

IDM-VTONは、"Improving Diffusion Models for Authentic Virtual Try-on in the Wild"の略で、わずかな入力で衣服をリアルにバーチャル試着できる革新的な拡散モデルです。IDM-VTONの特徴は、衣服の独自のディテールとアイデンティティを保持しながら、非常に本格的なバーチャル試着結果を生成する能力にあります。
1. IDM-VTONの理解#
IDM-VTONは、バーチャル試着用に特別に設計された拡散モデルです。使用するには、人の表現と試着したい衣服を用意するだけです。IDM-VTONはその魔法を発揮し、人が実際に衣服を着ているように見える結果を描写します。衣服の忠実性と本物らしさのレベルは、以前の拡散ベースのバーチャル試着方法を超えています。
2. IDM-VTONの内部構造#
IDM-VTONはどのようにしてリアルなバーチャル試着を実現するのでしょうか?その秘密は、衣服の入力のセマンティクスをエンコードする2つの主要なモジュールにあります。
- 最初のモジュールはイメージプロンプトアダプタ、略してIP-Adapterです。この賢いコンポーネントは、衣服の高次元のセマンティクス、つまり外見を定義する主要な特性を抽出します。そして、この情報をメインのUNet拡散モデルのクロスアテンション層に融合させます。
- 二つ目のモジュールはGarmentNetと呼ばれるParallel UNetです。これは衣服の低次元の特徴、つまりそれをユニークにする細かいディテールをエンコードする役割を持っています。これらの特徴は、メインのUNetのセルフアテンション層に融合されます。
しかし、それだけではありません!IDM-VTONは、衣服と人の入力のための詳細なテキストプロンプトも利用します。これらのプロンプトは、最終的なバーチャル試着結果の本物らしさを高めるための追加のコンテキストを提供します。
3. ComfyUIでのIDM-VTONの活用#
3.1 主役: IDM-VTONノード#
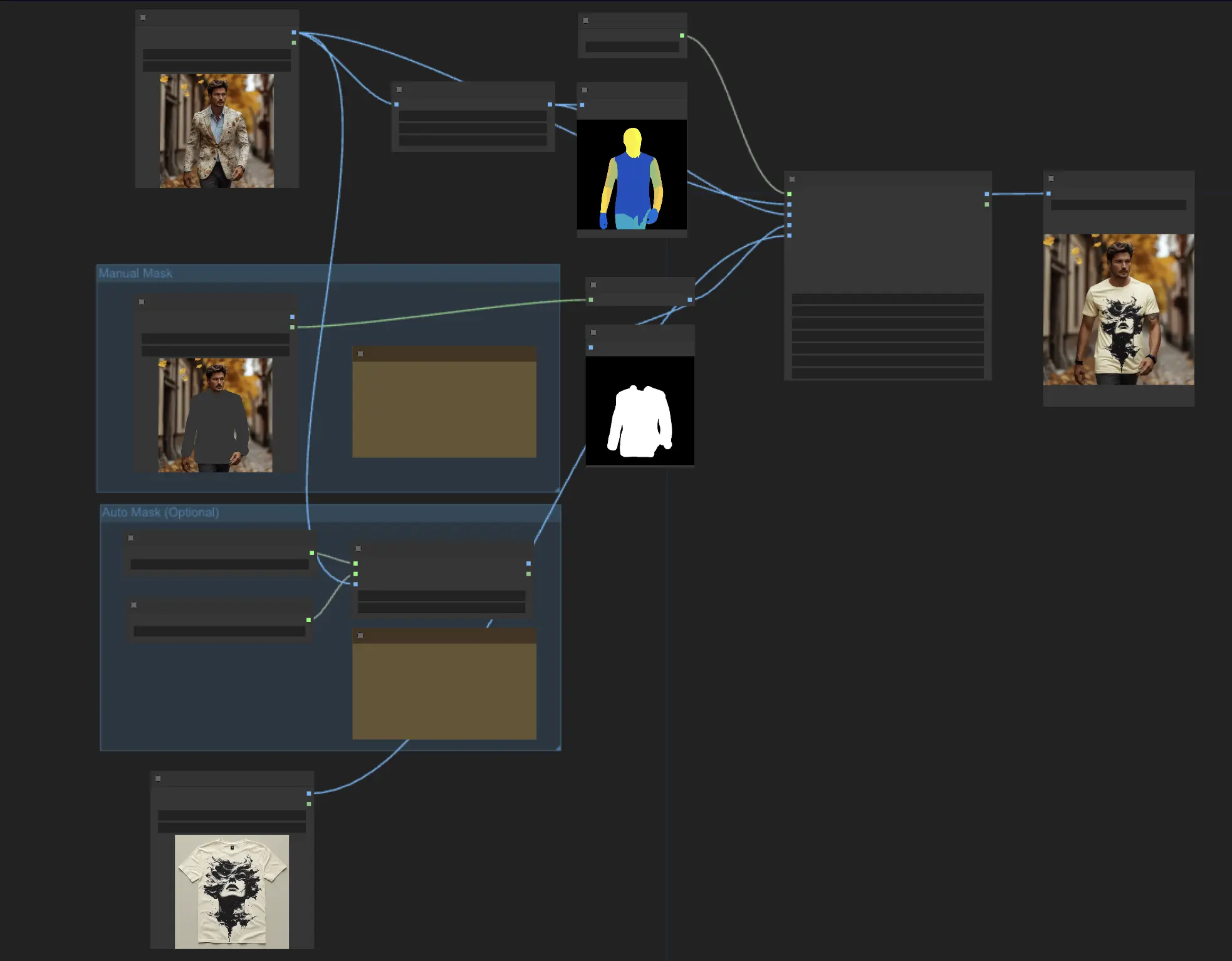
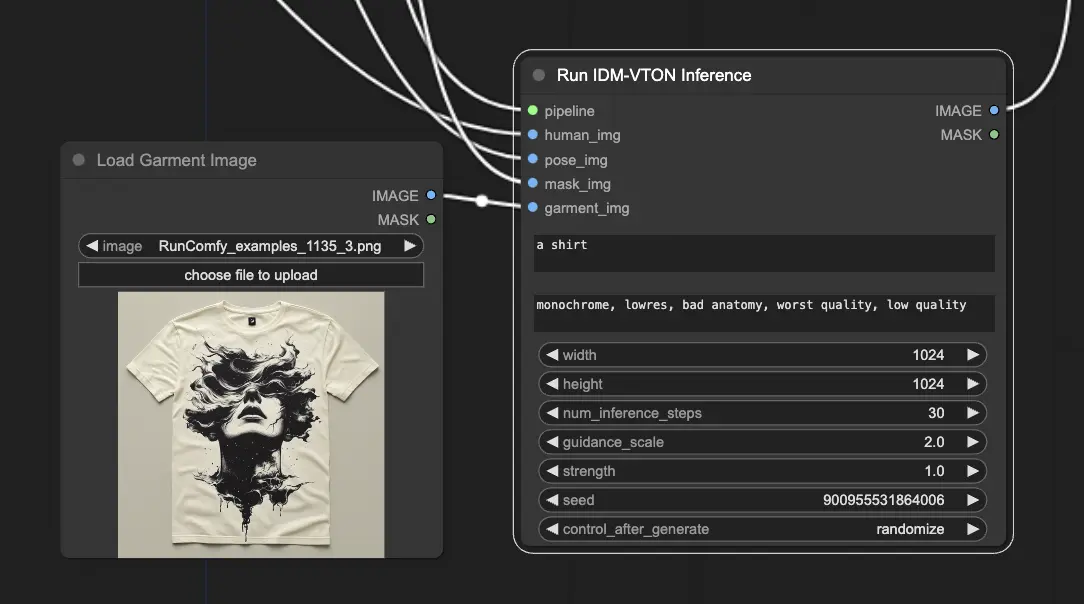
ComfyUIでは、"IDM-VTON"ノードがIDM-VTON拡散モデルを実行し、バーチャル試着の出力を生成するパワーハウスです。
IDM-VTONノードがその魔法を発揮するには、いくつかの重要な入力が必要です:
- Pipeline: 仮想試着プロセス全体を駆動する読み込まれたIDM-VTON拡散パイプライン。
- Human Input: 衣服をバーチャルに試着する人の画像。
