
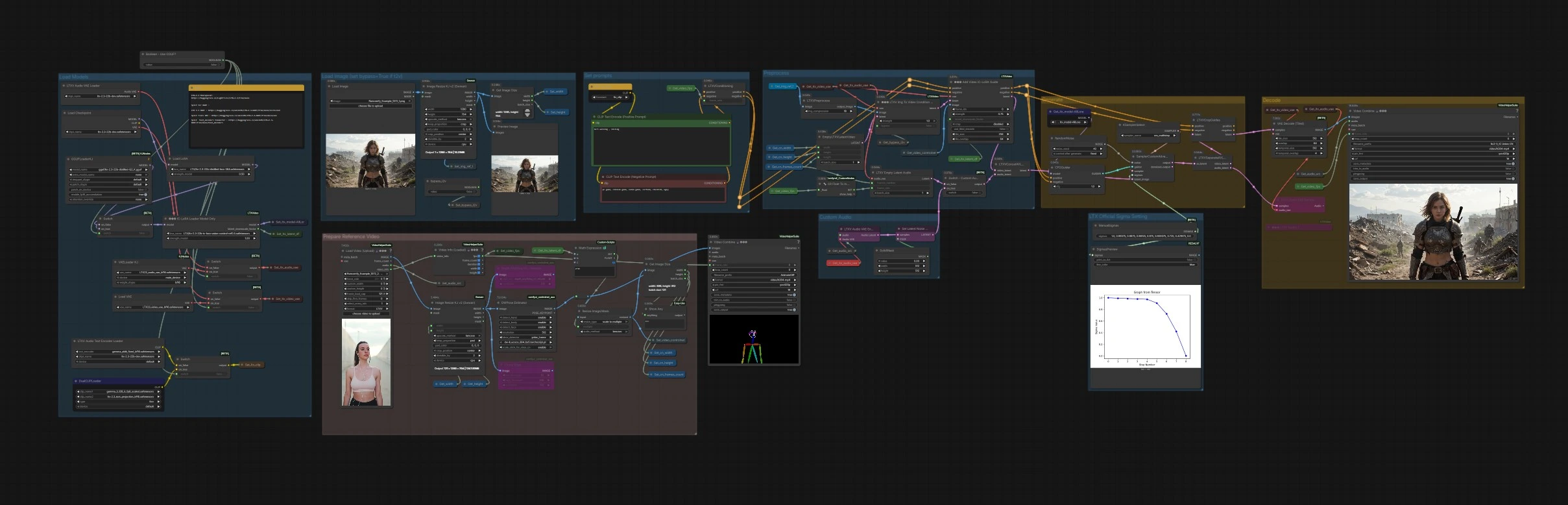
LTX 2.3 IC-LoRA: ComfyUIでのモーショントラックビデオ生成#
このワークフローは、LTX 2.3 IC-LoRAシステムをComfyUIに導入し、プロンプトや追加のLoRAsを使用して自由にスタイリングしながら、モーションとシーン構造をガイドできます。LTX-2.3ビデオジェネレーターを深度、ポーズ、エッジなどの参照信号で条件付けし、モーション転送、カメラ固定、予測可能な構成を可能にします。
ビデオからビデオへの変換、モーションリターゲティング、制御されたAIアニメーションに取り組むクリエイターは、LTX 2.3 IC-LoRAがモーション制御を視覚スタイルから分離することを発見します。テキストとスタイルLoRAsで外観を操作し、構造化されたガイドで動きを操作し、すべてを単一のComfyUIグラフ内で行います。
Comfyui LTX 2.3 IC-LoRAワークフローの主要モデル#
- LTX-2.3 by Lightricks。時間的一貫性のあるシーケンスを生成し、構造とモーション制御のための条件付けをサポートする高忠実度の潜在ビデオ拡散トランスフォーマー。 Hugging Face: Lightricks/LTX-2.3
- LTX 2.3 IC-LoRA統合制御ウェイト。LTX-2.3に構造化されたガイダンス信号を注入するために設計されたインコンテキストLoRAウェイト。ワークフローのモデルチェーンと一緒に提供され、生成前にロードされます。
- LTX-2.3 VAEs for video and audio。サンプリング中に使用されるビデオとオーディオの特徴を圧縮および再構築するためにLTX-2.3とペアリングされた潜在エンコーダー/デコーダー。グラフに事前設定され、量子化されたビルドを使用するときに切り替え可能です。スプリットパッケージの例はここで利用可能です: Hugging Face: unsloth/LTX-2.3-GGUF
- Depth Anything V2。生成中にカメラの動きを固定したり、シーンのレイアウトを保持したりするために使用される堅牢な単眼深度推定。 Hugging Face: LiheYoung/Depth-Anything-V2
- DWPose。キー ポイントを使用してキャラクターの動きをリターゲットまたは保持するために使用される軽量のマルチパーソンポーズエスティメーター。 Hugging Face: yzd-v/DWPose
Comfyui LTX 2.3 IC-LoRAワークフローの使用方法#
グラフは明確なグループに整理されています。プロンプトと参照ビデオを準備し、1つ以上の構造ガイドを選択してから生成してエクスポートします。
プロンプトを設定する#
CLIP Text Encode (Positive Prompt) (#2483) と CLIP Text Encode (Negative Prompt) (#2612) を使用して、視覚スタイルを説明し、不要な特性を除外します。テキストエンコーダーはモデルグループでロードされ、LTXVConditioning (#1241) にルーティングされ、作業フレームレートも受信して、コンディショニングがクリップのタイミングと一致するようにします。プロンプトは外観に焦点を当ててください。LTX 2.3 IC-LoRAがモーションと構造を処理します。
前処理#
参照クリップを VHS_LoadVideo (#5182) にロードまたは渡します。フレームは ImageResizeKJv2 (#5080) でリサイズされ、ガイド抽出器に供給されます: 深度用の DepthAnythingV2Preprocessor (#5064)、ポーズ用の DWPreprocessor (#4986)、エッジ用の CannyEdgePreprocessor (#4991)。下流のリサイズノードは、ガイドマップがモデルに優しい倍数と一致することを確認し、GetImageSize (#5029) は幅、高さ、フレーム数をパイプラインの残りの部分のために記録します。生成されたガイド画像シーケンスは、IC-LoRAが消費するために Set_video_controlnet (#5100) によって保存されます。
