
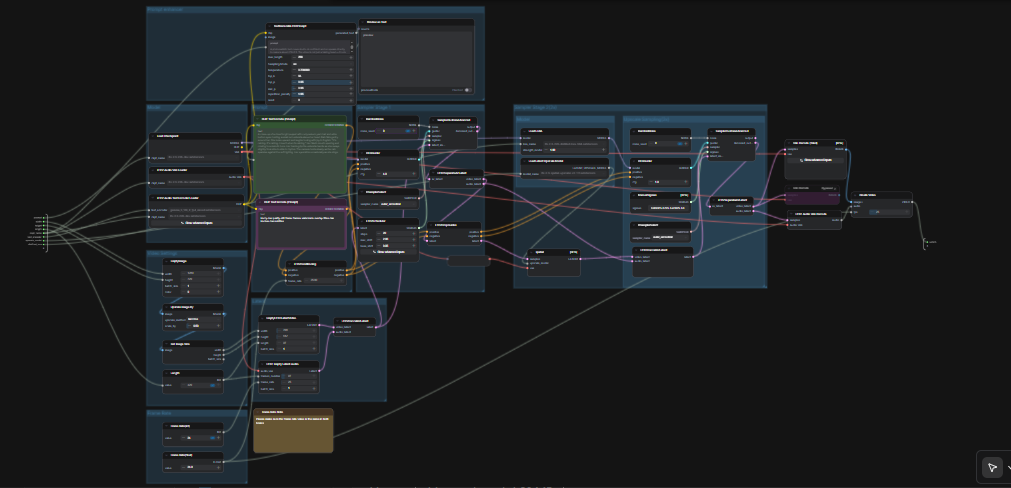
LTX 2.3 ComfyUI: テキストからビデオへの変換、クリーンなオーディオ、2段階のサンプリング、2×空間アップスケーリング#
このLTX 2.3 ComfyUIワークフローは、短いプロンプトを洗練されたシネマティックビデオに変換し、同期されたオーディオを提供します。LightricksのLTX-2.3モデルを中心に構築されており、高い視覚的一貫性、安定したモーション、および放送に適した出力に設定されています。クリエイター、編集者、テクニカルアーティストは、単一のプロンプトからMP4をオーディオ付きでワンパスで生成できます。プロンプトエンハンサー、2つのサンプリングステージ、および2×潜在アップスケーラーを含む合理化されたグラフを使用しています。
一般的なテキストからビデオへのセットアップと比較して、このグラフはシーンの一貫性とプロンプトの忠実性を強調しています。デフォルトのパスはAV潜在を生成し、潜在空間でアップスケールしてシャープなディテールを提供し、フレームとオーディオにデコードしてから、共有準備が整ったビデオファイルにパッケージ化します。最新のオープンソースビデオモデルを探索している場合、このLTX 2.3 ComfyUIワークフローはプロダクション品質のモーションを迅速に取得する方法です。
Comfyui LTX 2.3 ComfyUIワークフローの主要モデル#
- LTX-2.3 22B (dev) チェックポイント by Lightricks。高いコヒーレンスのモーションと強いシーンの一貫性を生み出すコアテキストからビデオへのモデルです。 Hugging Face • GitHub
- Gemma 3 12B Instructテキストエンコーダー (FP4 mixed)。より良いプロンプトグラウンディングと豊かなシーンディテールのための堅牢な言語理解を提供します。 Hugging Face
- LTX-2.3 Spatial Upscaler x2 1.0。モーションの一貫性を損なうことなく空間ディテールをシャープにする潜在空間アップスケーラーです。 Hugging Face
- LTX-2.3 22B Distilled LoRA (384)。テクスチャの忠実性を強化し、アップスケール/リファインステージ中のスタイルを安定させる蒸留アダプターです。 Hugging Face
- LTX Audio VAE。LTX-2.3とペアになっているオーディオモジュールで、同じプロンプトからクリーンで同期されたサウンド生成を可能にします。 Hugging Face
Comfyui LTX 2.3 ComfyUIワークフローの使用方法#
グラフは2つの調整されたパスで動作します。最初にプロンプトで作業解像度のAV潜在を生成します。次に2×潜在アップスケールを実行し、蒸留されたLoRAで2回目のサンプリングパスを行い、最終的にフレームとオーディオにデコードし、MP4にマクシングします。
プロンプトエンハンサー#
TextGenerateLTX2Prompt (#149) ノードは、単純な言語をモデルに適したプロンプトに書き換え、アクション、ビジュアル、およびオーディオキューをカバーします。シーンの説明を入力してください。スタイルやフレーミングのガイダンスが必要な場合は、オプションの参照画像を接続できます。生成されたテキストはポジティブエンコーダーにルーティングされ、品質重視のネガティブプロンプトがアーティファクトを抑えます。このバランスにより、LTX-2.3モデルがクリエイティビティを制約しすぎることなく、ブリーフに沿ったままになります。
モデル#
CheckpointLoaderSimple (#146) はLTX-2.3 22Bチェックポイントをロードし、モデルとそのVAEを公開します。LTXAVTextEncoderLoader (#147) は、ワークフローでポジティブおよびネガティブコンディショニングの両方に使用されるGemma 3 12B Instructテキストエンコーダーを取り込みます。他のLTXバリアントをテストしているのでない限り、これらの選択を維持してください。グラフの残りはこのペアリングに調整されています。