- Pose Input: IDM-VTONが人のポーズと体型を理解するのに役立つ、前処理されたDensePose表現。
- Mask Input: 人の入力のうち、衣服である部分を示すバイナリマスク。このマスクは適切な形式に変換する必要があります。
- Garment Input: バーチャルに試着する衣服の画像。
3.2 準備を整える#
IDM-VTONノードを稼働させるためには、いくつかの準備ステップがあります:
- 人の画像の読み込み: LoadImageノードを使用して人の画像を読み込みます。 <img src="https://cdn.runcomfy.net/workflow_assets/1135/readme01.webp" alt="IDM-VTON" width="500" />
- ポーズ画像の生成: 人の画像をDensePosePreprocessorノードに通し、IDM-VTONが必要とするDensePose表現を計算します。 <img src="https://cdn.runcomfy.net/workflow_assets/1135/readme02.webp" alt="IDM-VTON" width="500" />
- マスク画像の取得: 衣服マスクを取得する方法は2つあります: <img src="https://cdn.runcomfy.net/workflow_assets/1135/readme03.webp" alt="IDM-VTON" width="500" />
a. 手動マスキング (推奨)
- 読み込まれた人の画像を右クリックし、"Open in Mask Editor"を選択します。
- マスクエディタUIで、衣服の領域を手動でマスクします。
b. 自動マスキング
- GroundingDinoSAMSegmentノードを使用して衣服を自動的にセグメントします。
- ノードに衣服のテキスト説明 ("t-shirt"など) をプロンプトします。
どちらの方法を選んでも、取得したマスクはMaskToImageノードを使用して画像に変換し、IDM-VTONノードの"Mask Image"入力に接続する必要があります。
- 衣服画像の読み込み: 衣服の画像を読み込むために使用されます。
IDM-VTONモデルをより深く理解するために、オリジナルペーパー"Improving Diffusion Models for Authentic Virtual Try-on in the Wild"をお見逃しなく。そして、ComfyUIでIDM-VTONを使用することに興味がある方は、専用ノードをこちらでチェックしてください。これらの素晴らしいリソースを提供してくださった研究者と開発者の皆様に心より感謝いたします。

