
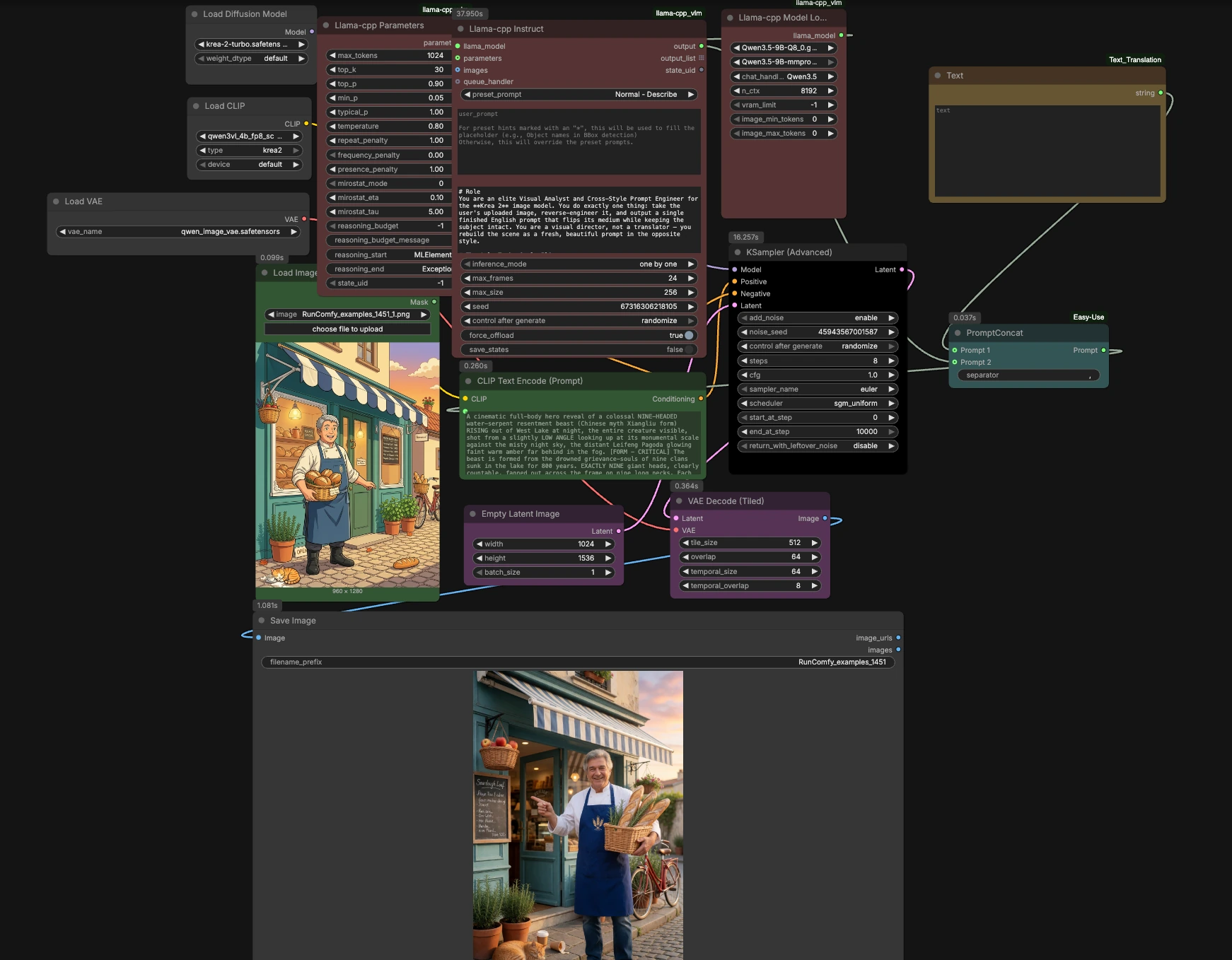






Krea 2 Turbo image-to-image ComfyUI ワークフロー#
このワークフローは、アップロードされた画像を反対の視覚媒体に変換しながら、被写体、色、ポーズ、フレーミング、シーンロジックを保持するスタイルフリップおよびリドローシステムです。スタイライズされたソース(アニメ、イラスト、3D、ペインティング)は、信じられる写真として再想像され、真の写真は鮮明な2Dアニメとして再解釈されます。Krea 2 Turboを中心に構築され、ローカルのllama.cppビジョンプロンプトステップ、Qwen3‑VLテキストエンコーディング、およびQwen Image VAEを備え、クリエイターに迅速で忠実で繰り返し可能な結果を提供し、RunComfy内での視覚的洗練とスタイル転送を実現します。迅速な反復のための再利用可能でプロダクションレディのKrea 2 Turbo image-to-image ComfyUIワークフローが必要な場合は、これが最適です。
Comfyui Krea 2 Turbo image-to-image ComfyUI ワークフローの主要モデル#
- Krea 2 Turbo huggingface.co/krea/Krea-2-Turbo。オープンウェイトのテキストから画像へのディフュージョントランスフォーマーで、少ステップ、高速推論に最適化されています。Turboは速度と一貫したプロンプトフォローを維持しながら、高い視覚品質とスタイル制御を提供します。
- Qwen3‑VL 4B テキストエンコーダー (Krea 2 エディション) huggingface.co/Comfy-Org/Krea-2。Krea 2に条件付けするために使用される言語からビジョンへの埋め込みを提供します。このリリースには、Krea対応のQwen3‑VLエンコーダーウェイトが含まれています。
- Qwen Image VAE huggingface.co/Comfy-Org/Krea-2。Krea 2が潜在空間とピクセル間を高忠実度で移動するために使用するオートエンコーダーです。
- Qwen 3.5 9B ビジョン-ラングエージモデル (GGUF) via llama.cpp github.com/mickeylan/ComfyUI-llama-cpp_vlm および github.com/ggml-org/llama.cpp。アップロードされた画像を分析し、具体的な視覚的事実をロックしながら、メディアを反転させる単一の洗練されたプロンプトを作成します。
Comfyui Krea 2 Turbo image-to-image ComfyUI ワークフローの使用方法#
ワークフローは、ローカルVLMで画像を分析し、クリーンな反対メディアプロンプトを生成し、Krea 2用にエンコードし、Krea 2 Turboで再描画します。パイプラインは入力から出力までの5つのステージに編成されており、制御のためのいくつかのオプションのタッチがあります。
1) 画像のアップロードと分析#
まず、画像を LoadImage (#128) にドロップします。画像は llama_cpp_model_loader (#127) と llama_cpp_instruct_adv (#125) にフィードされ、ローカルQwenファミリービジョンラングエージモデルがllama.cppを通じて実行されます。慎重に作成された system_prompt が、VLMに被写体のアイデンティティ、正確な色、構図、カメラロジックを保持しながらメディアを反転させるよう指示します:スタイライズされたソースは写真になり、本物の写真は鮮やかな2Dアニメになります。出力は、Krea 2用の単一の自然言語プロンプトです。
