
LTX-2.3 ICLoRA LipDub for ComfyUI#
LTX-2.3 ICLoRA LipDubは、アイデンティティと動きを一貫して保ちながら、トーキングパーソンをダビングする、ビデオとオーディオ制御の2パスComfyUIワークフローです。それはLightricks LTX-2.3のテキストとビデオコンディショニングをLipDub IC-LoRAと組み合わせ、口の動きを供給されたスピーチに正確に合わせ、その後、より高い解像度で結果を洗練して詳細をクリアにします。グラフは、標準化された入力/出力名でRunComfy用に準備されており、メディアを交換して信頼性の高い実行を繰り返すことができます。
このComfyUI LTX-2.3 ICLoRA LipDubワークフローは、オリジナルのパフォーマンスを保持しながら、多言語のダビング、言い換え、またはADRのような修正を必要とするクリエイターに最適です。すでに対象のスピーチを含むソースビデオを提供し、シーンとその人が言うべきことを説明すると、ワークフローは同期したビジュアルとオーディオを合成して完成したクリップにします。
Comfyui LTX-2.3 ICLoRA LipDubワークフローの主要モデル#
- LTX-2.3 22Bベースビデオモデル。ビデオを生成し、プロンプトが外観、動き、スタイルをどのように誘導するかを管理する基盤の拡散モデル。
- LTX-2.3 IC-LoRA LipDub。リップダビングに特化したLoRAで、供給されたスピーチに従ってモデルを条件付けし、アイデンティティと頭の動きを保持しながら口の形を音素に合わせます。 Model card
- LTX-2.3 Audio VAE。入力スピーチをオーディオ潜在にエンコードし、後でテキストコンディショニングに注入して波形にデコードし、タイミングがフレームにロックされることを保証します。
- LTX-2.3 Spatial Upscaler x2。高解像度のリファインメントパスの前にビデオ潜在を高い空間解像度にアップスケールし、動きを変えずにテクスチャを向上させます。
- LTX-2.3 Distilled LoRA (384)。ベースチェックポイントとともに使用される強化LoRAで、リファレンスフレームへの過剰適合を防ぎつつ、詳細と時間的安定性を向上させます。
Comfyui LTX-2.3 ICLoRA LipDubワークフローの使用方法#
このワークフローは、オーディオにリップ形状をロックする低解像度パスと、同期を維持しながら詳細を洗練する高解像度パスの2つの調整されたステージで実行されます。すでに対象のスピーチを含むソースビデオをロードし、その人が言いたいテキストラインを書きます。
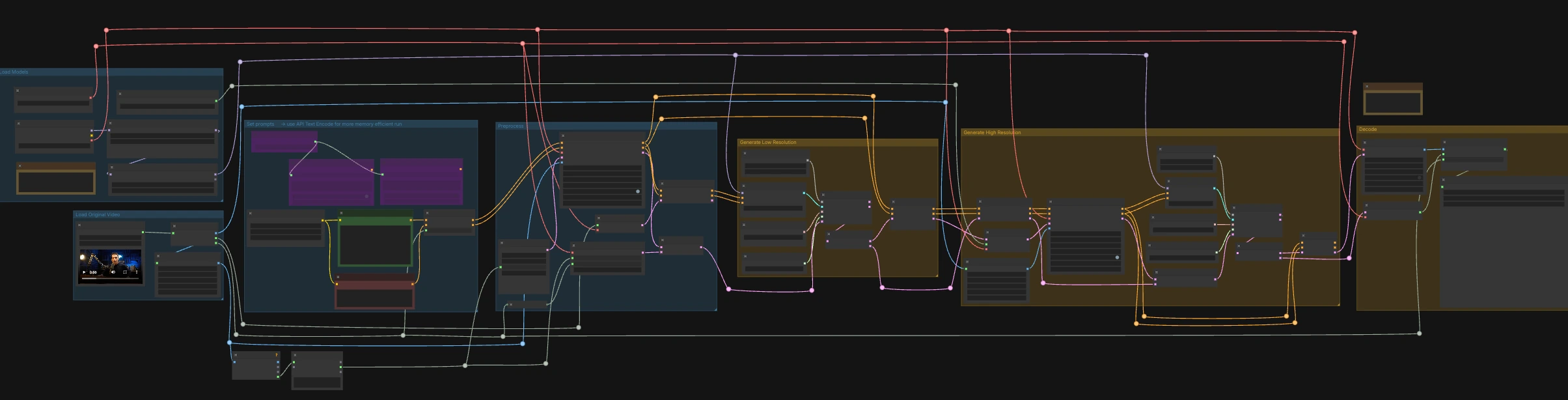
オリジナルビデオをロード#
LoadVideo (#5002)ノードは、埋め込まれたオーディオとともにソースクリップをインポートします。GetVideoComponents (#5010)はフレーム、オーディオ、フレームレートを抽出し、フレームレートはグラフ全体で共有されるため、ビデオとオーディオが整列します。2つのリサイズツール、Resize Image/Mask (s1 size) (#5009)とResize Image/Mask (s2 size) (#5003)は、低解像度と高解像度のパスのための作業イメージストリームを準備します。フレーム数は安定したデコードを保つために測定され、サンプラーに適した長さに丸められます。
モデルをロード#
CheckpointLoaderSimple (#5017)は、グラフ全体で使用されるLTX-2.3 22BベースモデルとVAEをロードします。2つのローダー、LoraLoaderModelOnly (#5018)とLTXICLoRALoaderModelOnly (#5012)は、ベースの上にディストールドLoRAとIC-LoRA LipDubを追加し、ジェネレーターがアイデンティティを保持しながらスピーチに従います。LTXVAudioVAELoader (#4010)は、サウンドトラックのエンコード/デコード用のオーディオVAEを提供します。IC-LoRAローダーのlatent_downscale_factor出力はここでは意図的に未使用です。LipDubトレーニングはフル解像度のリファレンスフレームを前提としており、含まれているノートに一致しています。
プロンプトを設定#