モデルをロードする#
基本モデルとLoRAsはこのグループで組み立てられます。CheckpointLoaderSimple (#3940) はLTX-2.3をロードし、LoraLoaderModelOnly (#4922) は品質と速度のために蒸留されたLTX LoRAを適用します。LTXICLoRALoaderModelOnly (#5011) はLTX 2.3 IC-LoRAのウェイトを追加し、必要な潜在的なダウンスケールファクターを公開します。ビデオとオーディオのためのVAEsがロードされ、Boolean - Use GGUF? (#5158) は GGUFLoaderKJ (#5150) を介して互換性のあるテキストエンコーダーとVAEsと共に量子化されたGGUFビルドに切り替えることができ、VRAMが制約されている場合に使用します。
画像をロードする (t2vの場合はbypass=Trueを設定)#
静止画像または最初のフレームで構成を固定したい場合は、LoadImage (#2004) を使用します。ImageResizeKJv2 (#5076) によってリサイズされ、迅速なチェックのためにプレビューされます。ブール値 bypass_i2v は画像が使用されるかどうかを制御します。LTX 2.3 IC-LoRAでの純粋なテキストからビデオへの変換にはTrueに設定します。
生成#
EmptyLTXVLatentVideo (#3059) は潜在キャンバスを作成します。画像の固定が有効になっている場合、LTXVImgToVideoConditionOnly (#3159) はスタイルを焼き込まずに画像からの構造情報のみを注入します。コアステップは LTXAddVideoICLoRAGuide (#5012) で発生し、選択したガイドシーケンスをIC-LoRAローダーからの潜在ダウンスケールファクターを使用してモデルにアタッチします。オーディオコンディショニングも LTXVEmptyLatentAudio (#3980) またはカスタムオーディオパスを介して潜在に流れ込みます。CFGGuider (#4828)、KSamplerSelect (#4831)、ManualSigmas (#5025)、および SamplerCustomAdvanced (#4829) は、最終的な潜在ビデオを合成するためにノイズを除去し、プロンプトとLTX 2.3 IC-LoRAの制御を尊重します。
デコード#
LTXVSeparateAVLatent (#4845) は生成されたオーディオとビデオの潜在をデコード用に分割します。LTXVCropGuides (#5013) は必要に応じて整列およびクロップし、VAEDecodeTiled (#4851) はフレームを効率的に再構築します。VHS_VideoCombine (#5070) はデフォルトで参照クリップのオーディオを使用してMP4にフレームを多重化します。生成されたオーディオ潜在を個別に試聴したい場合は、LTXVAudioVAEDecode (#4848) でデコードします。
参照ビデオを準備する#
このヘルパーエリアは参照フレームパイプラインを示しています。VHS_VideoInfoLoaded (#5073) はfpsと持続時間を抽出し、コンディショニングノードおよびエクスポーターに伝播してタイミングが同期するようにします。小さな結合ノードは、ソースシーケンスの簡単な視覚プレビューを提供し、正気チェックを行います。
カスタムオーディオ#
オーディオ認識の生成を希望する場合、参照オーディオは LTXVAudioVAEEncode (#5146) でエンコードされ、シンプルなマスクが SetLatentNoiseMask (#5148) で適用されます。Switch - Custom Audio? (#5149) というスイッチは、空のオーディオ潜在またはエンコードされたオーディオ潜在のいずれかを選択し、LTXVConcatAVLatent (#4528) で連結します。最終的なエクスポートはデフォルトで参照オーディオを使用します。モデルからデコードされたオーディオを好む場合は、LTXVAudioVAEDecode の出力をエクスポーターのオーディオ入力にルートします。
