行します。ID-LoRAなしの並列サンプラーも含まれており、クイックな比較が可能です。最終フレームと音声はMP4にマルチプレックスされます。
- モデル
- グラフは、
CheckpointLoaderSimple(#5493)でベースチェックポイントを、LTXAVTextEncoderLoader(#5494)でGemmaベースのテキストエンコーダーを、ビデオ用VAELoader(#5651)と音声用VAELoaderKJ(#5649)を介して専用VAEをロードします。その後、公式の蒸留LoRAをステージ2モデルとして適用し、LoraLoaderModelOnly(#5573)を通してID-LoRAをアイデンティティコンディショニングに使用します。 - このステージは、ジェネレーターがプロンプトを理解し、適切なデコーディングスタックを持ち、効率ガイダンスとアイデンティティバイアスでプライムされていることを保証します。
- 一般的には、チェックポイントやLoRAを交換する以外には何も変更しません。
- グラフは、
- ビデオ設定
- 出力寸法、フレームレート、ステップ、長さを制御します。
Width(#5284)、Height(#5286)、およびFrame Rate(#5289)は、秒からの合計フレームを計算する小さなユーティリティにフィードされ、音声とビデオのタイミングを一貫して保ちます。 - 設定は一度保存され、すべての下流ノードによって読み取られるため、2つのサンプラーとマルチプレクサが整合性を保ちます。
- 異なるアスペクト、滑らかさ、または期間を望む場合は、まずこれらの値を調整してください。
- 出力寸法、フレームレート、ステップ、長さを制御します。
- 画像参照のロード
Load Image (Input)(#5525)を通じて1つのクリアな顔画像を提供します。選択した出力に合わせてImageResizeKJv2(#5280)で画像がリサイズされます。- この前処理された画像がLTX 2.3 ID-LoRAステージでのアイデンティティのアンカーとなり、類似性とショットコンポジションをガイドします。
- 最適な結果を得るには、よく照らされた、正面からの動きの少ない写真を使用してください。
- 音声のプリプロセス
Reference Audio (Input)(#5652)を使用して短いWAVまたはMP3をドロップします。必要に応じてクリップがトリムされ、その後MelBandRoFormerSampler(#5473)に渡されてボーカルが分離されます。- クリーンなボーカルは、モデルが音素とタイミングを推測し、正確な口の動きと話すリズムを得るのに役立ちます。
- 既に音声のみの場合、分離をスキップして直接フィードすることができます。
- ID Loraを使用したLTXサンプリング
- これは主要なパスです。サンプラーサブグラフ(
Samplers(#5278))は、Enhanced Prompt (Positive)(#5174)からのポジティブプロンプト、ネガティブリスト、顔参照、ボーカルトラックをLTX-2.3のAV潜在パイプラインを通じてブレンドします。 LTXVReferenceAudioは動作をスピーチと整合させ、LTXVImgToVideoInplaceは顔画像を潜在にアンカーとして注入します。LTX 2.3 ID-LoRAアダプターはジェネレーターを被写体のアイデンティティに向かわせます。- ステージには、デコード前に詳細を向上させる内部潜在アップスケーラーが含まれています。フレームと同期された音声ストリームを出力します。
- これは主要なパスです。サンプラーサブグラフ(
- ID LoraなしのLTXサンプリング
- 鏡像サンプラー(
Samplers(#5643))は、ID-LoRAアダプターなしで同じコンディショニングを実行します。A/Bチェックや参照アイデンティティからの自由度が必要な場合に使用します。 - 他のすべては同一であるため、気づく違いはアイデンティティコンディショニングによるものです。
- このパスはクイックドラフトやクリエイティブな逸脱に便利です。
- 鏡像サンプラー(
- ビデオの結合と出力
- フレームと生成された音声は
Video Combine (Output)(#5218)でMP4にマルチプレックスされます。フレームレートはグローバル設定から取得されるため、動きとリップシンクはサンプラーのタイミングに一致します。 - 2次
Video Combine(#5645)は、ID-LoRAなしのブランチを有効にした場合にプレビューします。比較に役立ちます。 - ワークフローは、長時間のセッションでVRAMを安定させるために、実行間でキャッシュをクリアします。