ビデオ設定#
解像度と持続時間は軽量な画像スキャフォールドとLengthコントロールで設定されます。グラフは画像サイズを読み取り、作業解像度にスケーリングし、その値をビデオ潜在クリエーターに転送します。LTXモデルにはストライド制約があります。32ストライドパターンに従うサイズと、モデルのフレームケイデンスに合わせた長さを選択してください。グラフは不正な値を最も近い有効なものに優しくスナップしますが、最初から有効なサイズを選択すると、最良の構成が得られます。
フレームレート#
2つの小さなコントロールが、コンディショニングと最終エンコーディングの両方のFPSを設定します: Frame Rate(int) (#141) と Frame Rate(float) (#140)。パイプライン全体でモーションタイミングとオーディオアライメントが一貫するように、同じに保ちます。スムーズな動きを望む場合は映画的なレートを選択するか、ソーシャルフォーマットをターゲットにする場合はプラットフォームのデフォルトに合わせます。
潜在#
EmptyLTXVLatentVideo (#121) はビデオ潜在を初期化し、LTXVEmptyLatentAudio (#119) はオーディオを同様に初期化します。LTXVConcatAVLatent (#122) はそれらを単一のAV潜在にマージし、テキストガイダンスが両方のモダリティを一緒に導くことができます。LTXVConditioning (#120) はポジティブおよびネガティブコンディショニングを添付し、LTXVCropGuides (#115) は潜在の空間レイアウトにガイダンスを適応させ、より信頼性のあるフレーミングを提供します。
サンプラーステージ1#
このステージはRandomNoise (#151)、KSamplerSelect (#144)、およびLTX対応のLTXVScheduler (#112) とCFGGuider (#139) を使用して初期のAV潜在を作成します。スケジューラーは、時間的安定性とプロンプトへの忠実性をバランスするためにLTXに合わせて調整されています。より多くのバリエーションを望む場合はノイズシードを変更し、スクリプトへの確実な適合を望む場合は、時間的一貫性を維持するサンプラーを支持します。
モデル (LoRA)#
LoraLoaderModelOnly (#143) はLTX-2.3蒸留LoRAを適用してからリファインメントを行います。このアダプターは、モーションの一貫性を失うことなくテクスチャポリッシュとスタイルの忠実性を微妙に改善します。特に肌、布、スペキュラーハイライトで最も顕著です。
アップスケールサンプリング (2×)#
LTXVLatentUpsampler (#130) は読み込まれたLatentUpscaleModelLoader (#114) とベースVAEを使用して潜在空間で2×空間アップスケールを実行します。アップスケーリングがデコード前に行われるため、時間的スムーズさを保ちながら細かい空間ディテールを得ることができます。アップスケールされたビデオとオーディオ潜在はLTXVConcatAVLatent (#129) で再び結合され、リファインメントパスに進みます。
サンプラーステージ2 (2×)#
2回目のパスはRandomNoise (#127)、KSamplerSelect (#145)、およびManualSigmasスケジュール (#113) をCFGGuider (#116) の下で使用してアップスケールされた潜在をリファインします。このステージは、微細なディテールとエッジのシャープネスが最終化される場所です。LoRAがアクティブであり、プロンプトがテクスチャとライティングについて具体的であるときに最も効果的です。