2) 生成プロンプトの組み立て#
Text (#130) を使用して、プロジェクトタグ、ブランド用語、またはレンズノートなど、追加したい短いガイダンスを追加します。easy promptConcat (#129) は、手動のテキストとVLMが作成した説明を1つの一貫したプロンプトにマージします。追加は最小限に抑えてください。VLMはすでにすべての可視要素を正確に記述しているため、Krea 2 Turbo image-to-image ComfyUI ワークフローが忠実であることを維持できます。
3) Krea 2用のテキストをエンコード#
CLIPLoader (#106) は、Krea 2にバンドルされたQwen3‑VL 4Bテキストエンコーダーをロードし、CLIPTextEncode (#5) が最終プロンプトを条件付けに変換します。このエンコーダーは、Krea 2のトークナイザーとペアリングするように設計されており、詳細なシーンセマンティクス、カラー記述、およびカメラの手がかりを保持します。ConditioningZeroOut (#124) は意図的に空のネガティブブランチを提供し、これは一般的にKrea 2 Turboの蒸留されたガイダンス動作に適しています。
4) Krea 2 Turboで生成#
UNETLoader (#107) はKrea 2 Turboチェックポイントをロードし、KSamplerAdvanced (#12) に渡します。EmptyLatentImage (#10) はキャンバスサイズを設定します。生成したい幅と高さを選択します。Krea 2 Turboは、少ステップサンプリングで非常に低いまたはゼロの分類器フリーガイダンスで構築されているため、ゼロCFG付近から開始し、より厳密なプロンプト従いが必要な場合のみ引き上げてください。サンプラーとスケジューラーが協力して、プロンプトのロックされた色と構図を尊重した高速でシャープな結果を提供します。
5) 出力をデコードして保存#
VAELoader (#105) は、VAEDecodeTiled (#123) によって、VRAMフレンドリーなタイル化で大きな画像のために潜在からピクセルを再構築するために使用されるQwen Image VAEを提供します。SaveImage (#35) は最終レンダーを書き込みます。結果はクリーンで忠実な反転メディアのリドローであり、レビューまたはもう一つのクイックパスの準備が整います。
Comfyui Krea 2 Turbo image-to-image ComfyUI ワークフローの主要ノード#
llama_cpp_instruct_adv (#125)#
このノードはスタイルフリップの頭脳です。system_prompt を調整するのは、フリップポリシーや保持ルールを変更したい場合のみです。デフォルトはアイデンティティ、ポーズ、フレーミング、正確な色を保持するように調整されています。preset_prompt と custom_prompt を使用して、写真出力のためのレンズの命名やアニメのための優しいパレットノートの追加など、小さな調整を行います。出力は一つの流暢な段落にとどめてください。Krea 2は自然言語に最もよく反応します。
KSamplerAdvanced (#12)#