CLIP Text Encode (Positive Prompt) (#2483)にシーンの説明と正確な発話ラインを書きます。CLIP Text Encode (Negative Prompt) (#2612)を使用して、望ましくない特性やアーティファクトを最小限に抑えます。これらはLTXVConditioning (#1241)にフィードされ、ビデオ領域にコンディショニングを適応させ、フレームレートのコンテキストを前進させます。低VRAM実行のために、グラフにはAPIベースのエンコーダー(🅛🅣🅧 Gemma API Text Encode - POSITIVE (#4980)および... - NEGATIVE (#4981))が含まれていますが、LTX API KEY文字列 (#4979)によってゲートされており、デフォルトの配線はローカルエンコーダーを使用します。
前処理#
LTXVAudioVAEEncode (#5005)はソーススピーチをオーディオ潜在に変換し、LTXVSetAudioRefTokens (#5006)はその潜在をテキストコンディショニングに注入して、ジェネレーターがタイミングと音素を"聞く"ことを可能にします。EmptyLTXVLatentVideo (#3059)は、正しい空間サイズと入力に整列したフレーム数を持つプレースホルダービデオ潜在を準備します。LTXAddVideoICLoRAGuide (#5004)は、サンプリング前にs1フレームを使用してIC-LoRAリファレンスガイダンスを取り付け、アイデンティティと口の領域への注意を確立します。
低解像度の生成#
標準的な拡散ループは、CFGGuider (#4828)、KSamplerSelect (#4831)、ManualSigmas (#4984)、およびSamplerCustomAdvanced (#4829)によって形成されます。サンプラーは、LTXVConcatAVLatent (#4528)によって構成されたオーディオ+ビデオ潜在で動作し、オーディオコンディショニングがすべてのステップで参加することを保証します。サンプリング後、LTXVSeparateAVLatent (#4845)は潜在を分割し、LTXVSetAudioRefTokens (#5013)が高解像度パスのために同じスピーチ表現をフリーズできるようにします。このステージでは、リップ形状をスピーチにロックし、s1サイズでの動きのベースラインを設定します。
高解像度の生成#
LTXVLatentUpsampler (#4975)は、LTX-2.3 Spatial Upscaler x2を使用してビデオ潜在を持ち上げ、動きを保持しながら空間的な詳細に対応する容量を追加します。LTXAddVideoICLoRAGuide (#5014)は、s2フレームを使用して高解像度でIC-LoRAを再適用し、アイデンティティ、口の領域、および細かい特徴を強化します。2つ目の拡散ループ(CFGGuider (#4964)、KSamplerSelect (#4976)、ManualSigmas (#4985)、SamplerCustomAdvanced (#4971))がアップスケールされた潜在を洗練しながら、LTXVConcatAVLatent (#4969)が固定されたスピーチ潜在をロックステップで維持します。LTXVCropGuides (#5011, #5015)は安全なクロップと領域ガイドを管理し、顔が両方のパスで適切にフレーム内に収まるようにします。
デコード#
LTXVTiledVAEDecode (#4995)は、VRAM効率のためにタイルを使用して最終的なビデオ潜在を画像に変換し、LTXVAudioVAEDecode (#4848)は同期したオーディオを返します。CreateVideo (#4849)はフレームとオーディオをオリジナルのフレームレートで組み立て、SaveVideo (#4852)は事前入力されたRunComfy名でファイルを書き込みます。この値を変更して、出力をブランド化します。その結果、完全に同期されたLTX-2.3 ICLoRA LipDubクリップがレビューまたは配信の準備が整います。
Comfyui LTX-2.3 ICLoRA LipDubワークフローの主要ノード#
LTXICLoRALoaderModelOnly (#5012)#
LipDub IC-LoRAをロードし、ベースモデルにアタッチして、リップの動きが入力スピーチに従うようにします。より強いまたは微妙なリップコントロールが必要な場合は、ここでLoRAの重みを調整してください。スタック内で追加のLoRAを適用する場合は、過剰な条件付けを避けるために調整を維持してください。