デコードと出力#
LTXVSeparateAVLatent (#135) はリファインされた潜在を分割し、VAEDecodeTiled (#137) がフレームを再構築し、LTXVAudioVAEDecode (#138) がオーディオを復元します。CreateVideo (#133) は選択されたFPSでフレームとオーディオをマクシングし、トップレベルのSaveVideoノードがワークフローのビデオフォルダにMP4を書き込みます。結果は、LTX 2.3 ComfyUIパイプライン全体で生成された、クリーンで共有準備が整ったファイルです。
Comfyui LTX 2.3 ComfyUIワークフローの主要ノード#
TextGenerateLTX2Prompt(#149): 単純な記述をモーション、視覚属性、およびオーディオをカバーする構造化プロンプトに変換します。ストーリービートやペーシングを導くときは、ここでの言葉遣いを最初に調整してください。通常、サンプラー調整よりも大きな効果をもたらします。LTXVScheduler(#112): ノイズが時間と共にどのように除去されるかを形成するLTX特有のスケジューラーです。選択したサンプラーと慎重にペアリングして、時間的安定性とプロンプトの忠実性をバランスさせます。LTXVLatentUpsampler(#130): 潜在空間で直接2×空間アップスケールを行い、モーションの連続性を保ちながらシャープなディテールを追加します。デコード後のアップスケーラーに頼ることなく、シャープな結果を求めるときに使用します。LoraLoaderModelOnly(#143): LTX-2.3蒸留LoRAをリファインメントに適用します。スタイルコントロールを強化するために影響を増やし、ベースモデルの広範な外観を求める場合は減らします。CreateVideo(#133): 選択されたFPSで生成されたオーディオとデコードされたフレームをマクシングし、タイミングとリップシンクを維持します。FPSを変更する場合は、両方のフレームレートコントロールを一致させてください。
オプションの追加機能#
- プロンプトのヒント: 時間をかけてアクションを説明し、主要な視覚要素をリストし、期待されるサウンドやダイアログを指定します。明確で簡潔な表現は、LTX-2.3エンコーダーに最良の信号を提供します。
- 次元と長さ: 32ストライドのサイズと、モデルのフレームケイデンスを尊重する長さを好みます。グラフは近似値を自動的にスナップしますが、有効な入力が構成を改善し、微妙なジッターを減少させます。
- 迅速な反復:
RandomNoiseシードを実行間で変更して、同じプロンプトと設定を維持しながらバリエーションを探ります。 - モデルの切り替え: デフォルトはLTX-2.3 22BとGemma 3 12B IT、2×空間アップスケーラーに調整されています。各モデルがコンディショニングとデコードにどのように影響するかを理解している場合にのみモデルを交換してください。
謝辞#
このワークフローは、以下の作品とリソースを実装し、構築しています。LightricksのLTX-2.3モデルおよびEyeForAILabsのYouTubeチュートリアルに感謝し、その貢献とメンテナンスを承認します。詳細については、以下の元のドキュメントとリポジトリを参照してください。
リソース#
- Lightricks/LTX-2.3
- GitHub: Lightricks/LTX-2
- Hugging Face: Lightricks/LTX-2.3
- arXiv: 2601.03233
- EyeForAILabs/YouTube Tutorial
- Docs / Release Notes: YouTube Channel from @eyeforailabs
注: 参照されているモデル、データセット、およびコードの使用は、それぞれの著者およびメンテナーによって提供されるライセンスおよび条件に従います。