速度、シャープさ、従いを制御します。Krea 2 Turboは少ステップサンプリングで低またはゼロの cfg に対して蒸留されているため、最小限のガイダンスから始め、プロンプト従いをより厳密にする必要がある場合にのみ引き上げます。sampler_name と scheduler を切り替え、シャープなエッジと超滑らかなグラデーションの間の異なるトレードオフを好む場合は変更します。noise_seed をロックして、一貫したバリエーションを望む場合。
EmptyLatentImage (#10)#
出力サイズとバッチを設定します。意図したフレーミングに合ったアスペクト比と解像度を選択します。VLMプロンプトは構図を運ぶため、後でのクロップ変更を避けてください。大きなフレームは、メモリ効率を維持するためにタイル化されたデコードステージから利益を得ます。
ConditioningZeroOut (#124)#
デザインによってネガティブプロンプトを無効にし、これは一般的にKrea 2 Turboに適しています。プロジェクトが従来のネガティブプロンプティングを必要とする場合は、これを2つ目の CLIPTextEncode に置き換え、KSamplerAdvanced (#12) のネガティブ入力に供給します。
VAEDecodeTiled (#123)#
高解像度でのVRAM使用を安定させるためにタイル化されたデコードを実行します。極端なサイズでシームが見られる場合は、重なりを優しく増やします。メモリが厳しい場合は、タイルの粒度を増やします。
オプションのエクストラ#
- スタイライズコントロールのために、Comfy-OrgリパックからKrea-2 LoRAをロードし、ComfyUIで他のLoRAと同様に適用できます huggingface.co/Comfy-Org/Krea-2。Kreaは、LoRAをRawでトレーニングし、Turboで適用することを推奨しています。詳細は公式リポジトリを参照してください github.com/krea-ai/krea-2。
- 手動編集は短く保ちます。Krea 2 Turbo image-to-image ComfyUI ワークフローは、正確な色相とシーンロジックを保持するよう設計されており、長い手動プロンプトはVLMのカラーロックを意図せずに上書きする可能性があります。
- 最速の反復のために、中程度の解像度で作業し、構図を確認し、満足した後に反転用にアップスケールまたは解像度を引き上げます。
謝辞#
このワークフローは、以下の作品とリソースを実装し、構築しています。我々は、RunningHub に Image-to-Imageワークフローソース、Krea AI に Krea 2とKrea-2-Turbo、および Comfy-Orgとmickeylan に ComfyUI Krea 2ウェイトとComfyUI llama-cpp VLMカスタムノード の貢献と保守に感謝します。権威ある詳細については、以下にリンクされた元のドキュメントとリポジトリを参照してください。
リソース#
- RunningHub/Image-to-Image Workflow
- ドキュメント / リリースノート: RunningHub post
- krea-ai/Krea 2
- GitHub: krea-ai/krea-2
- Krea/Krea-2-Turbo
- Hugging Face: krea/Krea-2-Turbo
- Comfy-Org/Krea-2
- Hugging Face: Comfy-Org/Krea-2
- mickeylan/ComfyUI-llama-cpp_vlm
- GitHub: mickeylan/ComfyUI-llama-cpp_vlm
注: 参照されたモデル、データセット、およびコードの使用は、それぞれの著者および管理者が提供するライセンスおよび条件に従う必要があります。