LTXAddVideoICLoRAGuide (#5004)#
ダウンスケールされたリファレンスフレームを使用して低解像度ステージでIC-LoRAガイダンスを適用します。ここでワークフローは最初にアイデンティティと口の領域への注意をロックします。リファレンスガイダンスのタイミングと発音への影響を見るためにガイドを切り替えてA/Bテストを行います。
LTXAddVideoICLoRAGuide (#5014)#
高解像度でs2フレームを使用してIC-LoRAガイダンスを再適用し、洗練されたパスが同じ話者のアイデンティティと正確なリップ形状を保持します。高解像度のフレームサイズを変更する場合は、このノードを再訪して、ターゲット出力にリファレンスガイドを一貫させます。
LTXVSetAudioRefTokens (#5006)#
エンコードされたスピーチをテキストコンディショニングにバインドし、サンプラーが視覚素片と音素を整合させます。安定した結果を得るために、同じオーディオ潜在をパス全体で使用します。このグラフはそれを自動的に処理しますが、実行中にオーディオを交換する場合は、コンディショニングと連結された潜在の両方を更新する必要があります。
LTXVLatentUpsampler (#4975)#
LTX-2.3 Spatial Upscaler x2を使用してビデオ潜在をアップスケールし、高解像度サンプラーの前に細部を追加します。VRAMが厳しい場合は、s2の寸法を小さくしたり、デコーダーでのタイルを軽くして、品質とスループットのバランスを取ります。
LTXVTiledVAEDecode (#4995)#
タイルを使用して最終潜在をフレームにデコードし、大きな出力を制限されたGPUに適合させます。タイル数とオーバーラップを調整して、速度とメモリフットプリントを交換します。タイルが少ないほど速くなりますが、より多くのVRAMが必要です。タイルが多いほどVRAMを減らしますが、時間がかかります。
オプションのエクストラ#
- ダビング用のプロンプト:話したい正確な言葉を含めます。モデルは自動的に翻訳しません。ターゲット言語のネイティブスクリプトを使用し、単一の話者にとどまり、元のラインと同様の長さを目指してペーシングが自然に保たれるようにします。
- パフォーマンスのヒント:VRAMの制限に達した場合、
Resize Image/Mask (s2 size)(#5003)でs2のリサイズを減らし、LTXVTiledVAEDecode(#4995)でタイルを増やします。再現性を保つために、両方のパスでRandomNoiseシードを固定します。 - ワークフローのデフォルト:例の入力ファイル名は
LoadVideo(#5002)で事前入力されており、セーバーは一貫した出力名を設定します。結果を上書きせずに複数のLTX-2.3 ICLoRA LipDubをバッチ処理するために、両方を置き換えます。 - フレーミング:顔が端に近づく場合、
LTXVCropGuides(#5011, #5015)を調整して、口の領域が両方のパスで安定したクロップ内に収まるようにします。
謝辞#
このワークフローは、以下の作品とリソースを実装し、それに基づいて構築されています。LightricksによるLTX-2.3-22b-IC-LoRA-LipDubモデルおよびRunComfyによる共有ComfyUIワークフロー(Cloud Save source)に感謝し、彼らの貢献とメンテナンスに感謝します。権威ある詳細については、以下にリンクされているオリジナルのドキュメントとリポジトリを参照してください。
リソース#
- Lightricks/LTX-2.3-22b-IC-LoRA-LipDub
- GitHub: Lightricks/LTX-2
- Hugging Face: Lightricks/LTX-2.3-22b-IC-LoRA-LipDub
- arXiv: [arXivjson
:2601.22143](https://arxiv.org/abs/2601.22143)
- RunComfy/Cloud Save source
- Docs / Release Notes: RunComfy shared workflow
Note: Use of the referenced models, datasets, and code is subject to the respective licenses and terms provided by their authors and maintainers.