- フレームと生成された音声は
Comfyui LTX 2.3 ID-LoRAワークフローの主要ノード#
LoraLoaderModelOnly(#5573)- 顔のアイデンティティを保持するLTX 2.3 ID-LoRAをロードします。クリエイティブなバリエーションを望む場合はその重みを減らし、類似性をより厳密に固定したい場合は増やします。プロンプトの強さと慎重に組み合わせて、アイデンティティとスタイルが競合しないようにします。参考: LTX-2.3 LoRA使用法のモデルページ。Model card
LTXVReferenceAudio(#5589)- 参照音声を音節タイミング、プロソディ、口の形のコンディショニングに変換します。クリーンなスピーチをフィードして最良の整合性を得ます。ポンピングやオフビートの発音が聞こえる場合は、クリップを短くしたり単純化するのではなく、強度を上げます。
LTXVImgToVideoInplace(#5245、後でも使用)- 顔画像を潜在ビデオストリームに空間プライヤーとして注入します。画像強度コントロールは、写真への従属と動きの自由度をバランスします。強いアイデンティティと自然な動きを得るには、画像強度を中程度に保ち、ID-LoRAが類似性を担うようにします。
LTXVConditioning(#5621)- LTXサンプラーのためのテキストコンディショニングとタイミングキューをパッケージします。出力フレームレートと一致するフレームレート入力が、動きのフィールドと音素のタイミングの一貫性を保つことを確認します。
VHS_VideoCombine(#5218)- フレームと音声を最終ファイルにマルチプレックスします。音声がフレームよりわずかに長い場合は、ここでトリミングを有効にして、後に黒い尾を避けます。プラットフォームの互換性のため、変更する理由がない限り、デフォルトのH.264設定を保持してください。ノード参照: ComfyUI-VideoHelperSuite
MelBandRoFormerSampler(#5473)- Melバンドトランスフォーマーを使用して音楽からボーカルを分離し、ジェネレーターがスピーチにロックするようにします。シビラントがぼやけたり破裂音がポップしたりする場合は、同じファミリーの異なるモデルファイルを試すか、入力音量を下げます。背景読み物: arXiv
オプション追加#
- LTX-2.3で最も安定した生成を行うには、幅と高さを32で割り切れるようにし、Lightricksが文書化したようにフレーム数を8n + 1に選択します。Model card
- プロンプトと一致する参照画像を維持してください。屋外の照明を説明しているが室内の写真を供給する場合、アイデンティティは保持されるが、色とシェーディングがプロンプトと戦います。
- 2~8秒の自然なペースを持つ音声を与えてください。過度に圧縮されたクリップやリバーブのかかったクリップは、ボーカル分離後でもリップシンクの忠実度を低下させます。
- 顔がずれる場合は、画像強度をわずかに下げ、LTX 2.3 ID-LoRAにより依存させます。顔があまりにも移動する場合は、逆を行います。
- 長いテイクの場合は、同じシードとグローバル設定を共有するセグメントで生成し、必要に応じてビデオ編集でクリップを結合します。
参考文献と役立つリポジトリ#
- LTX-2.3のオープンウェイトとノート: Hugging Faceモデルページ
- LTXビデオ用の公式ComfyUIノード: [Lightricks/ComfyUI-LTXVideo](https://json
github.com/Lightricks/ComfyUI-LTXVideo)
- LTX‑2コードベースと論文: Lightricks/LTX‑Video · arXiv
- ComfyUIでのLTX用Gemma 3 12B ITエンコーダー: Comfy‑Org/ltx‑2 text_encoders
- Mel‑Band RoFormerの背景: arXiv
謝辞#
このワークフローは、以下の作品とリソースを実装および拡張しています。LTX 2.3 ID-LoRA Sourceのクリエイターの貢献とメンテナンスに感謝します。権威ある詳細については、以下のリンク先のオリジナルのドキュメントとリポジトリを参照してください。
リソース#
- LTX 2.3 ID-LoRA Source
- ドキュメント / リリースノート: YouTube @Benji’s AI Playground
注: 参照されているモデル、データセット、およびコードの使用は、それぞれの著者およびメンテナーによって提供されたライセンスおよび条件に従います。