LTX公式シグマ設定#
スケジュールノード ManualSigmas (#5025) はLTX-2.3に最適化された簡潔なシグマプロファイルを定義し、SigmasPreview (#5142) は時間経過によるノイズ分配を合理的に考えることができるように視覚化します。これにより、LTX 2.3 IC-LoRAの特徴的な時間的安定性を維持しながら、速度とディテールを交換できます。
Comfyui LTX 2.3 IC-LoRAワークフローの主要ノード#
LTXICLoRALoaderModelOnly(#5011)。LTX 2.3 IC-LoRAのウェイトをロードし、ガイドインジェクターが必要とする潜在ダウンスケールファクターを出力します。追加のスタイルLoRAsを追加する場合は、モーションガイダンスを優先するためにこのローダーの前に配置します。LTXAddVideoICLoRAGuide(#5012)。深度、ポーズ、エッジシーケンスがインコンテキストガイダンスとしてモデルに入るポイントです。その強度を調整して、プロンプトとスタイルLoRAsからのスタイリスティックな自由を保ちながら、厳密な構造的遵守をバランスします。LTXVImgToVideoConditionOnly(#3159)。静止画像からの構成と粗い構造のみを転送するオプションの画像からビデオへの条件付けを提供します。i2vと純粋なテキストからビデオへの切り替え時にそのbypassトグルを使用します。CFGGuider(#4828)。LTX 2.3 IC-LoRAガイドに対してモデルがプロンプトをどれだけ強くフォローするかを制御します。スタイルの忠実性が最も重要な場合はガイダンスを増やし、モーションとジオメトリを最小限のドリフトで保持するにはガイダンスを減らします。SamplerCustomAdvanced(#4829) とManualSigmas(#5025)。LTX-2.3のための良好な時間的一貫性を提供するコンパクトなスケジュールとマルチステップサンプラーのペアリング。スケジュールを変更する場合は、滑らかに減少させ、長いレンダリングの前に短いクリップをテストします。
オプションのエクストラ#
- 適切なガイドを選択します。カメラとレイアウトをロックするには深度を使用し、キャラクターの動きにはポーズを、剛体オブジェクトやクリーンなシルエットにはエッジを使用します。異なる側面を説明する場合、2つのガイドを混ぜることも可能です。
- サンプラーに優しい寸法を維持します。前処理器はすでにモデルに優しい倍数にサイズを丸めています。ソースをターゲットのアスペクト比に近づけてパディングを最小限に抑えます。
- モーションを壊さずにスタイルを追加します。IC-LoRAローダーの前に軽いスタイルLoRAを追加し、その重みを適度に保ってLTX 2.3 IC-LoRAがジオメトリとタイミングを維持できるようにします。
- 低VRAMモード。Use GGUFをトグルして、GPUが制約されている場合に、GGUFパッケージから量子化された蒸留モデルと一致するテキストエンコーダー/VAEsを使用します。 Hugging Face: unsloth/LTX-2.3-GGUF
- 安定したタイミング。参照ビデオから読み取られたフレームレートは、コンディショニングとエクスポーターに注入されるため、モーションとオーディオが整合します。fpsを上書きする場合は、コンディショニングとエクスポート全体で一貫して行います。
謝辞#
このワークフローは、以下の作品とリソースを実装および構築しています。LTX 2.3 IC-LoRA Sourceの@Benji’s AI Playgroundから提供されたソースマテリアルとガイダンスに心から感謝します。権威ある詳細については、以下にリンクされた元のドキュメントとリポジトリを参照してください。
リソース#
- LTX 2.3 IC-LoRA Source
- ドキュメント / リリースノート: YouTube @Benji’s AI Playground
注: 参照されたモデル、データセット、およびコードの使用は、それぞれの著者および管理者によって提供されたライセンスおよび条件に従います。
